05-事件驱动数据管理
这是关于使用微服务构建应用程序的系列文章的第五篇。第一篇文章介绍了微服务架构模式,并讨论了使用微服务的优缺点。第二篇和第三篇文章描述了微服务架构中通信的不同方面。第四篇文章探讨了服务发现的密切相关问题。在本文中,研究微服务架构中出现的分布式数据管理问题。
微服务与分布式数据管理问题
单体应用程序通常具有单个关系数据库。使用关系数据库的一个主要好处是:应用程序可以使用ACID事务,它提供了一些重要保证:
- 原子性:自动进行更改
- 一致性:数据库的状态始终保持一致
- 隔离性:即使事务同时执行也像串行执行
- 持久性:一旦事务提交,它就不会被撤消
因此,应用程序可以简单地开始事务,更改(插入、更新和删除)多行,并提交事务。
使用关系数据库的另一个好处是:它提供SQL(一种丰富的、声明性的、标准化的查询语言)。可以轻松编写来自多个表的数据的组合查询,然后,RDBMS(query planner)确定执行查询的最佳方式,不必担心诸如如何访问数据库之类的低级细节。因为所有应用程序的数据都在一个数据库中,所以很容易查询。
- 不幸的是,当我们转向微服务架构时,数据访问变得更加复杂。这是因为每个微服务拥有的数据对于该微服务是私有的,并且只能通过其API访问,封装数据可确保微服务松散耦合,并且可以彼此独立地迭代更新。如果多个服务访问相同的数据,则架构更新需要对所有服务进行耗时的协同更新。
更糟糕的是,不同的微服务通常使用不同类型的数据库。现代应用程序存储和处理各种数据,关系数据库并不总是最佳选择。对于某些用例,特定的NoSQL数据库可能具有更方便的数据模型,并提供更好的性能和可伸缩性。例如:
- 存储和查询文本的服务使用文本搜索引擎(如Elasticsearch)是有意义的。
- 存储社交图数据的服务应该使用图形数据库,例如Neo4j。
因此,基于微服务的应用程序通常使用SQL和NoSQL数据库的混合,即所谓的多语言持久性方法。用于数据存储的分区多字节持久架构具有许多优点,包括:
- 松散耦合的服务
- 更好的性能和可扩展性
