02-微服务平台落地
- 0.1. 服务发布与引用
- 0.2. 注册中心
- 0.3. RPC框架
- 0.4. 监控系统
- 0.5. 服务追踪系统
- 0.6. 服务治理
- 0.7. 服务端故障处理
- 0.8. 服务调用失败处理手段
- 0.9. 管理服务配置
- 0.10. 微服务治理平台
0.1. 服务发布与引用
以XML配置方式发布和引用服务。
0.1.1. 一号坑
一个服务包含了多个接口,可能有上行接口也可能有下行接口,每个接口都有超时控制以及是否重试等配置,如果有多个服务消费者引用这个服务,是不是每个服务消费者都必须在服务引用配置文件中定义?
解决方案:服务发布预定义配置,即使服务消费者没有在服务引用配置文件中定义,也能继承服务提供者的定义。
0.1.2. 二号坑
一个服务提供者发布的服务有上百个方法,并且每个方法都有各自的超时时间、重试次数等信息。服务消费者引用服务时,完全继承了服务发布预定义的各项配置。这种情况下,服务提供者所发布服务的详细配置信息都需要存储在注册中心中,这样服务消费者才能在实际引用时从服务发布预定义配置中继承各种配置。
当服务提供者发生节点变更,尤其是在网络频繁抖动的情况下,所有的服务消费者都会从注册中心拉取最新的服务节点信息,就包括了服务发布配置中预定的各项接口信息,这个信息不加限制的话可能达到 1M 以上,如果同时有上百个服务消费者从注册中心拉取服务节点信息,在注册中心机器部署为百兆带宽的情况下,很有可能会导致网络带宽打满的情况发生。
解决方案:服务引用定义配置。
0.1.3. 三号坑
服务配置升级的过程。由于引用服务的服务消费者众多,并且涉及多个部门,升级步骤就显得异常重要,通常可以按照下面步骤操作。
- 各个服务消费者在服务引用配置文件中添加服务详细信息。
- 服务提供者升级两台服务器,在服务发布配置文件中删除服务详细信息,并观察是否所有的服务消费者引用时都包含服务详细信息。
- 如果都包含,说明所有服务消费者均完成升级,那么服务提供者就可以删除服务发布配置中的服务详细信息。
- 如果有不包含服务详细信息的服务消费者,排查出相应的业务方进行升级,直至所有业务方完成升级。
0.2. 注册中心
落地注册中心的过程中,需要解决一些列问题,包括:
- 如何存储服务信息
- 如何注册节点
- 如何反注册
- 如何查询节点信息
- 如何订阅服务变更
0.2.1. 存储的服务信息
服务信息,通常用JSON字符串来存储,包括:
- 节点信息(IP和端口)
- 请求失败时重试的次数
- 请求结果是否压缩
服务一般会分成多个不同的分组,每个分组的目的不同。一般来说有下面几种分组方式:
- 核心与非核心,从业务的核心程度来分
- 机房,从机房的维度来分
- 线上环境与测试环境,从业务场景维度来区分
所以注册中心存储的服务信息一般包含三部分内容:分组、服务名以及节点信息,节点信息又包括节点地址和节点其他信息。
具体存储的时候,一般是按照“服务 - 分组 - 节点信息”三层结构来存储,可以用下图来描述。Service 代表服务的具体分组,Cluster 代表服务的接口名,节点信息用 KV 存储。
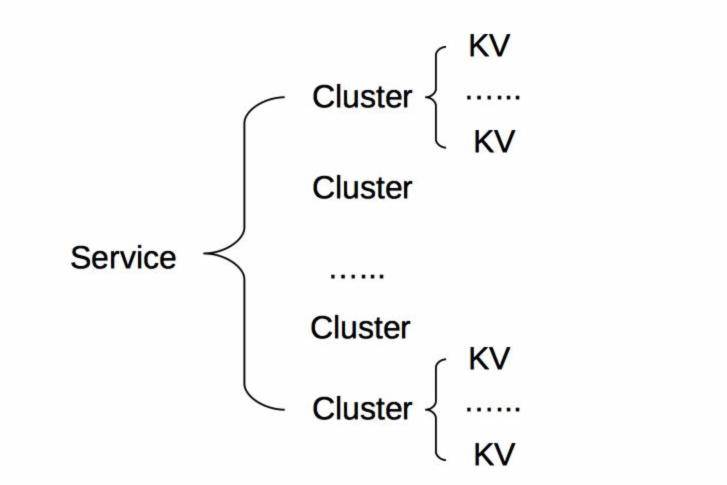
0.2.2. 注册中心工作流程
注册中心具体是工作包括四个流程:
- 服务提供者注册流程
- 服务提供者反注册流程
- 服务消费者查询流程
- 服务消费者订阅变更流程
0.2.2.1. 注册节点
- 首先查看要注册的节点是否在白名单内?如果不在就抛出异常,在的话继续下一步
- 其次要查看注册的 Cluster(服务的接口名)是否存在?如果不存在就抛出异常,存在的话继续下一步
- 然后要检查 Service(服务的分组)是否存在?如果不存在则抛出异常,存在的话继续下一步
- 最后将节点信息添加到对应的 Service 和 Cluster 下面的存储中
0.2.2.2. 反注册
- 查看 Service(服务的分组)是否存在,不存在就抛出异常,存在就继续下一步
- 查看 Cluster(服务的接口名)是否存在,不存在就抛出异常,存在就继续下一步
- 删除存储中 Service 和 Cluster 下对应的节点信息
- 更新 Cluster 的 sign 值
0.2.2.3. 查询节点信息
- 首先从 localcache(本机内存)中查找,如果没有就继续下一步。
- 接着从 snapshot(本地快照)中查找,如果没有就继续下一步。
这里为什么服务消费者要把服务信息存在本机内存呢?
主要是因为服务节点信息并不总是时刻变化的,并不需要每一次服务调用都要调用注册中心获取最新的节点信息,只需要在本机内存中保留最新的服务提供者的节点列表就可以。
这里为什么服务消费者要在本地磁盘存储一份服务提供者的节点信息的快照呢?
这是因为服务消费者同注册中心之间的网络不一定总是可靠的,服务消费者重启时,本机内存中还不存在服务提供者的节点信息,如果此时调用注册中心失败,那么服务消费者就拿不到服务节点信息了,也就没法调用了。本地快照就是为了防止这种情况的发生,即使服务消费者重启后请求注册中心失败,依然可以读取本地快照,获取到服务节点信息。
0.2.2.4. 订阅服务变更
- 服务消费者从注册中心获取了服务的信息后,就订阅了服务的变化,会在本地保留 Cluster 的 sign 值
- 服务消费者每隔一段时间,调用
getSign()函数,从注册中心获取服务端该 Cluster 的 sign 值,并与本地保留的 sign 值做对比,如果不一致,就从服务端拉取新的节点信息,并更新 localcache 和 snapshot
0.2.3. 注册中心的坑
0.2.3.1. 多注册中心
服务消费者同一个注册中心交互是最简单的。但是不可避免的是,服务消费者可能订阅了多个服务,多个服务只在不同的注册中心里有记录。这样的话,就要求服务消费者要具备在启动时,能够从多个注册中心订阅服务的能力。
- 对于服务消费者来说,要能够同时从多个注册中心订阅服务
- 对于服务提供者来说,要能够同时向多个注册中心注册服务
0.2.3.2. 并行订阅服务
通常一个服务消费者订阅了不止一个服务,一个服务消费者订阅了几十个不同的服务,每个服务都有自己的方法列表以及节点列表。
服务消费者在服务启动时,会加载订阅的服务配置,调用注册中心的订阅接口,获取每个服务的节点列表并初始化连接。
采用串行订阅的方式,每订阅一个服务,服务消费者调用一次注册中心的订阅接口,获取这个服务的节点列表并初始化连接,总共需要执行几十次这样的过程。
在某些服务节点的初始化连接过程中,出现连接超时的情况,后续所有的服务节点的初始化连接都需要等待它完成,导致服务消费者启动变慢,最后耗费了将近五分钟时间来完成所有服务节点的初始化连接过程。
采用并行订阅的方式,每订阅一个服务就单独用一个线程来处理,这样的话即使遇到个别服务节点连接超时,其他服务节点的初始化连接也不受影响,最慢也就是这个服务节点的初始化连接耗费的时间,最终所有服务节点的初始化连接耗时控制在了 30 秒以内。
0.2.3.3. 批量反注册服务
通常一个服务提供者节点提供不止一个服务,所以注册和反注册都需要多次调用注册中心。在与注册中心的多次交互中,可能由于网络抖动、注册中心集群异常等原因,导致个别调用失败。
对于注册中心来说:
- 偶发的注册调用失败对服务调用基本没有影响,其结果顶多就是某一个服务少了一个可用的节点
- 偶发的反注册调用失败会导致不可用的节点残留在注册中心中,变成“僵尸节点”,但服务消费者端还会把它当成“活节点”,继续发起调用,最终导致调用失败
定时去清理注册中心中的“僵尸节点”。
通过优化反注册逻辑,对于下线机器、节点销毁的场景,调用注册中心提供的批量反注册接口,一次调用就可以把该节点上提供的所有服务同时反注册掉,从而避免了“僵尸节点”的出现。
0.2.3.4. 服务变更信息增量更新
服务消费者端启动时:
- 查询订阅服务的可用节点列表做初始化连接
- 订阅服务的变更,每隔一段时间从注册中心获取最新的服务节点信息标记 sign,并与本地保存的 sign 值作比对,如果不一样,就会调用注册中心获取最新的服务节点信息
一般情况下,这个过程是没问题的,但是在网络频繁抖动时,服务提供者上报给注册中心的心跳可能会一会儿失败一会儿成功,注册中心就会频繁更新服务的可用节点信息,导致服务消费者频繁从注册中心拉取最新的服务可用节点信息,严重时可能产生网络风暴,导致注册中心带宽被打满。
为了减少服务消费者从注册中心中拉取的服务可用节点信息的数据量,这个时候可以通过增量更新(即版本号)的方式,注册中心只返回变化的那部分节点信息,尤其在只有少数节点信息变更时,可以大大减少服务消费者从注册中心拉取的数据量,从而最大程度避免产生网络风暴。
0.2.4. 注册中心选型
当下主流的服务注册与发现的解决方案,主要有两种:
- 应用内注册与发现:注册中心提供服务端和客户端的 SDK,业务应用通过引入注册中心提供的 SDK,通过 SDK 与注册中心交互,来实现服务的注册和发现
- 应用外注册与发现:业务应用本身不需要通过 SDK 与注册中心打交道,而是通过其他方式与注册中心交互,间接完成服务注册与发现
0.2.4.1. 应用内
采用应用内注册与发现的方式,最典型的案例要属 Netflix 开源的 Eureka,官方架构图如下。
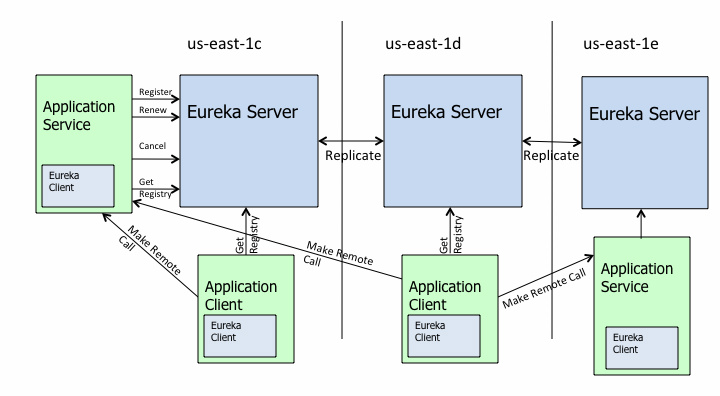
主要由三个重要的组件组成:
- Eureka Server:注册中心的服务端,实现了服务信息注册、存储以及查询等功能
- 服务端的 Eureka Client:集成在服务端的注册中心 SDK,服务提供者通过调用 SDK,实现服务注册、反注册等功能
- 客户端的 Eureka Client:集成在客户端的注册中心 SDK,服务消费者通过调用 SDK,实现服务订阅、服务更新等功能
0.2.4.2. 应用外
采用应用外方式实现服务注册和发现,最典型的案例是开源注册中心 Consul,它的架构图如下。
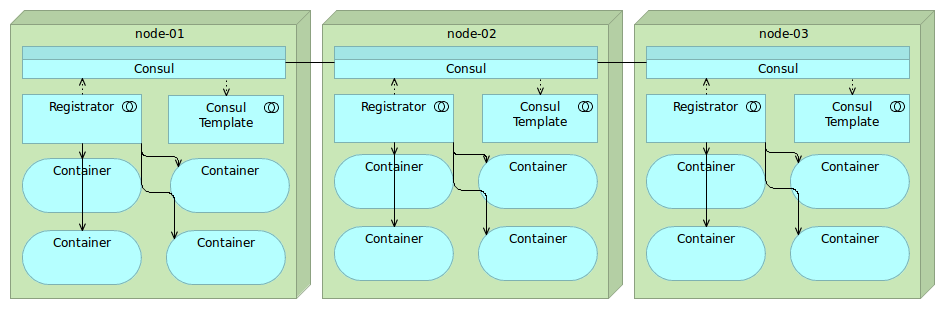
Consul 实现应用外服务注册和发现主要依靠三个重要的组件:
- Consul:注册中心的服务端,实现服务注册信息的存储,并提供注册和发现服务
- Registrator:一个开源的第三方服务管理器项目,它通过监听服务部署的 Docker 实例是否存活,来负责服务提供者的注册和销毁
- Consul Template:定时从注册中心服务端获取最新的服务提供者节点列表并刷新 LB 配置(比如 Nginx 的 upstream),这样服务消费者就通过访问 Nginx 就可以获取最新的服务提供者信息
| 解决方案 | 开源项目 | 应用场景 |
|---|---|---|
| 应用内 | eureka | 适用于服务提供者和服务消费者同属于一个技术体系 |
| 应用外 | consul | 适合服务提供者和服务消费者采用了不同技术体系的业务场景 |
比如服务提供者提供的是 C++ 服务,而服务消费者是一个 Java 应用,这时候采用应用外的解决方案就不依赖于具体一个技术体系。
对于容器化后的云应用来说,一般不适合采用应用内 SDK 的解决方案,因为这样会侵入业务,而应用外的解决方案正好能够解决这个问题。
0.2.4.3. 选型考虑的问题
除了要考虑是采用应用内注册还是应用外注册的方式以外,还有两个最值得关注的问题,一个是高可用性,一个是数据一致性。
0.2.4.3.1. 高可用
注册中心作为服务提供者和服务消费者之间沟通的纽带,它的高可用性十分重要。实现高可用性的方法主要有两种:
- 集群部署,通过部署多个实例组成集群来保证高可用性,这样的话即使有部分机器宕机,将访问迁移到正常的机器上就可以保证服务的正常访问。
- 多 IDC 部署,就是部署在不止一个机房,这样能保证即使一个机房因为断电或者光缆被挖断等不可抗力因素不可用时,仍然可以通过把请求迁移到其他机房来保证服务的正常访问。
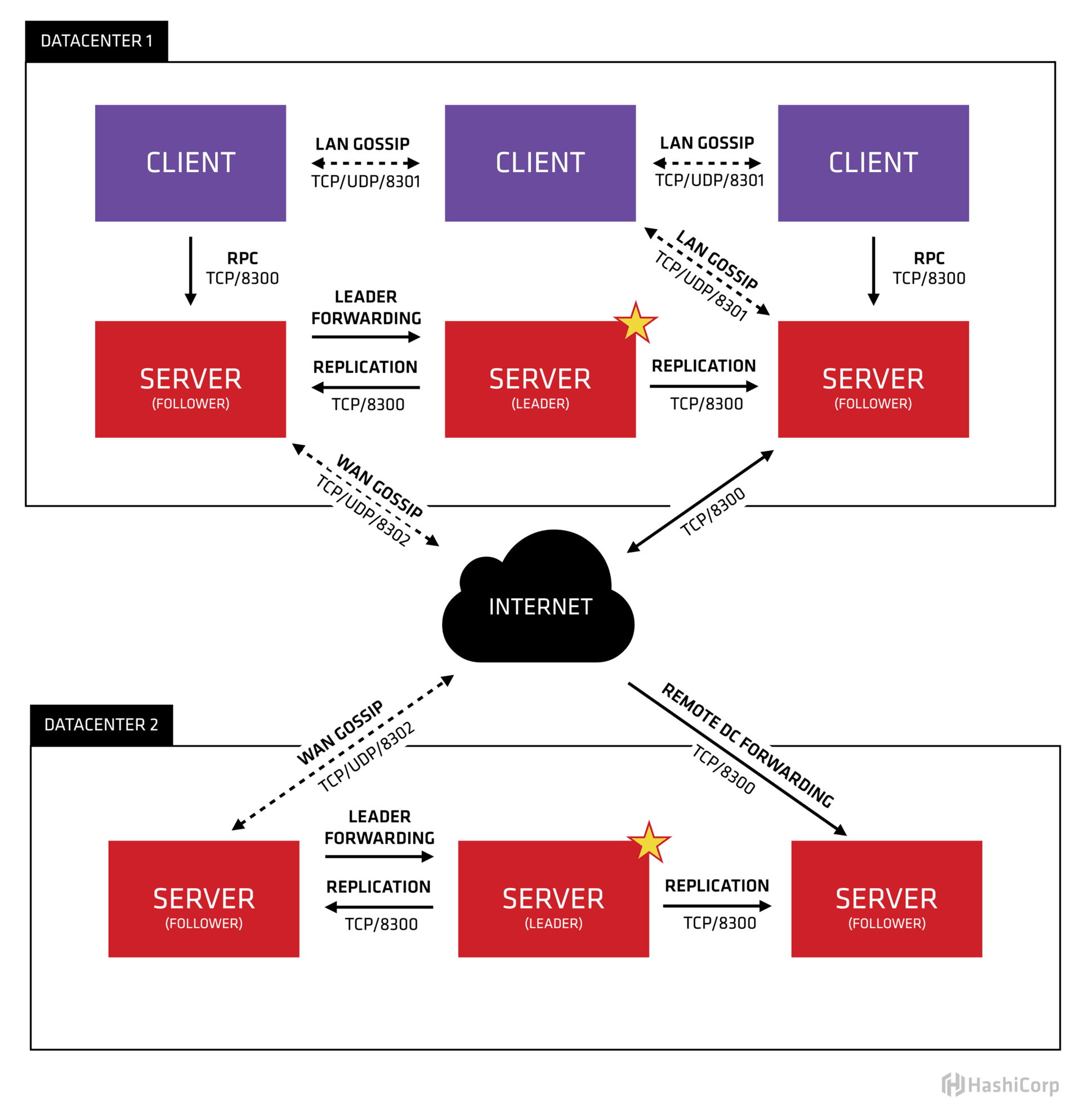
Consul 为例,通过这两种方法来保证注册中心的高可用性:
- 一方面,在每个数据中心内都有多个注册中心 Server 节点可供访问
- 另一方面,还可以部署在多个数据中心来保证多机房高可用性
0.2.4.3.2. 数据一致性
为了保证注册中心的高可用性,注册中心的部署都采用集群部署,并且还通常部署在不止一个数据中心,这样的话就会引出另一个问题,多个数据中心之间如何保证数据一致?
这里就涉及分布式系统中著名的 CAP 理论,即同时满足一致性、可用性、分区容错性这三者是不可能的,其中:
- C(Consistency)代表一致性
- A(Availability)代表可用性
- P(Partition Tolerance)代表分区容错性
在一个分布式系统里面,包含了多个节点,节点之间通过网络连通在一起。正常情况下,通过网络,从一个节点可以访问任何别的节点上的数据。
分区:出现网络故障,导致整个网络被分成了互不连通的区域。
分区容错性:一旦出现分区,那么一个区域内的节点就没法访问其他节点上的数据了,最好的办法是把数据复制到其他区域内的节点,这样即使出现分区,也能访问任意区域内节点上的数据。
一致性:把数据复制到多个节点就可能出现数据不一致的情况。
可用性:要保证一致性,就必须等待所有节点上的数据都更新成功才可用。
总的来说,就是数据节点越多,分区容错性越高,但数据一致性越难保证。为了保证数据一致性,又会带来可用性的问题。
注册中心采用分布式集群部署,也面临着 CAP 的问题,所以注册中心大致可分为两种:
| 类型 | 说明 | 例子 |
|---|---|---|
| CP 型 | 牺牲可用性来保证数据强一致性 | ZooKeeper,etcd,Consul |
| AP 型 | 牺牲一致性来保证可用性 | Eureka |
- ZooKeeper 集群内只有一个 Leader,而且在 Leader 无法使用的时候通过 Paxos 算法选举出一个新的 Leader。这个 Leader 的目的就是保证写信息的时候只向这个 Leader 写入,Leader 会同步信息到 Followers,这个过程就可以保证数据的强一致性。但如果多个 ZooKeeper 之间网络出现问题,造成出现多个 Leader,发生脑裂的话,注册中心就不可用了。
- etcd 和 Consul 集群内都是通过 raft 协议来保证强一致性,如果出现脑裂的话, 注册中心也不可用。
- Eureka 不用选举一个 Leader,每个 Eureka 服务器单独保存服务注册地址,因此有可能出现数据信息不一致的情况。但是当网络出现问题的时候,每台服务器都可以完成独立的服务。
对于注册中心来说,最主要的功能是服务的注册和发现,在网络出现问题的时候,可用性的需求要远远高于数据一致性。即使因为数据不一致,注册中心内引入了不可用的服务节点,也可以通过其他措施来避免,比如客户端的快速失败机制等,只要实现最终一致性,对于注册中心来说就足够了。因此,选择 AP 型注册中心,一般更加合适。
0.2.5. 总结
在选择开源注册中心解决方案的时候,要看业务的具体场景。
- 如果业务体系都采用 Java 语言的话,Netflix 开源的 Eureka 是一个不错的选择,并且它作为服务注册与发现解决方案,能够最大程度的保证可用性,即使出现了网络问题导致不同节点间数据不一致,你仍然能够访问 Eureka 获取数据。
- 如果你的业务体系语言比较复杂,Eureka 也提供了 Sidecar 的解决方案;也可以考虑使用 Consul,它支持了多种语言接入,包括 Go、Python、PHP、Scala、Java,Erlang、Ruby、Node.js、.NET、Perl 等。
- 如果你的业务已经是云原生的应用,可以考虑使用 Consul,搭配 Registrator 和 Consul Template 来实现应用外的服务注册与发现。
0.3. RPC框架
一个完整的 RPC 框架主要有三部分组成:
- 通信框架
- 通信协议
- 序列化和反序列化格式
业界应用比较广泛的开源 RPC 框架主要分为两类:
限定语言平台绑定的开源 RPC 框架:
名称 公司 年代 语言 Dubbo 阿里巴巴 2011 Java Motan 微博 2016 Java Tars 腾讯 2017 C++ Spring Cloud Pivotal 2014 Java
从长远来看,支持多语言是 RPC 框架未来的发展趋势。正是基于此判断,各个 RPC 框架都提供了 Sidecar 组件来支持多语言平台之间的 RPC 调用。
- Dubbo Mesh提供多语言支持
- Motan-go,目前支持 PHP、Java 语言之间的相互调用
- spring-cloud-netflix-sidecar,可以让其他语言也可以使用 Spring Cloud 的组件
跨语言平台的开源 RPC 框架:
名称 公司 年代 支持语言 gRPC Google 2015 C++、Java、Python、Go、Ruby、PHP、Android Java、Objective-C Thrift Facebook 2007 年贡献给 Apache 基金 C++、Java、PHP、Python、Ruby、Erlang
0.3.1. 限定语言平台的开源RPC框架
0.3.1.1. Dubbo
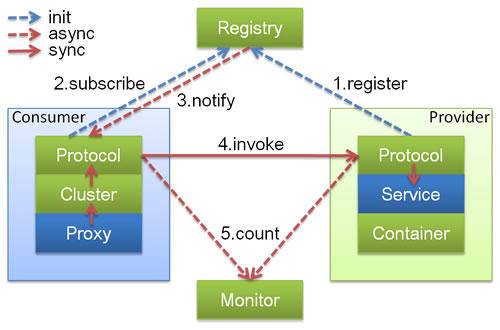
Dubbo 的架构主要包含四个角色:
- Consumer 是服务消费者
- Provider 是服务提供者
- Registry 是注册中心
- Monitor 是监控系统
具体的交互流程:
- Consumer 一端通过注册中心获取到 Provider 节点后,通过 Dubbo 的客户端 SDK 与 Provider 建立连接,并发起调用。
- Provider 一端通过 Dubbo 的服务端 SDK 接收到 Consumer 的请求,处理后再把结果返回给 Consumer。
服务消费者和服务提供者都需要引入 Dubbo 的 SDK 才来完成 RPC 调用,因为 Dubbo 本身是采用 Java 语言实现的,所以要求服务消费者和服务提供者也都必须采用 Java 语言实现才可以应用。
Dubbo 调用框架的实现:
- 通信框架方面,Dubbo 默认采用了 Netty 作为通信框架
- 通信协议方面,Dubbo 除了支持私有的 Dubbo 协议外,还支持 RMI 协议、Hession 协议、HTTP 协议、Thrift 协议等
- 序列化格式方面,Dubbo 支持多种序列化格式,比如 Dubbo、Hession、JSON、Kryo、FST 等
0.3.1.2. Motan
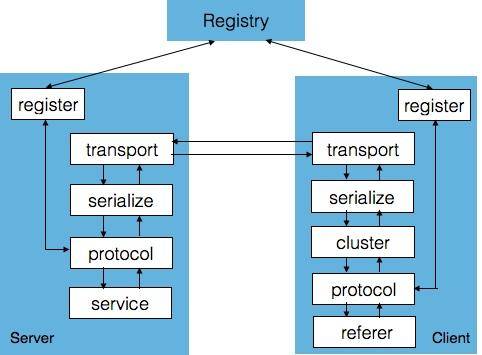
Motan 与 Dubbo 的架构类似,都需要在 Client 端(服务消费者)和 Server 端(服务提供者)引入 SDK,其中 Motan 框架主要包含:
- register:用来和注册中心交互,包括注册服务、订阅服务、服务变更通知、服务心跳发送等功能。Server 端会在系统初始化时通过 register 模块注册服务,Client 端会在系统初始化时通过 register 模块订阅到具体提供服务的 Server 列表,当 Server 列表发生变更时也由 register 模块通知 Client。
- protocol:用来进行 RPC 服务的描述和 RPC 服务的配置管理,这一层还可以添加不同功能的 filter 用来完成统计、并发限制等功能。
- serialize:将 RPC 请求中的参数、结果等对象进行序列化与反序列化,即进行对象与字节流的互相转换,默认使用对 Java 更友好的 Hessian 2 进行序列化。
- transport:用来进行远程通信,默认使用 Netty NIO 的 TCP 长链接方式。
- cluster:Client 端使用的模块,cluster 是一组可用的 Server 在逻辑上的封装,包含若干可以提供 RPC 服务的 Server,实际请求时会根据不同的高可用与负载均衡策略选择一个可用的 Server 发起远程调用。
0.3.1.3. Tars
目前支持的开发语言如下:C++、Java、Nodejs、PHP、Go
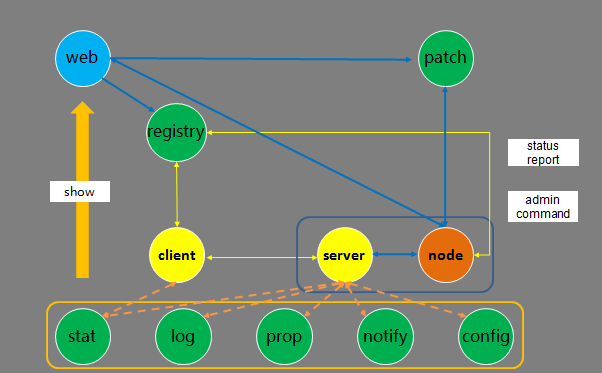
Tars 的架构交互主要包括以下几个流程:
- 服务发布流程:在 web 系统上传 server 的发布包到 patch,上传成功后,在 web 上提交发布 server 请求,由 registry 服务传达到 node,然后 node 拉取 server 的发布包到本地,拉起 server 服务。
- 管理命令流程:web 系统上可以提交管理 server 服务命令请求,由 registry 服务传达到 node 服务,然后由 node 向 server 发送管理命令。
- 心跳上报流程:server 服务运行后,会定期上报心跳到 node,node 然后把服务心跳信息上报到 registry 服务,由 registry 进行统一管理。
- 信息上报流程:server 服务运行后,会定期上报统计信息到 stat,打印远程日志到 log,定期上报属性信息到 prop、上报异常信息到 notify、从 config 拉取服务配置信息。client 访问 server 流程:client 可以通过 server 的对象名 Obj 间接访问 server,client 会从 registry 上拉取 server 的路由信息(如 IP、Port 信息),然后根据具体的业务特性(同步或者异步,TCP 或者 UDP 方式)访问 server(当然 client 也可以通过 IP/Port 直接访问 server)。
0.3.1.4. Spring Cloud
为了解决微服务架构中服务治理而提供的一系列功能的开发框架,它是完全基于 Spring Boot 进行开发的,Spring Cloud 利用 Spring Boot 特性整合了开源行业中优秀的组件,整体对外提供了一套在微服务架构中服务治理的解决方案。因为 Spring Boot 是用 Java 语言编写的,所以目前 Spring Cloud 也只支持 Java 语言平台,它的架构图可以用下面这张图来描述。
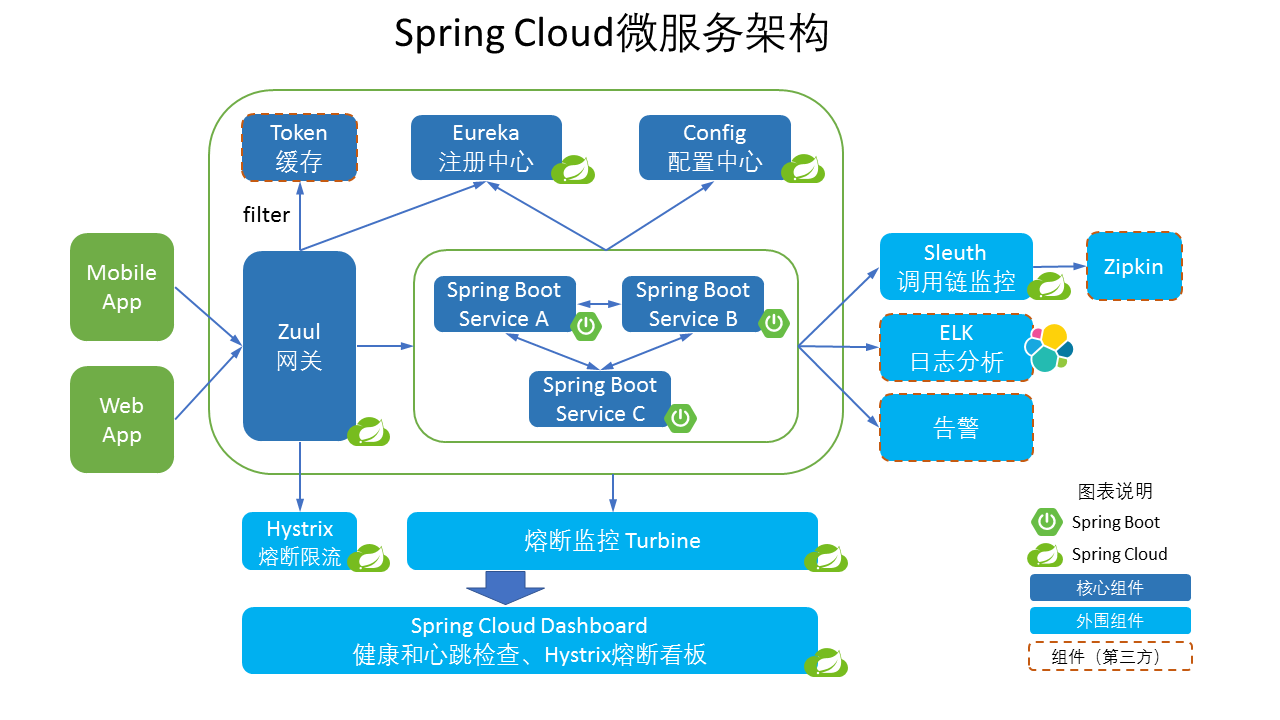
Spring Cloud 微服务架构是由多个组件一起组成的,各个组件的交互流程如下:
- 请求统一通过 API 网关 Zuul 来访问内部服务,先经过 Token 进行安全认证。
- 通过安全认证后,网关 Zuul 从注册中心 Eureka 获取可用服务节点列表。
- 从可用服务节点中选取一个可用节点,然后把请求分发到这个节点。
- 整个请求过程中,Hystrix 组件负责处理服务超时熔断,Turbine 组件负责监控服务间的调用和熔断相关指标,Sleuth 组件负责调用链监控,ELK 负责日志分析。
0.3.1.5. 对比选型
- 如果语言平台是 C++,那么只能选择 Tars;
- 如果是 Java 的话,可以选择 Dubbo、Motan 或者 Spring Cloud
Spring Cloud 不仅提供了基本的 RPC 框架功能,还提供了服务注册组件、配置中心组件、负载均衡组件、断路器组件、分布式消息追踪组件等一系列组件,被技术圈的人称之为“Spring Cloud 全家桶”。如果不想自己实现以上这些功能,那么 Spring Cloud 基本可以满足你的全部需求。
而 Dubbo、Motan 基本上只提供了最基础的 RPC 框架的功能,其他微服务组件都需要自己去实现。由于 Spring Cloud 的 RPC 通信采用了 HTTP 协议,相比 Dubbo 和 Motan 所采用的私有协议来说,在高并发的通信场景下,性能相对要差一些,所以对性能有苛刻要求的情况下,可以考虑 Dubbo 和 Motan。
0.3.2. 跨语言平台的开源 RPC 框架
0.3.2.1. gRPC
gRPC框架详解,出门右转看这里。
原理是通过 IDL(Interface Definition Language)文件定义服务接口的参数和返回值类型,然后通过代码生成程序生成服务端和客户端的具体实现代码,这样在 gRPC 里,客户端应用可以像调用本地对象一样调用另一台服务器上对应的方法。
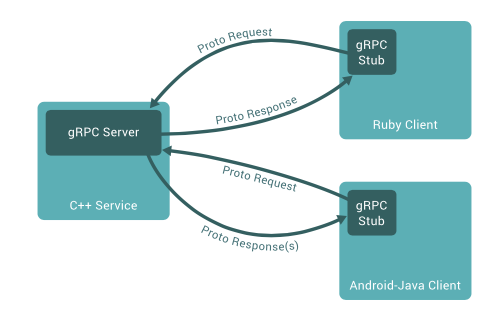
它的主要特性包括三个方面。
- 通信协议采用了
HTTP/2,因为HTTP/2提供了连接复用、双向流、服务器推送、请求优先级、首部压缩等机制,所以在通信过程中可以节省带宽、降低 TCP 连接次数、节省 CPU,尤其对于移动端应用来说,可以帮助延长电池寿命。 - IDL 使用了ProtoBuf,ProtoBuf 是由 Google 开发的一种数据序列化协议,它的压缩和传输效率极高,语法也简单,所以被广泛应用在数据存储和通信协议上。
- 多语言支持,能够基于多种语言自动生成对应语言的客户端和服务端的代码。
0.3.2.2. Thrift
Thrift 是一种轻量级的跨语言 RPC 通信方案,支持多达 25 种编程语言。Thrift 有一套自己的接口定义语言 IDL,可以通过代码生成器,生成各种编程语言的 Client 端和 Server 端的 SDK 代码,这样就保证了不同语言之间可以相互通信。
它的架构图可以用下图来描述。
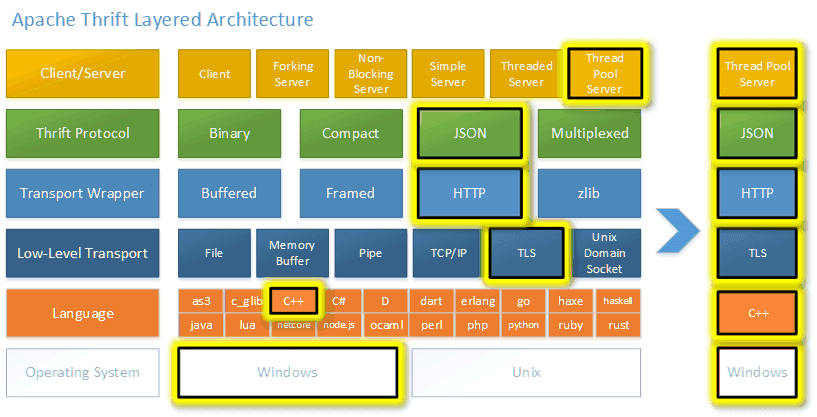
Thrift RPC 框架的特性:
- 支持多种序列化格式:如 Binary、Compact、JSON、Multiplexed 等
- 支持多种通信方式:如 Socket、Framed、File、Memory、zlib 等
- 服务端支持多种处理方式:如 Simple 、Thread Pool、Non-Blocking 等
0.3.2.3. 跨语言框架对比选型
从成熟度上来讲,Thrift 因为诞生的时间要早于 gRPC,所以使用的范围要高于 gRPC,在 HBase、Hadoop、Scribe、Cassandra 等许多开源组件中都得到了广泛地应用。
而且 Thrift 支持多达 25 种语言,这要比 gRPC 支持的语言更多,所以如果遇到 gRPC 不支持的语言场景下,选择 Thrift 更合适。
但 gRPC 作为后起之秀,因为采用了 HTTP/2作为通信协议、ProtoBuf 作为数据序列化格式,在移动端设备的应用以及对传输带宽比较敏感的场景下具有很大的优势,而且开发文档丰富,根据 ProtoBuf 文件生成的代码要比 Thrift 更简洁一些,从使用难易程度上更占优势,所以如果使用的语言平台 gRPC 支持的话,建议还是采用 gRPC 比较好。
gRPC 和 Thrift 虽然支持跨语言的 RPC 调用,但是因为只提供了最基本的 RPC 框架功能,缺乏一系列配套的服务化组件和服务治理功能的支撑,所以使用它们作为跨语言调用的 RPC 框架,就需要自己考虑注册中心、熔断、限流、监控、分布式追踪等功能的实现,不过好在大多数功能都有开源实现,可以直接采用。
0.4. 监控系统
一个监控系统的组成主要涉及四个环节:
- 数据收集
- 数据传输
- 数据处理
- 数据展示
不同的监控系统实现方案,在这四个环节所使用的技术方案不同,适合的业务场景也不一样。
比较流行的开源监控系统实现方案主要有两种:
- 以ELK为代表的集中式日志解决方案
- 以Graphite、TICK和Prometheus等为代表的时序数据库解决方案
0.4.1. ELK
ELK 是 Elasticsearch、Logstash、Kibana 三个开源软件产品首字母的缩写,通常配合使用,所以被称为 ELK Stack,架构如下图所示。
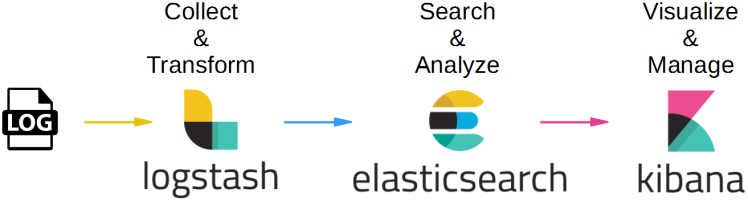
- Logstash 负责数据收集和传输,它支持动态地从各种数据源收集数据,并对数据进行过滤、分析、格式化等,然后存储到指定的位置。
- Elasticsearch 负责数据处理,它是一个开源分布式搜索和分析引擎,具有可伸缩、高可靠和易管理等特点,基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作,通常被用作基础搜索引擎。
- Kibana 负责数据展示,通常和 Elasticsearch 搭配使用,对其中的数据进行搜索、分析并且以图表的方式展示。
这种架构需要在各个服务器上部署 Logstash 来从不同的数据源收集数据,所以比较消耗 CPU 和内存资源,容易造成服务器性能下降,因此后来又在 Elasticsearch、Logstash、Kibana 之外引入了 Beats 作为数据收集器。
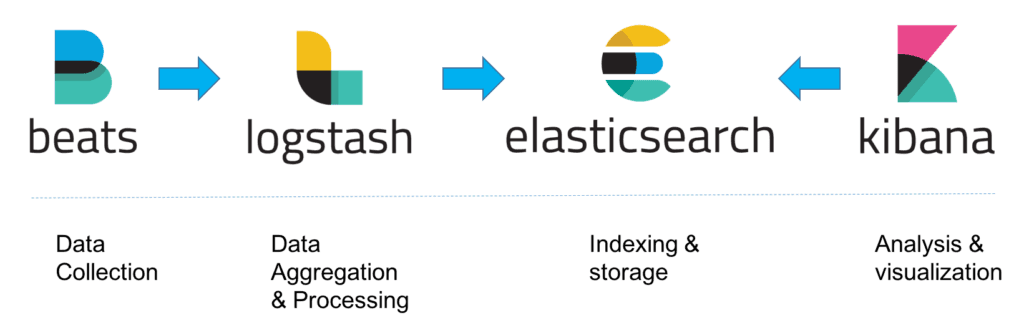
相比于 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计,可以安装在每台服务器上做轻量型代理,从成百上千或成千上万台机器向 Logstash 或者直接向 Elasticsearch 发送数据。
Beats 支持多种数据源,主要包括:
- Packetbeat,用来收集网络流量数据
- Topbeat,用来收集系统、进程的 CPU 和内存使用情况等数据
- Filebeat,用来收集文件数据
- Winlogbeat,用来收集 Windows 事件日志收据
Beats 将收集到的数据发送到 Logstash,经过 Logstash 解析、过滤后,再将数据发送到 Elasticsearch,最后由 Kibana 展示,架构如下图所示。
0.4.2. Graphite
Graphite 的组成主要包括三部分:
- Carbon:负责数据处理
- Whisper:负责数据存储
- Graphite-Web:负责数据展示
架构如下图。
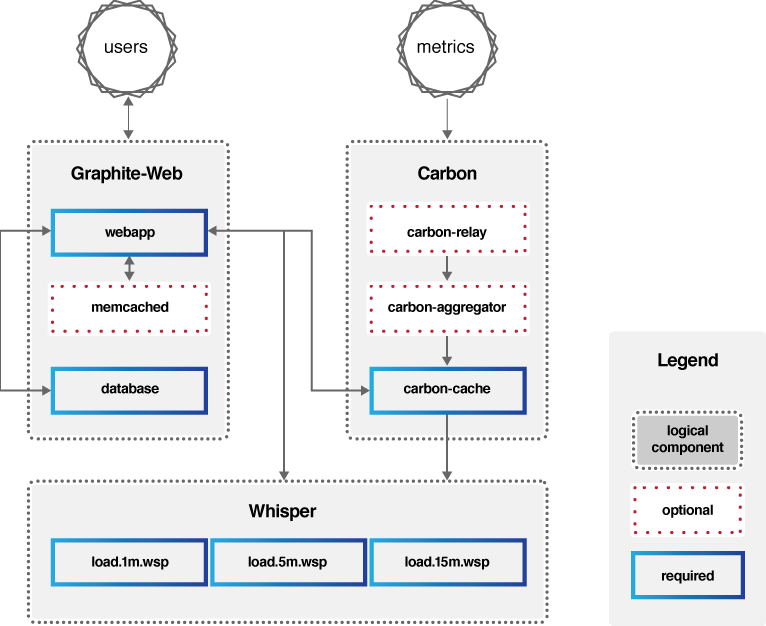
- Carbon:主要作用是接收被监控节点的连接,收集各个指标的数据,将这些数据写入 carbon-cache 并最终持久化到 Whisper 存储文件中去。