但是,它确实引入了一些分布式数据管理挑战。
第一个挑战是如何实现维护多个服务之间一致性的业务事务。要了解这个问题,让我们来看一个在线B2B商店的例子。
客户服务部门维护有关的客户信息表,包括其信用额度。订单服务管理订单相关信息,并且必须验证新订单是否超过客户的信用额度。
- 在单体应用中,订单服务可以简单地使用ACID事务来检查可用信用额度并创建订单。
- 在微服务中,ORDER和CUSTOMER表对其各自的服务是私有的,如下图所示。
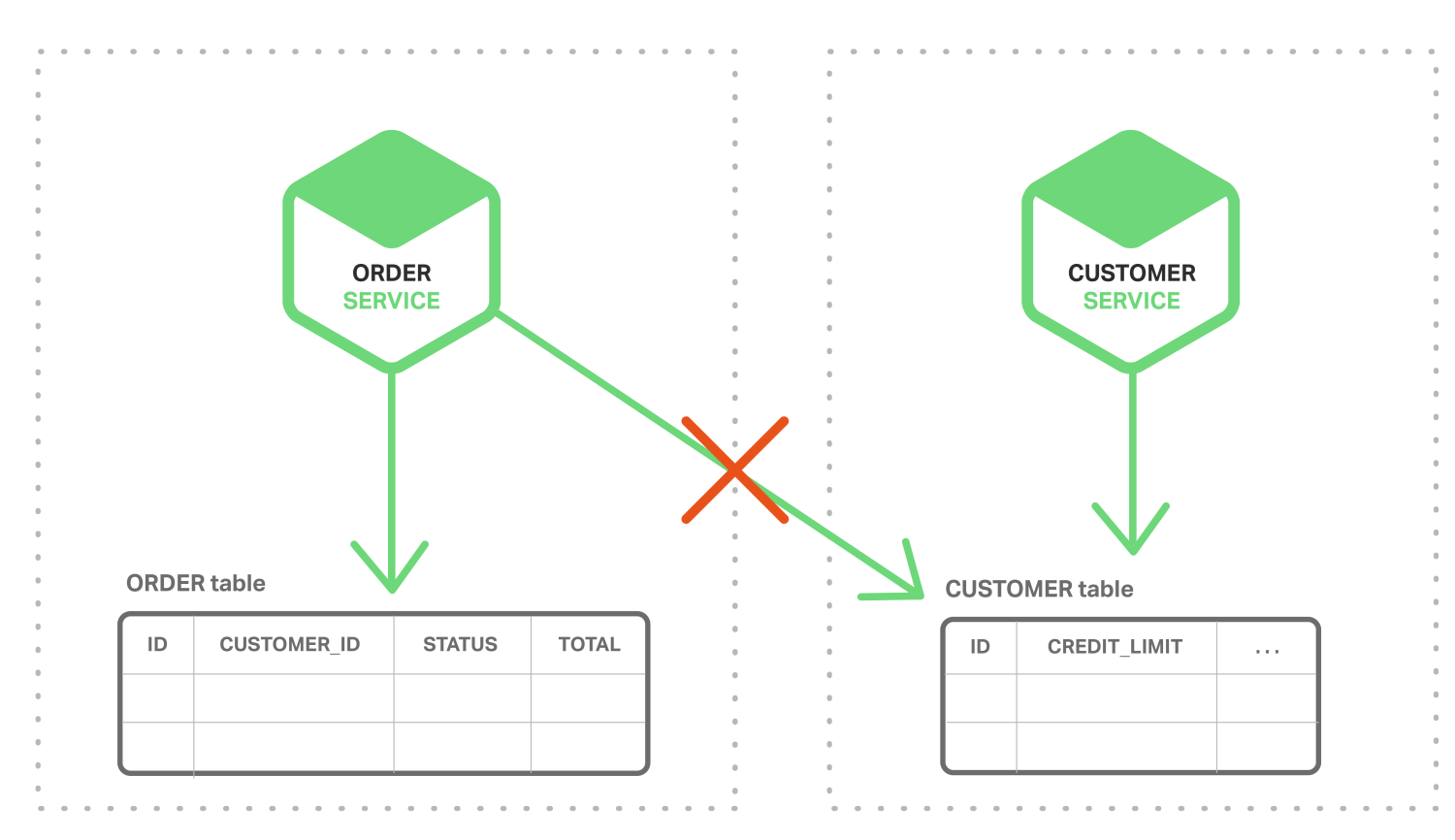
订单服务无法直接访问CUSTOMER表。它只能使用客户服务提供的API。订单服务可能使用分布式事务,也称为两阶段提交(2PC),但是,2PC在现代应用中通常不是一个可行的选择。
CAP定理要求在可用性和ACID样式的一致性之间进行选择,并且可用性通常是更好的选择。
此外,许多现代技术,如大多数NoSQL数据库,都不支持分布式事物。维护服务和数据库之间的数据一致性至关重要,因此我们需要另一种解决方案。