- Whisper:一个简单的时序数据库,主要作用是存储时间序列数据,可以按照不同的时间粒度来存储数据,比如 1 分钟 1 个点、5 分钟 1 个点、15 分钟 1 个点三个精度来存储监控数据。
- Graphite-Web:一个 Web App,其主要功能绘制报表与展示,即数据展示。为了保证 Graphite-Web 能及时绘制出图形,Carbon 在将数据写入 Whisper 存储的同时,会在 carbon-cache 中同时写入一份数据,Graphite-Web 会先查询 carbon-cache,如果没有再查询 Whisper 存储。
Graphite 自身并不包含数据采集组件,可以接入StatsD等开源数据采集组件来采集数据,再传送给 Carbon。
Carbon 对写入的数据格式有一定的要求,比如:
// key” + 空格分隔符 + “value + 时间戳”的数据格式
// “.”分割的 key,代表具体的路径信息
// Unix 时间戳
servers.www01.cpuUsage 42 1286269200
products.snake-oil.salesPerMinute 123 1286269200
[one minute passes]
servers.www01.cpuUsageUser 44 1286269260
products.snake-oil.salesPerMinute 119 1286269260Graphite-Web 对外提供了 HTTP API 可以查询某个 key 的数据以绘图展示,查询方式如下。
// 查询 key“servers.www01.cpuUsage
// 在过去 24 小时的数据
// 要求返回 500*300 大小的数据图
http://graphite.example.com/render?target=servers.www01.cpuUsage&
width=500&height=300&from=-24h
// Graphite-Web 还支持丰富的函数
// 代表了查询匹配规则“products.*.salesPerMinute”的所有 key 的数据之和
target=sumSeries(products.*.salesPerMinute)0.4.3. TICK
TICK 是 Telegraf、InfluxDB、Chronograf、Kapacitor 四个软件首字母的缩写,是由 InfluxData 开发的一套开源监控工具栈,因此也叫作 TICK Stack,架构如下图所示。
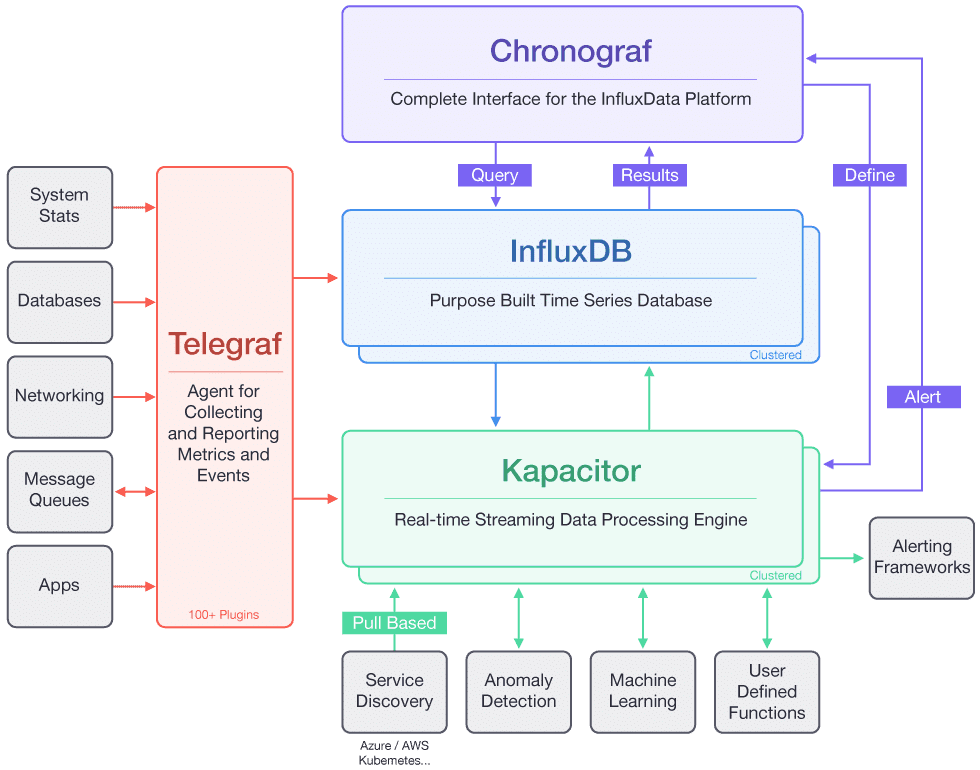
- Telegraf 负责数据收集
- InfluxDB 负责数据存储
- Chronograf 负责数据展示
- Kapacitor 负责数据告警
InfluxDB 对写入的数据格式要求如下:
// <measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp]
// host为serverA,region为us_west,cpu的值为0.64,时间戳为1434067467100293230,精确到nano
cpu,host=serverA,region=us_west value=0.64 14340674671002932300.4.4. Prometheus
时间序数据库解决方案 Prometheus,它是一套开源的系统监控报警框架,受 Google 的集群监控系统 Borgmon 启发,2016 年正式加入 CNCF(Cloud Native Computing Foundation),成为受欢迎程度仅次于 Kubernetes 的项目,架构如下图所示。
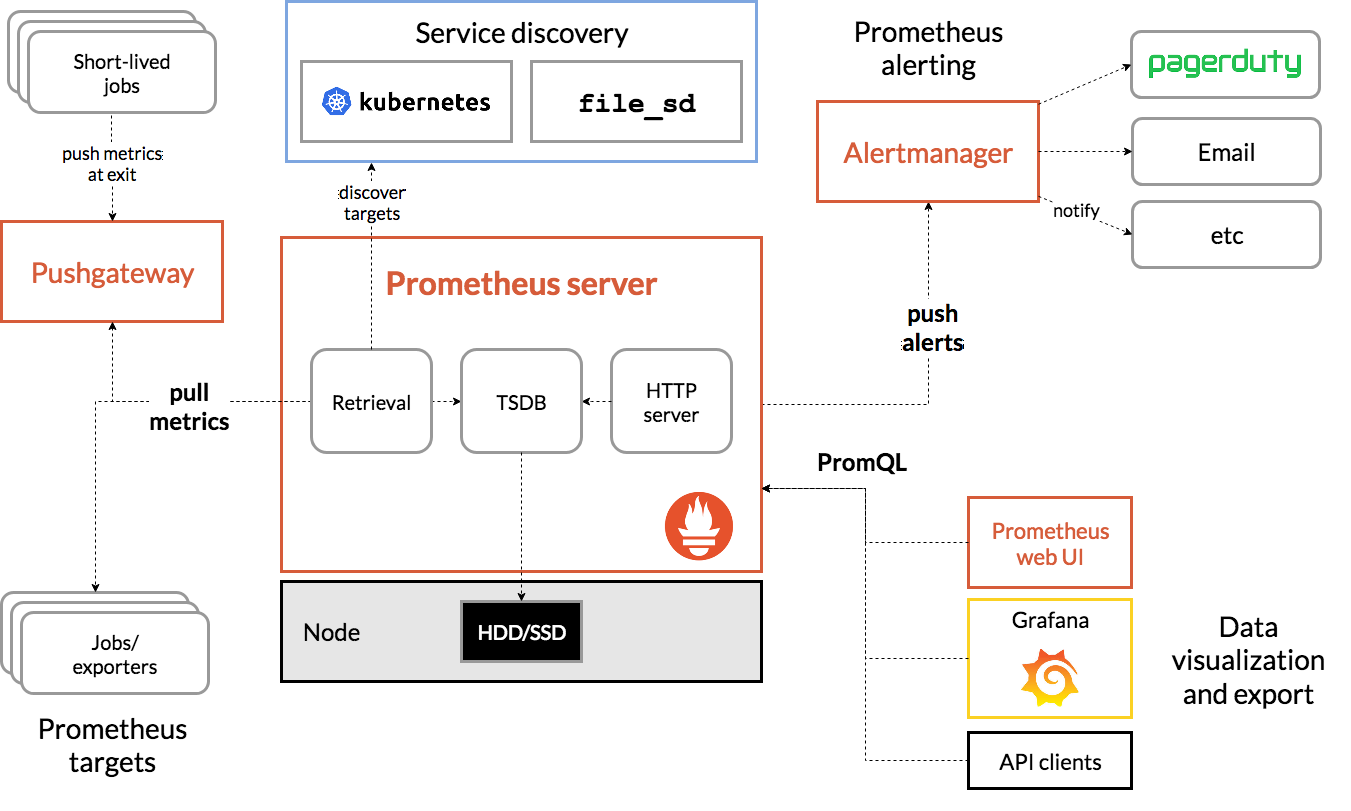
Prometheus 主要包含下面几个组件:
- Prometheus Server:用于拉取 metrics 信息并将数据存储在时间序列数据库。
- Jobs/exporters:用于暴露已有的第三方服务的 metrics 给 Prometheus Server,比如 StatsD、Graphite 等,负责数据收集。
- Pushgateway:主要用于短期 jobs,由于这类 jobs 存在时间短,可能在 Prometheus Server 来拉取 metrics 信息之前就消失了,所以这类的 jobs 可以直接向 Prometheus Server 推送它们的 metrics 信息。
- Alertmanager:用于数据报警。
- Prometheus web UI:负责数据展示。
工作流程:
- Prometheus Server 定期从配置好的 jobs 或者 exporters 中拉取 metrics 信息,或者接收来自 Pushgateway 发过来的 metrics 信息。
- Prometheus Server 把收集到的 metrics 信息存储到时间序列数据库中,并运行已经定义好的
alert.rules,向 Alertmanager 推送警报。 - Alertmanager 根据配置文件,对接收的警报进行处理,发出告警。
- 通过 Prometheus web UI 进行可视化展示。
Prometheus 存储数据到时间序列数据库,格式如下
// <metric name>{<label name>=<label value>, …}
// 集群:cluster1、节点IP:1.1.1.1、端口:80、访问路径:/a、http请求总和:100
http_requests_total{instance="1.1.1.1:80",job="cluster1",location="/a"} 1000.4.5. 选型对比
0.4.5.1. 数据收集
- ELK 是通过在每台服务器上部署 Beats 代理来采集数据
- Graphite 本身没有数据采集组件,需要配合使用开源收据采集组件,比如 StatsD
- TICK 使用了 Telegraf 作为数据采集组件
- Prometheus 通过
jobs/exporters组件来获取 StatsD 等采集过来的 metrics 信息
0.4.5.2. 数据传输
- ELK 是 Beats 采集的数据传输给 Logstash,经过 Logstash 清洗后再传输给 Elasticsearch
- Graphite 是通过第三方采集组件采集的数据,传输给 Carbon
- TICK 是 Telegraf 采集的数据,传输给 InfluxDB
- Prometheus 是 Prometheus Server 隔一段时间定期去从
jobs/exporters拉取数据
前三种都是采用“推数据”的方式,而 Prometheus 是采取“拉数据”的方式,因此 Prometheus 的解决方案对服务端的侵入最小,不需要在服务端部署数据采集代理。
0.4.5.3. 数据处理
- ELK 可以对日志的任意字段索引,适合多维度的数据查询,在存储时间序列数据方面与时间序列数据库相比会有额外的性能和存储开销。
时间序列数据库的几种解决方案都支持多种功能的数据查询处理,功能也更强大。
- Graphite 通过 Graphite-Web 支持正则表达式匹配、sumSeries 求和、alias 给监控项重新命名等函数功能,同时还支持这些功能的组合,如下所示:
// 查询所有匹配路径“stats.open.profile.*.API._comments_flow”的监控项之和,并且把监控项重命名为 Total QPS
alias(sumSeries(stats.openapi.profile.*.API._comments_flow.total_count,"Total QPS")- InfluxDB 通过类似 SQL 语言的 InfluxQL,能对监控数据进行复杂操作,如下所示:
// 查询一分钟 CPU 的使用率
SELECT 100 - usage_idel FROM "
gen"."cpu" WHERE time > now() - 1m and "cpu"='cpu0'- Prometheus 通过私有的 PromQL 查询语言,PromQL 语句如下,看起来更加简洁,如下所示:
// 查询一分钟 CPU 的使用率
100 - (node_cpu{job="node",mode="idle"}[1m])0.4.5.4. 数据展示
- Graphite、TICK 和 Prometheus 自带的展示功能都比较弱,界面也不好看,不过好在它们都支持Grafana来做数据展示。
Grafana 是一个开源的仪表盘工具,它支持多种数据源比如 Graphite、InfluxDB、Prometheus 以及 Elasticsearch 等。
- ELK 采用了 Kibana 做数据展示,Kibana 包含的数据展示功能比较强大,但只支持 Elasticsearch,而且界面展示 UI 效果不如 Grafana 美观。
0.4.5.5. 总体
- ELK 的技术栈比较成熟,应用范围也比较广,除了可用作监控系统外,还可以用作日志查询和分析。
- Graphite 是基于时间序列数据库存储的监控系统,并且提供了功能强大的各种聚合函数比如 sum、average、top5 等用于监控分析,而且对外提供了 API 也可以接入其他图形化监控系统如 Grafana。
- TICK 的核心在于其时间序列数据库 InfluxDB 的存储功能强大,且支持类似 SQL 语言的复杂数据处理操作。
- Prometheus 的独特之处在于它采用了拉数据的方式,对业务影响较小,同时也采用了时间序列数据库存储,而且支持独有的 PromQL 查询语言,功能强大而且简洁。
实时性要求角度考虑,时间序列数据库的实时性要好于 ELK,通常可以做到 10s 级别内的延迟,如果对实时性敏感的话,建议选择时间序列数据库解决方案。
使用的灵活性角度考虑,几种时间序列数据库的监控处理功能都要比 ELK 更加丰富,使用更灵活也更现代化。所以如果要搭建一套新的监控系统,我建议可以考虑采用 Graphite、TICK 或者 Prometheus 其中之一。
Graphite 需要搭配数据采集系统比如 StatsD 或者 Collectd 使用,而且界面展示建议使用 Grafana 接入 Graphite 的数据源,它的效果要比 Graphite Web 本身提供的界面美观很多。
TICK 提供了完整的监控系统框架,包括从数据采集、数据传输、数据处理再到数据展示,不过在数据展示方面同样也建议用 Grafana 替换掉 TICK 默认的数据展示组件 Chronograf,这样展示效果更好。
Prometheus 因为采用拉数据的方式,所以对业务的侵入性最小,比较适合 Docker 封装好的云原生应用,比如 Kubernetes 默认就采用了 Prometheus 作为监控系统。
0.5. 服务追踪系统
服务追踪系统的实现,主要包括三个部分:
- 埋点数据收集,负责在服务端进行埋点,来收集服务调用的上下文数据
- 实时数据处理,负责对收集到的链路信息,按照 traceId 和 spanId 进行串联和存储
- 数据链路展示,把处理后的服务调用数据,按照调用链的形式展示出来
0.5.1. Zipkin
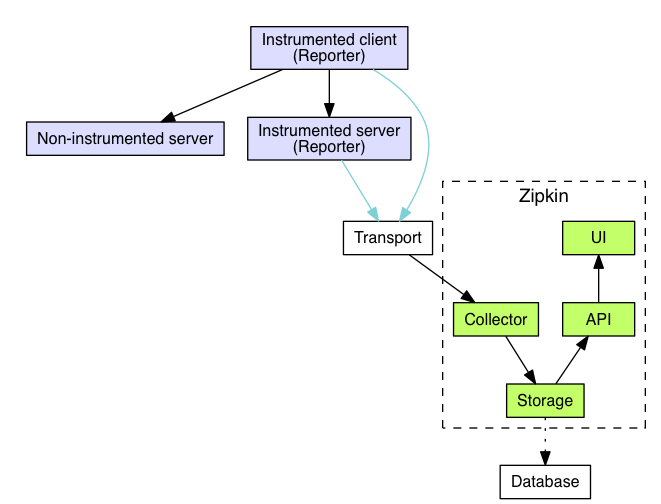
Zipkin 主要由四个核心部分组成:
- Collector:负责收集探针 Transport 埋点采集的数据,经过验证处理并建立索引
- Storage:存储服务调用的链路数据,默认使用的是 Cassandra(Twitter内部使用),可以替换成 Elasticsearch 或者 MySQL
- API:将格式化和建立索引的链路数据以 API 的方式对外提供服务,比如被 UI 调用
- UI:以图形化的方式展示服务调用的链路数据
工作原理:
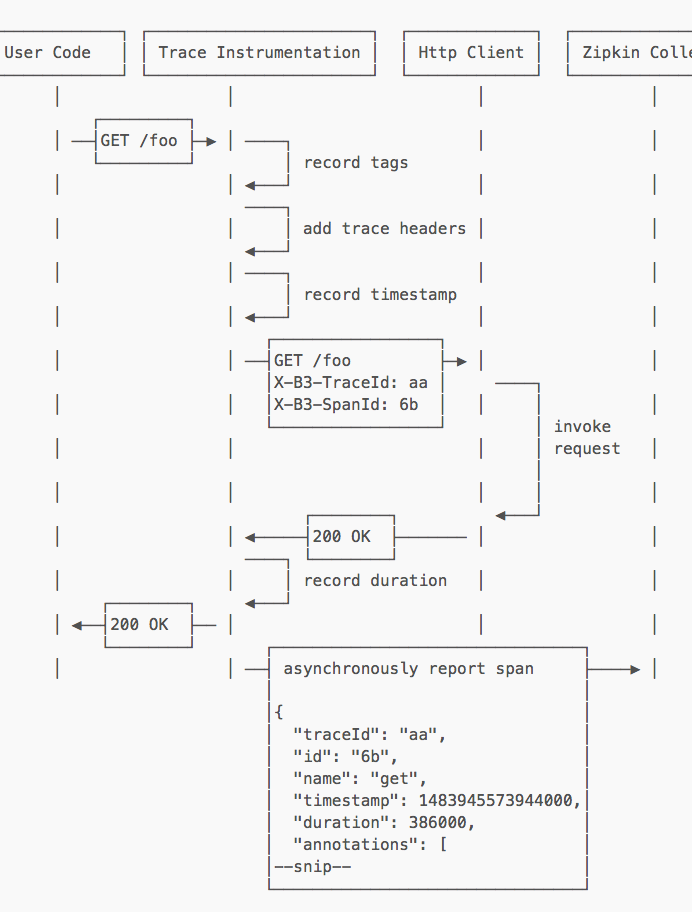
- 在业务的 HTTP Client 前后引入服务追踪代码,这样在 HTTP 方法
/foo调用前,生成 trace 信息:TraceId:aa、SpanId:6b、annotation:GET /foo,当前时刻的timestamp:1483945573944000, - 调用结果返回后,记录下耗时 duration,
- 再把这些 trace 信息和 duration 异步上传给 Zipkin Collector
0.5.2. Pinpoint
Pinpoint 是 Naver 开源的一款深度支持 Java 语言的服务追踪系统,架构如下图所示:
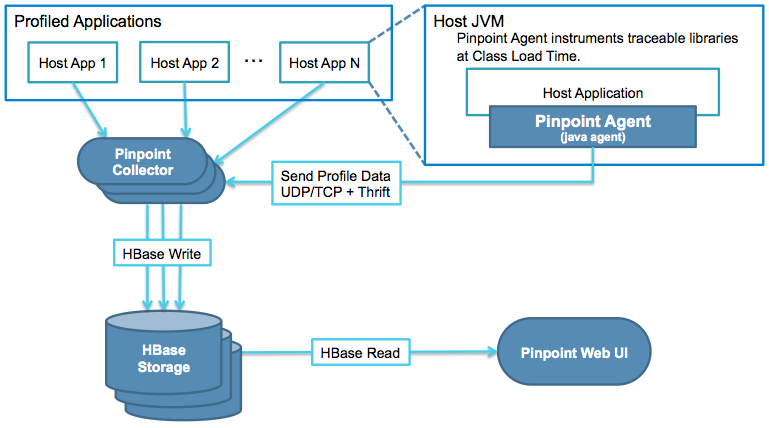
四个部分组成:
- Pinpoint Agent:通过 Java 字节码注入的方式,来收集 JVM 中的调用数据,通过 UDP 协议传递给 Collector,数据采用 Thrift 协议进行编码
- Pinpoint Collector:收集 Agent 传过来的数据,然后写到 HBase Storage
- HBase Storage:采用 HBase 集群存储服务调用的链路信息
- Pinpoint Web UI:通过 Web UI 展示服务调用的详细链路信息
0.5.2.1. 工作原理
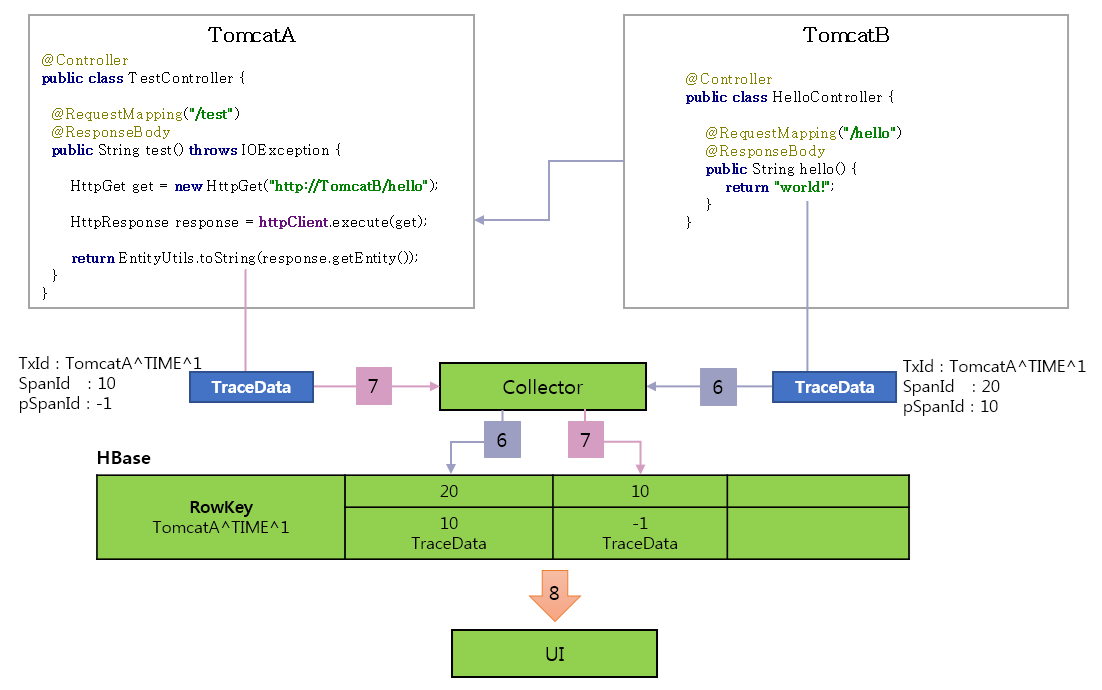
- 请求进入 TomcatA,然后生成
TraceId:TomcatA^ TIME ^ 1、SpanId:10、pSpanId:-1(代表是根请求) - TomatA 调用 TomcatB 的 hello 方法,TomcatB 生成
TraceId:TomcatA^ TIME ^1、新的 SpanId:20、pSpanId:10(代表是 TomcatA 的请求) - 返回调用结果后将 trace 信息发给 Collector,TomcatA 收到调用结果后,将 trace 信息也发给 Collector
- Collector 把 trace 信息写入到 HBase 中,Rowkey 就是 traceId,SpanId 和 pSpanId 都是列。
- 通过 UI 查询调用链路信息
0.5.3. 选型
0.5.3.1. 埋点探针支持平台的广泛性
- Zipkin 提供了不同语言的 Library,不同语言实现时需要引入不同版本的 Library。官方提供了 C#、Go、Java、JavaScript、Ruby、Scala、PHP 等主流语言版本的 Library,而且开源社区还提供了更丰富的不同语言版本的 Library
- Pinpoint 目前只支持 Java 语言。
所以从探针支持的语言平台广泛性上来看,Zipkin 比 Pinpoint 的使用范围要广,而且开源社区很活跃,生命力更强。
0.5.3.2. 系统集成难易程度
- 以 Zipkin 的 Java 探针 Brave 为例,它只提供了基本的操作 API,如果系统要想集成 Brave,必须在配置里手动添加相应的配置文件并且增加 trace 业务代码。具体来讲,需要修改工程的 POM 依赖,以引入 Brave 相关的 JAR 包。收集每一次 HTTP 调用的信息,可以使用 Brave 在 Apache Httpclient 基础上封装的 httpClient,它会记录每一次 HTTP 调用的信息,并上报给 Zipkin。
- Pinpoint 是通过字节码注入的方式来实现拦截服务调用,从而收集 trace 信息的,所以不需要代码做任何改动。
Java 字节码注入的大致原理如下图。
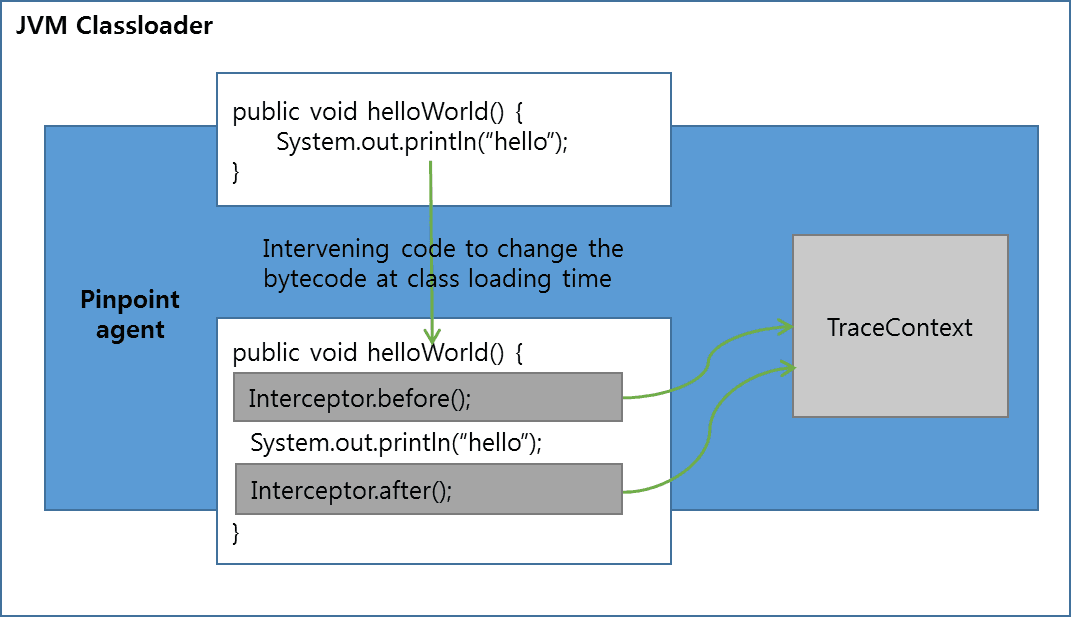
JVM 在加载 class 二进制文件时,动态地修改加载的 class 文件,在方法的前后执行拦截器的 before() 和 after() 方法,在 before() 和 after() 方法里记录 trace() 信息。
应用不需要修改业务代码,只需要在 JVM 启动时,添加类似下面的启动参数:
-javaagent:$AGENT_PATH/pinpoint-bootstrap-$VERSION.jar
-Dpinpoint.agentId=<Agent's UniqueId>
-Dpinpoint.applicationName=<The name indicating a same service (AgentId collection)从系统集成难易程度上看,Pinpoint 要比 Zipkin 简单。
0.5.3.3. 调用链路数据的精确度
- Zipkin 收集到的数据只到接口级别
- Pinpoint 采用了字节码注入的方式实现 trace 信息收集,所以它能拿到的信息比 Zipkin 多得多。不仅能够查看接口级别的链路调用信息,还能深入到调用所关联的数据库信息。
在绘制链路拓扑图时:
- Zipkin 只能绘制服务与服务之间的调用链路拓扑图
- Pinpoint 不仅能够绘制服务与服务之间,还能绘制与 DB 之间的调用链路拓扑图
从调用链路数据的精确度上看,Pinpoint 要比 Zipkin 精确得多。
除了 Zipkin 和 Pinpoint,业界还有其他开源追踪系统实现,比如 Uber 开源的 Jaeger,以及国内的一款开源服务追踪系统 SkyWalking。
0.6. 服务治理
0.6.1. 服务节点探活
0.6.1.1. 心跳开关保护机制
在网络频繁抖动的情况下,注册中心中可用的节点会不断变化,服务消费者会频繁收到服务提供者节点变更的信息,不断请求注册中心来拉取最新的可用服务节点信息。当有成百上千个服务消费者,同时请求注册中心获取最新的服务提供者的节点信息时,可能会把注册中心的带宽给占满。
需要一种保护机制,即使在网络频繁抖动的时候,服务消费者也不至于同时去请求注册中心获取最新的服务节点信息。
一个可行的解决方案就是给注册中心设置一个开关,当开关打开时,即使网络频繁抖动,注册中心也不会通知所有的服务消费者有服务节点信息变更,比如只给 10% 的服务消费者返回变更,这样的话就能将注册中心的请求量减少到原来的 1/10。
打开开关会导致服务消费者感知最新的服务节点信息延迟到几分钟,在网络正常的情况下,开关并不适合打开;可以作为一个紧急措施,在网络频繁抖动的时候,才打开这个开关。
心跳开关保护机制,是为了防止服务提供者节点频繁变更导致的服务消费者同时去注册中心获取最新服务节点信息。
0.6.1.2. 服务节点摘除保护机制
服务提供者在进程启动时,会注册服务到注册中心,并每隔一段时间,汇报心跳给注册中心,以标识自己的存活状态。如果隔了一段固定时间后,服务提供者仍然没有汇报心跳给注册中心,注册中心就会认为该节点已经处于“dead”状态,于是从服务的可用节点信息中移除出去。
如果遇到网络问题,大批服务提供者节点汇报给注册中心的心跳信息都可能会传达失败,注册中心就会把它们都从可用节点列表中移除出去,造成剩下的可用节点难以承受所有的调用,引起“雪崩”。但是这种情况下,可能大部分服务提供者节点是可用的,仅仅因为网络原因无法汇报心跳给注册中心就被“无情”的摘除了。
这个时候就需要根据实际业务的情况,设定一个阈值比例,即使遇到上述情况,注册中心也不能摘除超过这个阈值比例的节点。
这个阈值比例可以根据实际业务的冗余度来确定,通常会把这个比例设定在 20%,就是说注册中心不能摘除超过 20% 的节点。
因为大部分情况下,节点的变化不会这么频繁,只有在网络抖动或者业务明确要下线大批量节点的情况下才有可能发生。
而业务明确要下线大批量节点的情况是可以预知的,这种情况下可以关闭阈值保护;而正常情况下,应该打开阈值保护,以防止网络抖动时,大批量可用的服务节点被摘除。
服务节点摘除保护机制,是为了防止服务提供者节点被大量摘除引起服务消费者可以调用的节点不足。
上述两种情况下,因为注册中心里的节点信息是随时可能发生变化的,所以也可以把注册中心叫作动态注册中心。
0.6.1.3. 静态注册中心
服务消费者并不严格以注册中心中的服务节点信息为准,而是更多的以服务消费者实际调用信息来判断服务提供者节点是否可用。