第二个挑战是如何实现从多个服务检索查询数据。例如:
- 假设应用程序需要显示客户及其最近的订单。
- 如果订单服务提供用于检索客户订单的API,那么可以使用应用程序端联接来检索此数据。
应用程序从客户服务中检索客户,并从订单服务中检索客户的订单。
但是,假设订单服务仅支持按主键查找订单(可能它使用的NoSQL数据库仅支持基于主键的检索)。在这种情况下,没有明显的方法来检索所需的数据。
事件驱动体系结构
对于许多应用程序,解决方案是使用事件驱动的体系结构。在这种体系结构中,微服务在发生重要事件时发布事件(例如,在更新业务实体时)。其他微服务订阅这些事件,当微服务接收事件时,它可以更新自己的业务实体,这样的更新操作可能触发发布更多事件。
可以使用事件来实现跨多个服务的业务事务。交易包含一系列步骤,每个步骤都包括一个微服务更新业务实体并发布触发下一步的事件。
以下序列图显示了在创建订单时如何使用事件驱动方法检查可用额度。微服务通过消息代理服务(Message Broker)交换事件。
- 订单服务创建状态为NEW的订单并发布订单创建事件。
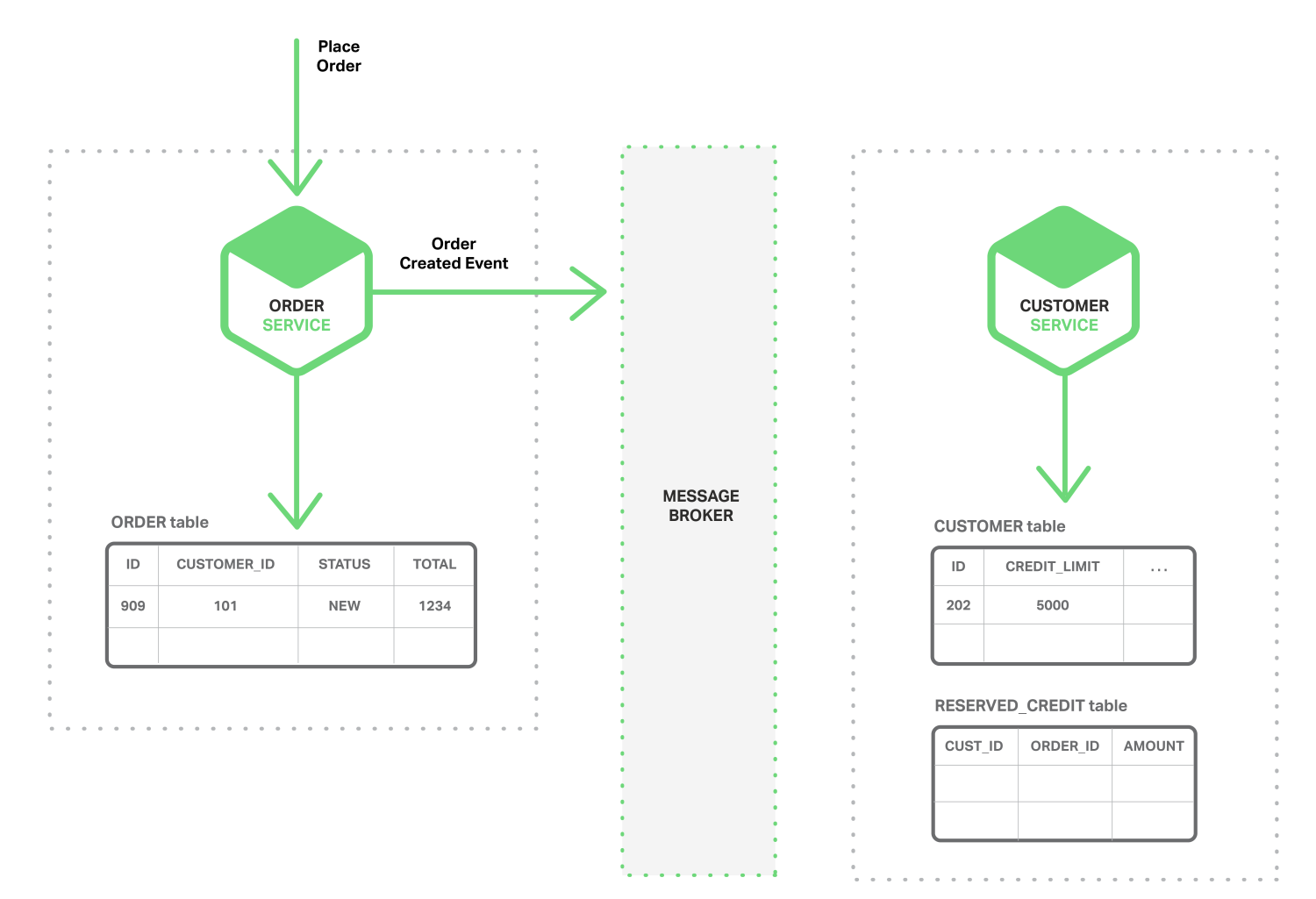
- 客户服务使用订单创建事件,保留订单信用额度,并发布信用额度保留事件。
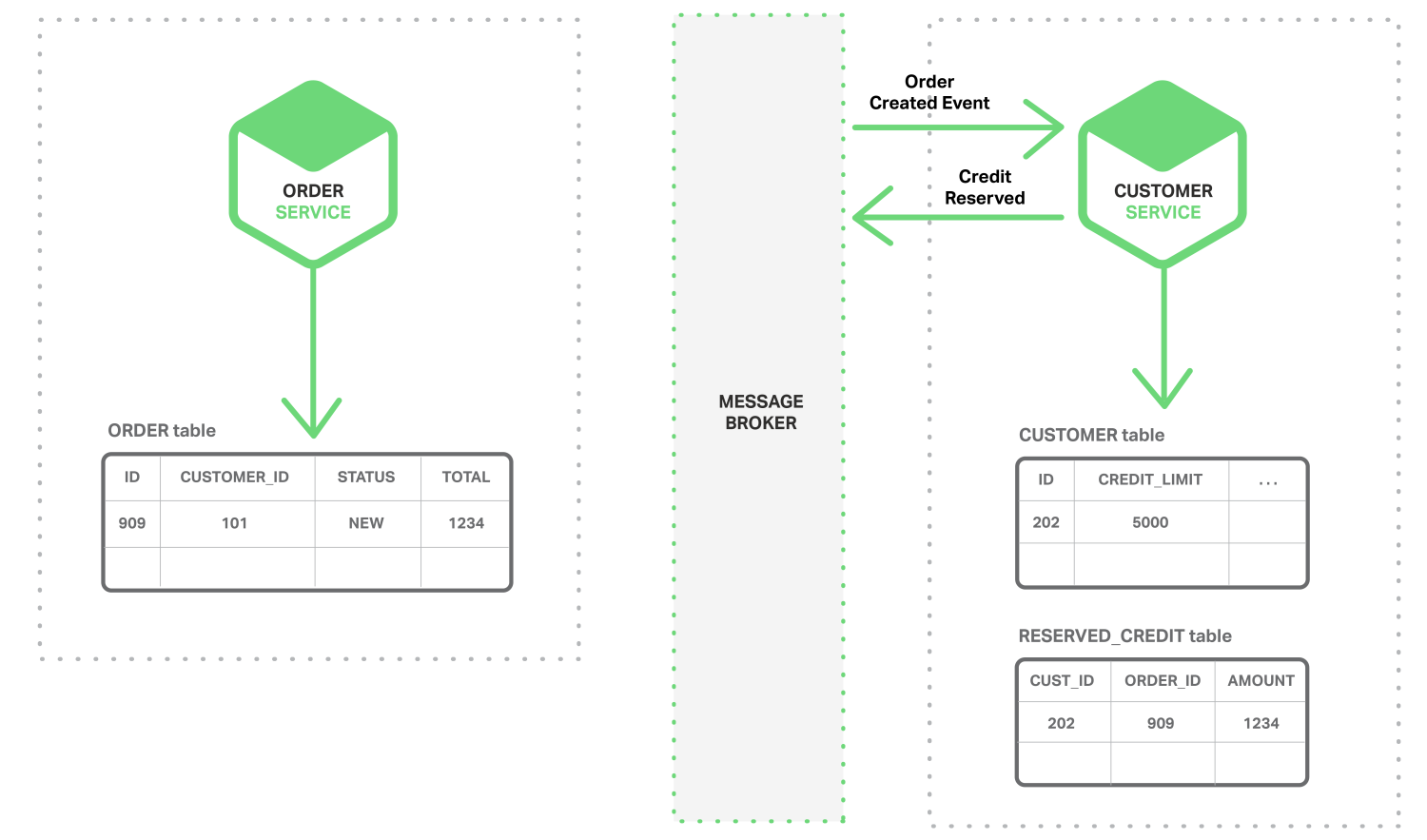
- 订单服务使用信用额度保留事件,并将订单状态更改为OPEN。
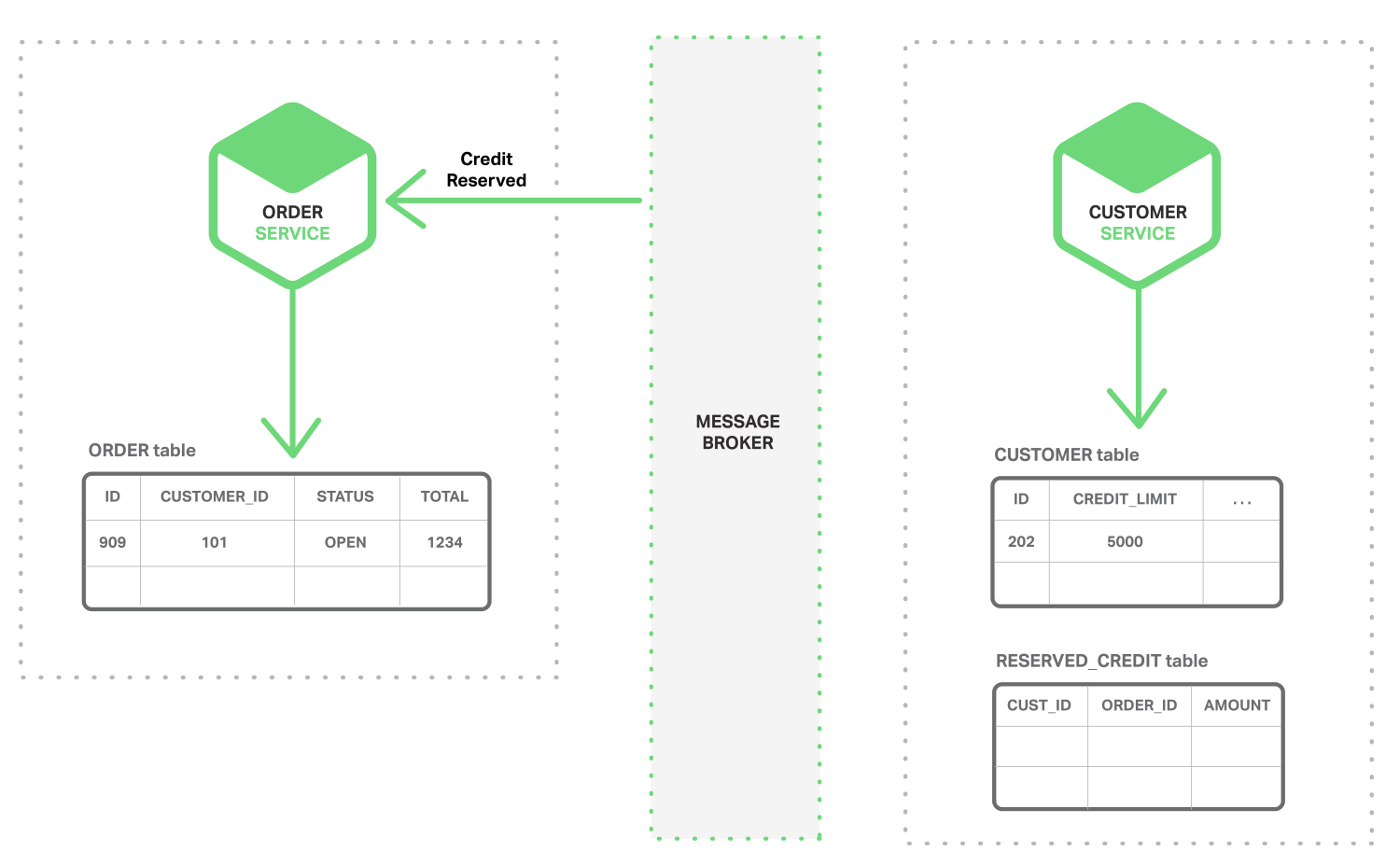
更复杂的情况可能涉及其他步骤,例如,在检查客户信用额度的同时预订库存。
如果:
- (a)每个服务原子地更新数据库并发布事件(稍后会更多)
(b)消息代理服务保证事件至少被传递一次
那么可以实现跨多个服务的业务事务。
值得注意的是,这不是ACID事务。它们提供了许多较弱的保证,例如最终的一致性。此事务模型称为BASE模型。