- 如果服务消费者调用某一个服务提供者节点连续失败超过一定次数,可以在本地内存中将这个节点标记为不可用。
- 并且每隔一段固定时间,服务消费者都要向标记为不可用的节点发起保活探测,如果探测成功了,就将标记为不可用的节点再恢复为可用状态,重新发起调用。
这样的话,服务提供者节点就不需要向注册中心汇报心跳信息,注册中心中的服务节点信息也不会动态变化,称之为静态注册中心。
采用服务消费者端的保活机制,事实证明这种机制足以应对网络频繁抖动等复杂的场景。
静态注册中心中的服务节点信息并不是一直不变,当在业务上线或者运维人工增加或者删除服务节点这种预先感知的情况下,还是有必要去修改注册中心中的服务节点信息。
0.6.2. 负载均衡算法
为什么要引入负载均衡算法呢?
- 考虑调用的均匀性,要让每个节点都接收到调用,发挥所有节点的作用
- 考虑调用的性能,哪个节点响应最快,优先调用哪个节点
0.6.2.1. 适用场景
| 算法 | 描述 | 场景 |
|---|---|---|
| 随机算法 | 实现简单,在请求量远超可用服务节点数量的情况下,各个服务节点被访问的概率基本相同 | 应用在各个服务节点的性能差异不大的情况下 |
| 轮询算法 | 跟随机算法类似,各个服务节点被访问的概率也基本相同 | 应用在各个服务节点性能差异不大的情况下 |
| 加权轮询算法 | 在轮询算法基础上的改进,可以通过给每个节点设置不同的权重来控制访问的概率 | 应用在服务节点性能差异比较大的情况 |
| 最少活跃连接算法 | 与加权轮询算法预先定义好每个节点的访问权重不同,采用最少活跃连接算法,客户端同服务端节点的连接数是在时刻变化的,理论上连接数越少代表此时服务端节点越空闲,选择最空闲的节点发起请求,能获取更快的响应速度 | 尤其在服务端节点性能差异较大,而又不好做到预先定义权重时,采用最少活跃连接算法是比较好的选择 |
| 一致性 hash 算法 | 能够保证同一个客户端的请求始终访问同一个服务节点 | 适合服务端节点处理不同客户端请求差异较大的场景。如服务端缓存里保存着客户端的请求结果,可以一直从缓存中获取数据 |
0.6.2.2. 自适应最优选择算法
在客户端本地维护一份同每一个服务节点的性能统计快照,并且每隔一段时间去更新这个快照。在发起请求时,根据“二八原则”,把服务节点分成两部分,找出 20% 的那部分响应最慢的节点,然后降低权重。这样的话,客户端就能够实时的根据自身访问每个节点性能的快慢,动态调整访问最慢的那些节点的权重,来减少访问量,从而可以优化长尾请求。
自适应最优选择算法是对加权轮询算法的改良,可以看作是一种动态加权轮询算法。它的实现关键之处就在于两点:
- 第一点是每隔一段时间获取客户端同每个服务节点之间调用的平均性能统计
- 第二点是按照这个性能统计对服务节点进行排序,对排在性能倒数 20% 的那部分节点赋予一个较低的权重,其余的节点赋予正常的权重
在具体实现时:
- 针对第一点,需要在内存中开辟一块空间记录客户端同每一个服务节点之间调用的平均性能,并每隔一段固定时间去更新。这个更新的时间间隔太短容易受瞬时的性能抖动影响,导致统计变化太快,没有参考性;太长的话时效性就会大打折扣,效果不佳,1 分钟的更新时间间隔是个比较合适的值。
- 针对第二点,关键点是权重值的设定,即使服务节点之间的性能差异较大,也不适合把权重设置得差异太大,这样会导致性能较好的节点与性能较差的节点之间调用量相差太大,这样也不是一种合理的状态。在实际设定时,可以设置 20% 性能较差的节点权重为 3,其余节点权重为 5。
0.6.3. 服务路由
服务路由就是服务消费者在发起服务调用时,必须根据特定的规则来选择服务节点,从而满足某些特定的需求。
0.6.3.1. 应用场景
- 分组调用。为了保证服务的高可用性,实现异地多活的需求,一个服务会部署在不同的数据中心和不同的公有云环境,服务节点也会分成不同的分组,对于服务消费者来说,选择哪一个分组调用,就必须有相应的路由规则。
- 灰度发布(金丝雀部署)。在服务上线发布前,需要先在一小部分规模的服务节点上先发布服务,然后验证功能是否正常。如果正常的话就继续扩大发布范围;如果不正常的话,就需要排查问题,解决问题后继续发布。
- 流量切换。在业务线上运行过程中,经常会遇到一些不可抗力因素导致业务故障,服务都不可用。这个时候就需要按照某个指令,能够把原来调用异常服务的流量切换到其他正常的机房。
- 读写分离。对于大多数互联网业务来说都是读多写少,所以在进行服务部署的时候,可以把读写分开部署,所有写接口可以部署在一起,而读接口部署在另外的节点上。
0.6.3.2. 服务路由的规则
0.6.3.2.1. 条件路由
条件路由是基于条件表达式的路由规则。
// condition://”代表了这是一段用条件表达式编写的路由规则
// 具体的规则是host = 10.20.153.10 => host = 10.20.153.11
// 分隔符“=>”前面是服务消费者的匹配条件,后面是服务提供者的过滤条件
condition://0.0.0.0/dubbo.test.interfaces.TestService?category=routers&dynamic=true&priority=2&enabled=true&rule="
// + URL.encode(" host = 10.20.153.10=> host = 10.20.153.11")
// 如果服务消费者的匹配条件为空,就表示对所有的服务消费者应用 => host != 10.20.153.11
// 如果服务提供者的过滤条件为空,就表示禁止服务消费者访问 host = 10.20.153.10 =>具体例子
| 功能 | 路由条件 | 说明 |
|---|---|---|
| 排除某个服务节点 | => host != 172.22.3.91 | 所有的服务消费者都不会访问 IP 为 172.22.3.91 的服务节点 |
| 白名单 | host != 10.20.153.10,10.20.153.11 => | 除了 IP 为 10.20.153.10 和 10.20.153.11 的服务消费者可以发起服务调用以外,其他服务消费者都不可以 |
| 黑名单 | host = 10.20.153.10,10.20.153.11 => | 除了 IP 为 10.20.153.10 和 10.20.153.11 的服务消费者不能发起服务调用以外,其他服务消费者都可以 |
| 机房隔离 | host = 172.22.3.* => host = 172.22.3.* | IP 网段为 172.22.3.* 的服务消费者,才可以访问同网段的服务节点 |
| 读写分离 | method = find*,list*,get*,is* => host =172.22.3.94,172.22.3.95;method != find*,list*,get*,is* => host = 172.22.3.97,172.22.3.98 | find、get、is* 等读方法调用 IP 为 172.22.3.94 和 172.22.3.95 的节点,除此以外的写方法调用 IP 为 172.22.3.97 和 172.22.3.98 的节点 |
0.6.3.2.2. 脚本路由
脚本路由是基于脚本语言的路由规则,常用的脚本语言比如 JavaScript、Groovy、JRuby 等。
// “script://”就代表了这是一段脚本语言编写的路由规则
// 具体规则定义在脚本语言的 route 方法实现里,只有 IP 为 10.20.153.10 的服务消费者可以发起服务调用
"script://0.0.0.0/com.foo.BarService?category=routers&dynamic=false&rule=" +
URL.encode("(function route(invokers) { ... } (invokers))")
function route(invokers){
var result = new java.util.ArrayList(invokers.size());
for(i =0; i < invokers.size(); i ++){
if("10.20.153.10".equals(invokers.get(i).getUrl().getHost())){
result.add(invokers.get(i));
}
}
return result;
} (invokers));
0.6.3.3. 服务路由的获取方式
- 本地配置:路由规则存储在服务消费者本地。服务消费者发起调用时,从本地固定位置读取路由规则,然后按照路由规则选取一个服务节点发起调用
- 配置中心管理:所有的服务消费者都从配置中心获取路由规则,由配置中心来统一管理
- 动态下发:运维人员或者开发人员,通过服务治理平台修改路由规则,服务治理平台调用配置中心接口,把修改后的路由规则持久化到配置中心。服务消费者订阅了路由规则的变更,会从配置中心获取最新的路由规则,按照最新的路由规则来执行
一般来讲,服务路由最好是存储在配置中心中,由配置中心来统一管理。这样的话,所有的服务消费者就不需要在本地管理服务路由,因为大部分的服务消费者并不关心服务路由的问题,或者说也不需要去了解其中的细节。通过配置中心,统一给各个服务消费者下发统一的服务路由,节省了沟通和管理成本。动态下发能够动态地修改路由规则,在某些业务场景下十分有用。
三种方式一起使用,服务消费者的判断优先级是本地配置 > 动态下发 > 配置中心管理。
0.7. 服务端故障处理
单体应用改造成微服务的一个好处是可以减少故障影响范围,故障被局限在一个微服务系统本身,而不是整个单体应用都崩溃。
微服务系统可能出现故障的种类:
- 集群故障:一旦代码出现 bug,可能整个集群都会发生故障,不能提供对外提供服务
- 单 IDC 故障:业务部署在不止一个 IDC,某些不可抗力导致整个 IDC 脱网
- 单机故障:集群中的个别机器出现故障,导致调用到故障机器上的请求都失败,影响整个系统的成功率
0.7.1. 集群故障
集群故障的产生原因:
- 代码 bug 所导致,比如说某一段 Java 代码不断地分配大对象,但没有及时回收导致 JVM OOM 退出
- 突发的流量冲击,超出了系统的最大承载能力,比如“双 11”,超出系统的最大承载能力,把整个系统给压垮
应付集群故障的思路,主要有两种:限流和降级。
0.7.1.1. 限流
系统能够承载的流量根据集群规模的大小是固定的,称之为系统的最大容量。
当真实流量超过了系统的最大容量后,就会导致系统响应变慢,服务调用出现大量超时,用户的感觉就是卡顿、无响应。
应该根据系统的最大容量,给系统设置一个阈值,超过这个阈值的请求会被自动抛弃,这样的话可以最大限度地保证系统提供的服务正常。
通常微服务系统会同时提供多个服务,每个服务在同一时刻的请求量也是不同的,可能出现系统中某个服务的请求量突增,占用了系统中大部分资源,导致其他服务没有资源可用。
因此,要针对系统中每个服务的请求量也设置一个阈值,超过这个阈值的请求也要被自动抛弃。
用两个指标来衡量服务的请求量:
- QPS 即每秒请求量
- 工作线程数
不过 QPS 因为不同服务的响应快慢不同,所以系统能够承载的 QPS 相差很大,因此一般选择工作线程数来作为限流的指标,给系统设置一个总的最大工作线程数以及单个服务的最大工作线程数。
0.7.1.2. 降级
降级是通过停止系统中的某些功能,来保证系统整体的可用性,是一种被动防御措施,一般是系统已经出现故障后所采取的一种止损措施。
降级的实现方式:通过开关来实现。
在系统运行的内存中开辟一块区域,专门用于存储开关的状态,也就是开启还是关闭。并且需要监听某个端口,通过这个端口可以向系统下发命令,来改变内存中开关的状态。当开关开启时,业务的某一段逻辑就不再执行,而正常情况下,开关是关闭的状态。
开关一般用在两种地方:
- 新增的业务逻辑,因为新增的业务逻辑相对来说不成熟,往往具备一定的风险,所以需要加开关来控制新业务逻辑是否执行;
- 依赖的服务或资源,因为依赖的服务或者资源不总是可靠的,所以最好是有开关能够控制是否对依赖服务或资源发起调用,来保证即使依赖出现问题,也能通过降级来避免影响。
降级要按照对业务的影响程度分为三级:
- 一级降级:对业务影响最小的降级,在故障的情况下,首先执行一级降级,所以一级降级也可以设置成自动降级,不需要人为干预
- 二级降级:对业务有一定影响的降级,在故障的情况下,如果一级降级起不到多大作用的时候,可以人为采取措施,执行二级降级
- 三级降级:对业务有较大影响的降级,这种降级要么是对商业收入有重大影响,要么是对用户体验有重大影响,所以操作起来要非常谨慎,不在最后时刻一般不予采用
0.7.2. 单 IDC 故障
- 同城双活,在一个城市的两个 IDC 内部署
- 异地多活,在两个城市的两个 IDC 内部署
- 金融级别的应用“三地五中心”部署,部署成本高,但可用性的保障要更高
采用多 IDC 部署的最大好处就是当有一个 IDC 发生故障时,可以把原来访问故障 IDC 的流量切换到正常的 IDC,来保证业务的正常访问。
流量切换的方式一般有两种:
- 基于 DNS 解析:通过把请求访问域名解析的 VIP 从一个 IDC 切换到另外一个 IDC
- 基于 RPC 分组:多IDC部署服务,每个 IDC 就是一个分组。假如一个 IDC 故障,通过向配置中心下发命令,把原先路由到这个分组的流量全部切换到别的分组
比如访问“www.weibo.com”,正常情况下北方用户会解析到联通机房的 VIP,南方用户会解析到电信机房的 VIP,如果联通机房发生故障的话,会把北方用户访问也解析到电信机房的 VIP,只不过此时网络延迟可能会变长。
0.7.3. 单机故障
单机故障是发生概率最高的一种故障,只靠运维人肉处理不可行,要有某种手段来自动处理单机故障。
处理单机故障一个有效的办法就是自动重启。
通过设置阈值完成,如以某个接口的平均耗时为准,当监控单机上某个接口的平均耗时超过一定阈值时,就认为这台机器有问题,就需要把有问题的机器从线上集群中摘除掉,然后在重启服务后,重新加入到集群中。
要注意防止网络抖动造成的接口超时从而触发自动重启:
- 在收集单机接口耗时数据时,多采集几个点,比如每 10s 采集一个点,采集 5 个点,当 5 个点中有超过 3 个点的数据都超过设定的阈值范围,才认为是真正的单机问题,这时会触发自动重启策略。
- 为了防止某些特殊情况下,短时间内被重启的单机过多,造成整个服务池可用节点数太少,最好是设置一个可重启的单机数量占整个集群的最大比例,一般这个比例不要超过 10%,正常情况下,不大可能有超过 10% 的单机都出现故障。
0.8. 服务调用失败处理手段
微服务相比于单体应用最大的不同之处在于,服务的调用从机器内部的本地调用变成了机器之间的远程方法调用,这个过程引入了两个不确定的因素:
- 调用的执行是在服务提供者一端,即使服务消费者本身是正常的,服务提供者也可能由于诸如 CPU、网络 I/O、磁盘、内存、网卡等硬件原因导致调用失败,还有可能由于本身程序执行问题比如 GC 暂停导致调用失败。
- 调用发生在两台机器之间,要经过网络传输,网络的复杂性是不可控的,网络丢包、延迟以及随时可能发生的瞬间抖动都有可能造成调用失败。
0.8.1. 超时
一次用户调用可能会被拆分成多个系统之间的服务调用,任何一次服务调用如果发生问题都可能会导致最后用户调用失败。
在微服务架构下,一个系统的问题会影响所有调用这个系统的服务消费者,不加以控制会引起整个系统雪崩。
针对服务调用都要设置超时时间,以避免依赖的服务迟迟没有返回调用结果,把服务消费者拖死。
超时时间的设定:
- 时间太短,可能会导致有些服务调用还没有来得及执行完就被丢弃
- 时间太长,可能导致服务消费者被拖垮
根据正常情况下,服务提供者的服务水平来找到合适的超时时间。按照服务提供者线上真实的服务水平,取 P999( 99.9%) 或者 P9999(99.99%) 的调用都在多少毫秒内返回为准。
0.8.2. 重试
设置超时时间可以起到及时止损的效果,但服务调用的结果还是失败了,大部分情况下,调用失败都是因为偶发的网络问题或者个别服务提供者节点有问题导致的,如果能换个节点再次访问说不定就能成功。
从概率论的角度来讲,假如一次服务调用失败的概率为 1%,那么连续两次服务调用失败的概率就是 0.01%,失败率降低到原来的 1%。
在实际服务调用时,要设置服务调用超时后的重试次数。
某个服务调用的超时时间设置为 100ms,重试次数设置为 1,那么当服务调用超过 100ms 后,服务消费者就会立即发起第二次服务调用,而不会再等待第一次调用返回的结果了。
0.8.3. 双发
服务消费者发起服务调都同时发起两次服务调用:
- 一方面可以提高调用的成功率
- 另一方面两次服务调用哪个先返回就采用哪次的返回结果,平均响应时间也要比一次调用更快
这样的话,一次调用会给后端服务两倍的压力,所要消耗的资源也是加倍的,所以一般情况下,这种“鲁莽”的双发是不可取的。
优化的双发,即“备份请求”(Backup Requests),大致思想是服务消费者发起一次服务调用后,在给定的时间内(这个设定的时间通常要比超时时间短得多)如果没有返回请求结果,那么服务消费者就立刻发起另一次服务调用。
比如超时时间取的是 P999,那么备份请求时间取的可能是 P99 或者 P90,这是因为如果在 P99 或者 P90 的时间内调用还没有返回结果,那么大概率可以认为这次请求属于慢请求,再次发起调用理论上返回要更快一些。
注意,备份请求要设置一个最大重试比例,以避免在服务端出现问题的时,导致请求量几乎翻倍,给服务提供者造成更大的压力。最大重试比例可以设置成15%,一方面能体现备份请求的优势,另一方面不会给服务提供者额外增加太大的压力。
0.8.4. 熔断
如果服务提供者出现故障,短时间内无法恢复时,无论是超时重试还是双发不但不能提高服务调用的成功率,反而会因为重试给服务提供者带来更大的压力,从而加剧故障。
针对这种情况,需要服务消费者能够探测到服务提供者发生故障,并短时间内停止请求,给服务提供者故障恢复的时间,待服务提供者恢复后,再继续请求。
这就好比一条电路,电流负载过高的话,保险丝就会熔断,以防止火灾的发生,所以这种手段就被叫作“熔断”。
0.8.4.1. 熔断的工作原理
- 把客户端的每一次服务调用用断路器封装起来,通过断路器来监控每一次服务调用。
- 如果某一段时间内,服务调用失败的次数达到一定阈值,那么断路器就会被触发,后续的服务调用就直接返回,也就不会再向服务提供者发起请求了。
- 根据熔断中断路器的状态来恢复服务调用。
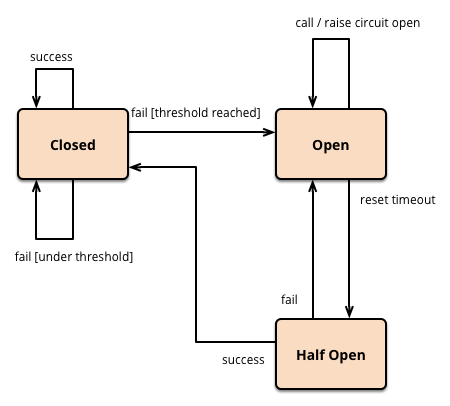
- Closed 状态:正常情况下,断路器是处于关闭状态的,偶发的调用失败也不影响。
- Open 状态:当服务调用失败次数达到一定阈值时,断路器就会处于开启状态,后续的服务调用就直接返回,不会向服务提供者发起请求。
- Half Open 状态:当断路器开启后,每隔一段时间,会进入半打开状态,这时候会向服务提供者发起探测调用,以确定服务提供者是否恢复正常。如果调用成功了,断路器就关闭;如果没有成功,断路器就继续保持开启状态,并等待下一个周期重新进入半打开状态。
断路器实现的关键就在于计算一段时间内服务调用的失败率, Hystrix 使用滑动窗口算法,如下图所示。
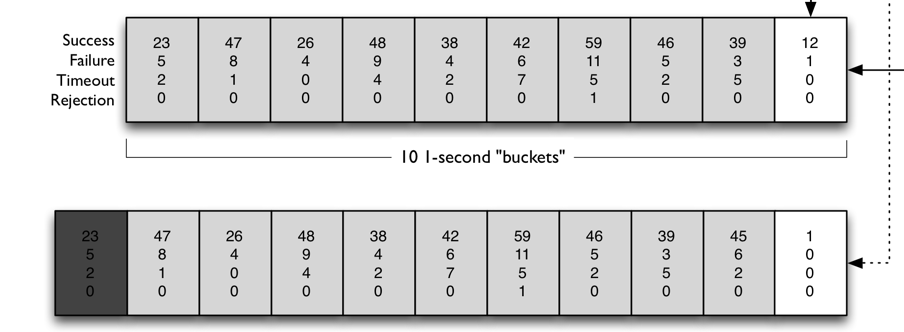
默认情况下,滑动窗口包含 10 个桶,每个桶时间宽度为 1 秒,每个桶内记录了这 1 秒内所有服务调用中成功的、失败的、超时的以及被线程拒绝的次数。
当新的 1 秒到来时,滑动窗口就会往前滑动,丢弃掉最旧的 1 个桶,把最新 1 个桶包含进来。
任意时刻,Hystrix 都会取滑动窗口内所有服务调用的失败率作为断路器开关状态的判断依据,这 10 个桶内记录的所有失败的、超时的、被线程拒绝的调用次数之和除以总的调用次数就是滑动窗口内所有服务的调用的失败率。
0.9. 管理服务配置
- 单体应用只需要管理一套配置