还可以使用事件来维护预加入多个微服务所拥有的数据的物化视图,维护视图的服务订阅相关事件并更新视图。例如,维护客户订单视图的客户订单视图更新程序订阅并处理客户服务和订单服务发布的事件。
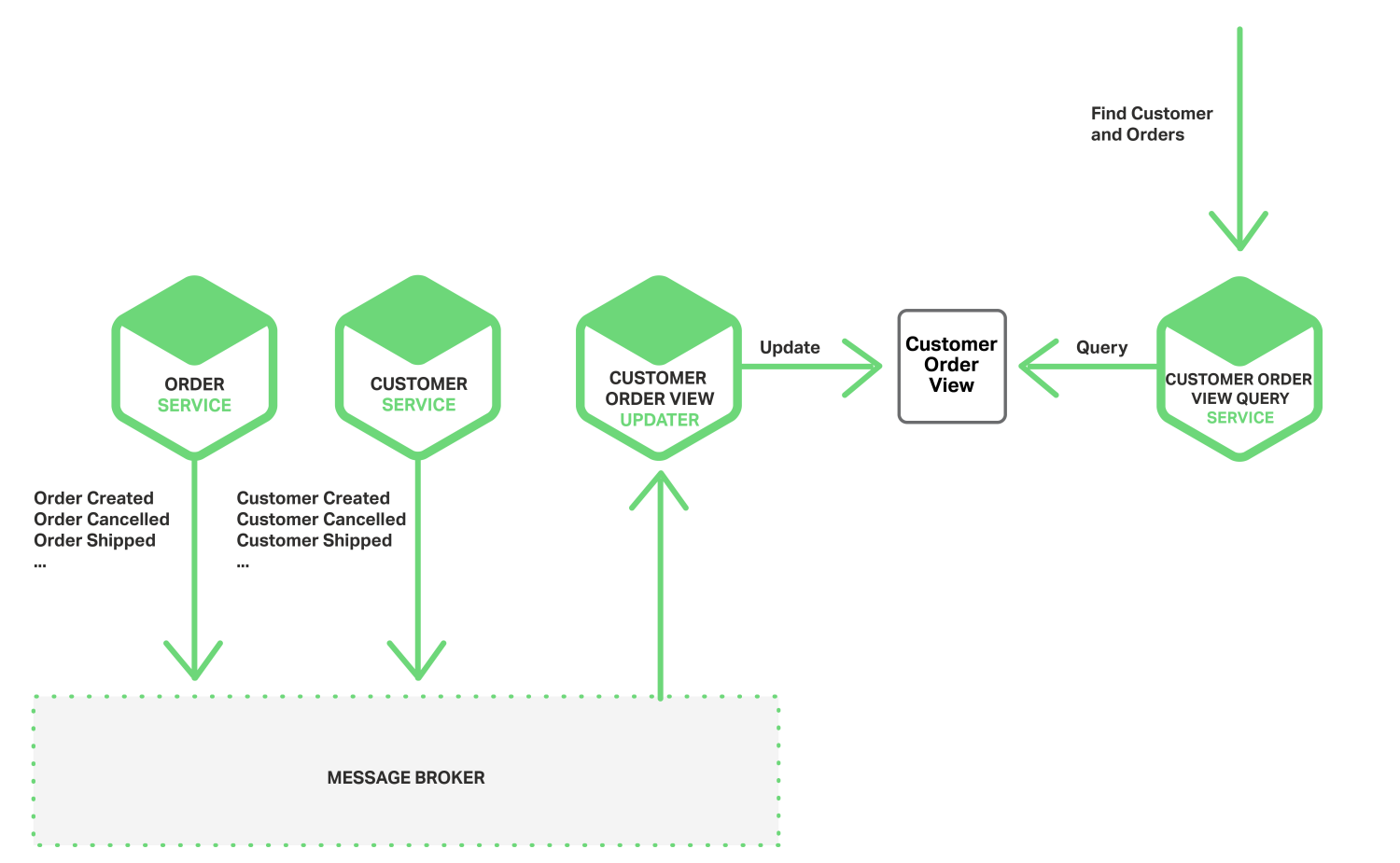
当客户订单视图更新程序服务收到客户或订单事件时,它会更新客户订单视图数据。可以使用文档数据库(如MongoDB)实现客户订单视图,并为每个客户存储一个文档。客户订单视图查询服务通过查询客户订单视图数据存储来处理客户和最近订单的请求。
事件驱动的体系结构优点:
- 它支持跨多个服务的事务的实现,并提供最终的一致性
- 它还使应用程序能够维护物化视图
事件驱动的体系结构缺点:
- 编程模型比使用ACID事务时更复杂:
- 必须实现事务补偿机制以从应用程序级的故障中恢复;例如,如果信用额度检查失败,则必须取消客户订单。
- 必须处理不一致的数据;因为事务所做的更改是可见的,如果应用程序从尚未更新的物化视图中读取,则应用程序也会看到不一致。
- 订阅事件的服务必须检测并忽略重复的事件。