- 微服务每个系统都有自己的配置,并且各不相同,因为服务治理的需要,有些配置还需要动态改变,以达到动态降级、切流量、扩缩容等目的
0.9.1. 本地配置
服务配置管理方案:
- 把配置当作代码看待,随着应用程序代码一起发布。
- 把配置都抽离到单独的配置文件当中,使配置与代码分离。
无论是把配置定义在代码里,还是把配置从代码中抽离出来,都相当于把配置存在了应用程序的本地。
如果需要修改配置,就要重新走一遍代码或者配置的发布流程,在线上业务中这是一个很重的操作,相当于一次上线发布过程,甚至更繁琐,需要更谨慎。
如果能有一个集中管理配置的地方,如果需要修改配置,只需要在这个地方修改一下,线上服务就自动从这个地方同步过去,不需要走代码或者配置的发布流程,这就是下面的配置中心。
0.9.2. 配置中心
配置中心的思路:把服务的各种配置(如代码里配置的各种参数、服务降级的开关甚至依赖的资源等)都在一个地方统一进行管理。服务启动时,可以自动从配置中心中拉取所需的配置,并且如果有配置变更的情况,同样可以自动从配置中心拉取最新的配置信息,服务无须重新发布。
一般来讲,配置中心存储配置是按照 Group 来存储的,同一类配置放在一个 Group 下,以 K, V 键值对存储。
配置中心一般包含下面几个功能:
- 配置注册功能:配置中心对外提供接口
/config/service?action=register来完成配置注册功能,需要传递的参数包括配置对应的分组 Group,以及对应的 Key、Value 值。 - 配置反注册功能:配置中心对外提供接口
config/service?action=unregister来完成配置反注册功能,需要传递的参数包括配置对象的分组 Group,以及对应的 Key。 - 配置查看功能:配置中心对外提供接口
config/service?action=lookup来完成配置查看功能,需要传递的参数包括配置对象的分组 Group,以及对应的 Key。 - 配置变更订阅功能:配置中心对外提供接口
config/service?action=getSign来完成配置变更订阅接口,客户端本地会保存一个配置对象的分组 Group 的 sign 值,同时每隔一段时间去配置中心拉取该 Group 的 sign 值,与本地保存的 sign 值做对比。一旦配置中心中的 sign 值与本地的 sign 值不同,客户端就会从配置中心拉取最新的配置信息。
配置中心可以便于管理服务的配置信息,如果要修改配置信息,只需同配置中心交互,应用程序会通过订阅配置中心的配置,自动完成配置更新。
0.9.2.1. 典型场景
- 资源服务化。在应用规模不大的时候,所依赖的资源对应的 IP 可以直接写在配置里。但当业务规模发展到一定程度后,所依赖的这些资源的数量也开始急剧膨胀,这个时候如果采用的是本地配置的话,就需要去更改本地配置,把不可用的 IP 改成可用的 IP,然后发布新的配置,这样的过程十分不便。
- 业务动态降级。微服务架构下,拆分的服务越多,出现故障的概率就越大,因此需要有对应的服务治理手段,比如要具备动态降级能力,在依赖的服务出现故障的情况下,可以快速降级对这个服务的调用,从而保证不受影响。为此,服务消费者可以通过订阅依赖服务是否降级的配置,当依赖服务出现故障的时候,通过向配置中心下达指令,修改服务的配置为降级状态,这样服务消费者就可以订阅到配置的变更,从而降级对该服务的调用。
- 分组流量切换。为了保证异地多活以及本地机房调用,一般服务提供者的部署会按照 IDC 维度进行部署,每个 IDC 划分为一个分组,这样的话,如果一个 IDC 出现故障,可以把故障 IDC 机房的调用切换到其他正常 IDC。为此,服务消费者可以通过订阅依赖服务的分组配置,当依赖服务的分组配置发生变更时,服务消费者就对应的把调用切换到新的分组,从而实现分组流量切换。
0.9.3. 技术选型
- Spring Cloud Config。Spring Cloud 中使用的配置中心组件,只支持 Java 语言,配置存储在 git 中,变更配置也需要通过 git 操作,如果配置中心有配置变更,需要手动刷新。
- Disconf。百度开源的分布式配置管理平台,只支持 Java 语言,基于 Zookeeper 来实现配置变更实时推送给订阅的客户端,并且可以通过统一的管理界面来修改配置中心的配置。
- Apollo。携程开源的分布式配置中心,支持 Java 和.Net 语言,客户端和配置中心通过 HTTP 长连接实现实时推送,并且有统一的管理界面来实现配置管理。
Spring Cloud Config 作为配置中心的功能比较弱,只能通过 git 命令操作,而且变更配置的话还需要手动刷新,如果不是采用 Spring Cloud 框架的话不建议选择。 而 Disconf 和 Apollo 的功能都比较强大,其中 Apollo 对 Spring Boot 的支持比较好,如果应用本身采用的是 Spring Boot 开发的话,集成 Apollo 会更容易一些。
0.10. 微服务治理平台
单体应用改造为微服务架构后,服务调用从本地调用变成了远程方法调用后,面临的各种不确定因素变多:
- 需要能够监控各个服务的实时运行状态、服务调用的链路和拓扑图
- 需要在出现故障时,能够快速定位故障的原因并可以通过诸如降级、限流、切流量、扩容等手段快速干预止损
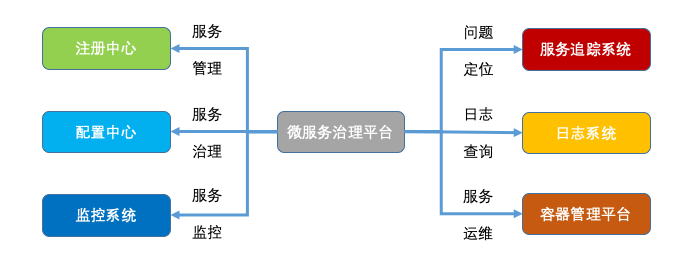
微服务治理平台就是与服务打交道的统一入口,无论是开发人员还是运维人员,都能通过这个平台对服务进行各种操作:
- 开发人员可以通过这个平台对服务进行降级操作
- 运维人员可以通过这个平台对服务进行上下线操作,而不需要关心这个操作背后的具体实现
0.10.1. 服务管理
通过微服务治理平台,可以调用注册中心提供的各种管理接口来实现服务的管理。
服务管理一般包括以下几种操作:
- 服务上下线。
- 节点添加 / 删除
- 服务查询
- 服务节点查询
0.10.2. 服务治理
通过微服务治理平台,可以调用配置中心提供的接口,动态地修改各种配置来实现服务的治理。
服务治理手段包括以下几种:
- 限流
- 降级
- 切流量
0.10.3. 服务监控
微服务治理平台一般包括两个层面的监控:
- 整体监控,比如服务依赖拓扑图,将整个系统内服务间的调用关系和依赖关系进行可视化的展示,可以使用服务追踪系统提供的服务依赖拓扑图
- 具体服务监控,比如服务的 QPS、AvgTime、P999 等监控指标,可以通过 Grafana 等监控系统 UI 来展示
0.10.4. 问题定位
微服务治理平台实现问题定位,可以从两个方面来进行:
- 宏观层面,即通过服务监控来发觉异常,比如某个服务的平均耗时异常导致调用失败
- 微观层面,即通过服务追踪来具体定位一次用户请求失败具体是因为服务调用全链路的哪一层导致的
0.10.5. 日志查询
微服务治理平台可以通过接入类似 ELK 的日志系统,能够实时地查询某个用户的请求的详细信息或者某一类用户请求的数据统计。
0.10.6. 服务运维
微服务治理平台可以调用容器管理平台,来实现常见的运维操作。
服务运维主要包括下面几种操作:
- 发布部署。当服务有功能变更,需要重新发布部署的时候,可以调用容器管理平台分批按比例进行重新部署,然后发布到线上。
- 扩缩容。在流量增加或者减少的时候,需要相应地增加或者缩减服务在线上部署的实例,这时候可以调用容器管理平台来扩容或者缩容。
0.10.7. 搭建微服务治理平台
微服务治理平台关键在于:
- 封装对微服务架构内的各个基础设施组件的调用,对外提供统一的服务操作 API
- 提供可视化的界面,以方便开发人员和运维人员操作
一个微服务治理平台的组成主要包括三部分:
- Web Portal 层
- API 层
- 数据存储 DB 层
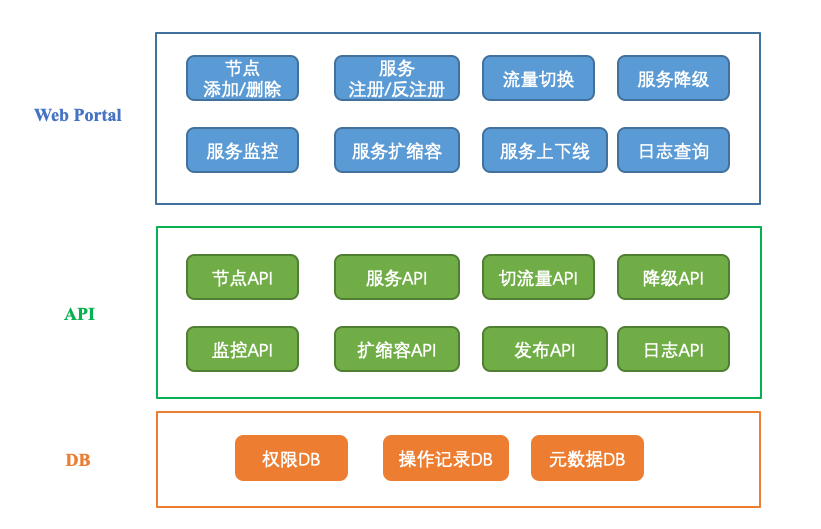
第一层:Web Portal。也就是微服务治理平台的前端展示层,包含以下功能界面:
- 服务管理界面,进行节点的操作,比如查询节点、删除节点
- 服务治理界面,进行服务治理操作,比如切流量、降级等,可查看操作记录
- 服务监控界面,查看服务的详细信息,比如 QPS、AvgTime、耗时分布区间以及 P999 等
- 服务运维界面,执行服务的扩缩容操作,可查看操作记录
第二层,API。也就是微服务治理平台的后端服务层,这一层提供接口给 Web Portal 调用,包含以下接口功能:
- 添加服务接口,这个接口会调用注册中心提供的服务添加接口来新发布一个服务
- 删除服务接口,这个接口会调用注册中心提供的服务注销接口来下线一个服务
- 服务降级 / 限流 / 切流量接口,这几个接口会调用配置中心提供的配置修改接口,来修改对应服务的配置,然后订阅这个服务的消费者就会从配置中心拉取最新的配置,从而实现降级、限流以及流量切换
- 服务扩缩容接口,这个接口会调用容器平台提供的扩缩容接口,来实现服务的实例添加和删除
- 服务部署接口,这个接口会调用容器平台提供的上线部署接口,来实现服务的线上部署
第三层,DB。也就是微服务治理平台的数据存储层,微服务治理平台不仅需要调用其他组件提供的接口,还需要存储一些基本信息,主要分为以下几种:
- 用户权限,微服务治理平台的功能十分强大,所以要对用户权限(浏览、更改【对应到具体的服务】以及管理员)进行管理。
- 操作记录,记录用户在平台上所进行的变更操作,比如降级记录、扩缩容记录、切流量记录等
- 元数据,用来把服务在各个系统中对应的记录映射到微服务治理平台中,统一进行管理。比如某个服务在监控系统里可能有个特殊标识,在注册中心里又使用了另外一个标识,为了统一就需要在微服务治理平台统一进行转换,然后进行数据串联。
0.10.8. 总结
一个微服务框架是否成熟,除了要看它是否具备服务治理能力,还要看是否有强大的微服务治理平台。
因为微服务治理平台能够将多个系统整合在一起,无论是对开发还是运维来说,都能起到事半功倍的作用,这也是当前大部分开源微服务框架所欠缺的部分,所以对于大部分团队来说,都需要自己搭建微服务治理平台。