实现原子性
在事件驱动的体系结构中,还存在数据库的原子更新操作和发布事件的问题。例如:
- 订单服务必须在ORDER表中插入一行数据
并发布Order Created事件
这两个操作必须以原子方式完成。
如果服务在更新数据库之后但在发布事件之前崩溃,则系统会变得不一致。确保原子性的标准方法是使用涉及数据库和消息代理服务的分布式事务。但是,由于上述原因,例如CAP定理,这正是我们不想做的。
使用本地事务发布事件
实现原子性一种方法是:应用程序使用仅涉及本地事务的多步骤过程来发布事件。诀窍是在存储业务实体状态的数据库中有一个EVENT表,它充当消息队列。
应用程序开始(本地)数据库事务,更新业务实体的状态,将事件插入EVENT表,并提交事务。单独的应用程序线程或进程查询EVENT表,将事件发布到消息代理服务,然后使用本地事务将事件标记为已发布。下图显示了该设计。
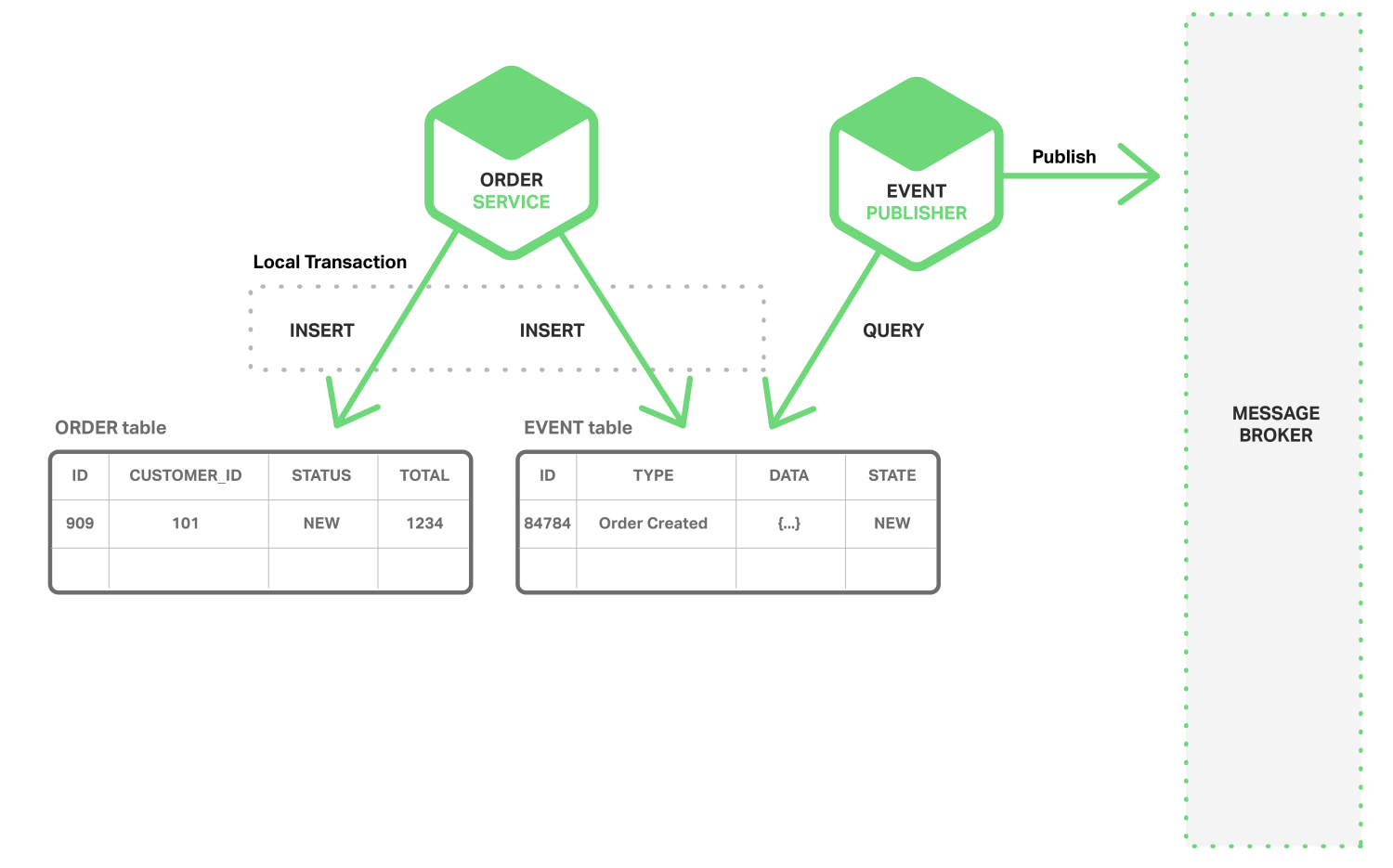
订单服务将一行插入ORDER表,并将Order Created事件插入EVENT表。事件推送线程或进程在EVENT表中查询到未发布的事件,并将事件发布出去,然后更新EVENT表以将事件标记为已发布。
这种方法的优缺点:
- 好处:它保证在不依赖于分布式事务的情况下为每次更新发布事件。并且,应用程序发布的是事务级别的事件。
- 缺点:它可能容易出错,因为开发人员必须记住发布事件。这种方法的局限性在于,由于其有限的事务和查询功能,在使用某些NoSQL数据库时实施起来很困难。
通过让应用程序使用本地事务来更新状态和发布事件,此方法消除了对分布式事务的需求。现在让我们看一下通过让应用程序简单地更新状态来实现原子性的方法。
挖掘数据库事务日志
在没有分布式事务的情况下实现原子性的另一种方法是由挖掘数据库事务或提交日志的线程或进程发布事件。
应用程序更新数据库,这会导致更改操作记录在数据库的事务日志中。Transaction Log Miner线程或进程读取事务日志并将事件发布到消息消息代理服务。下图显示了该设计。
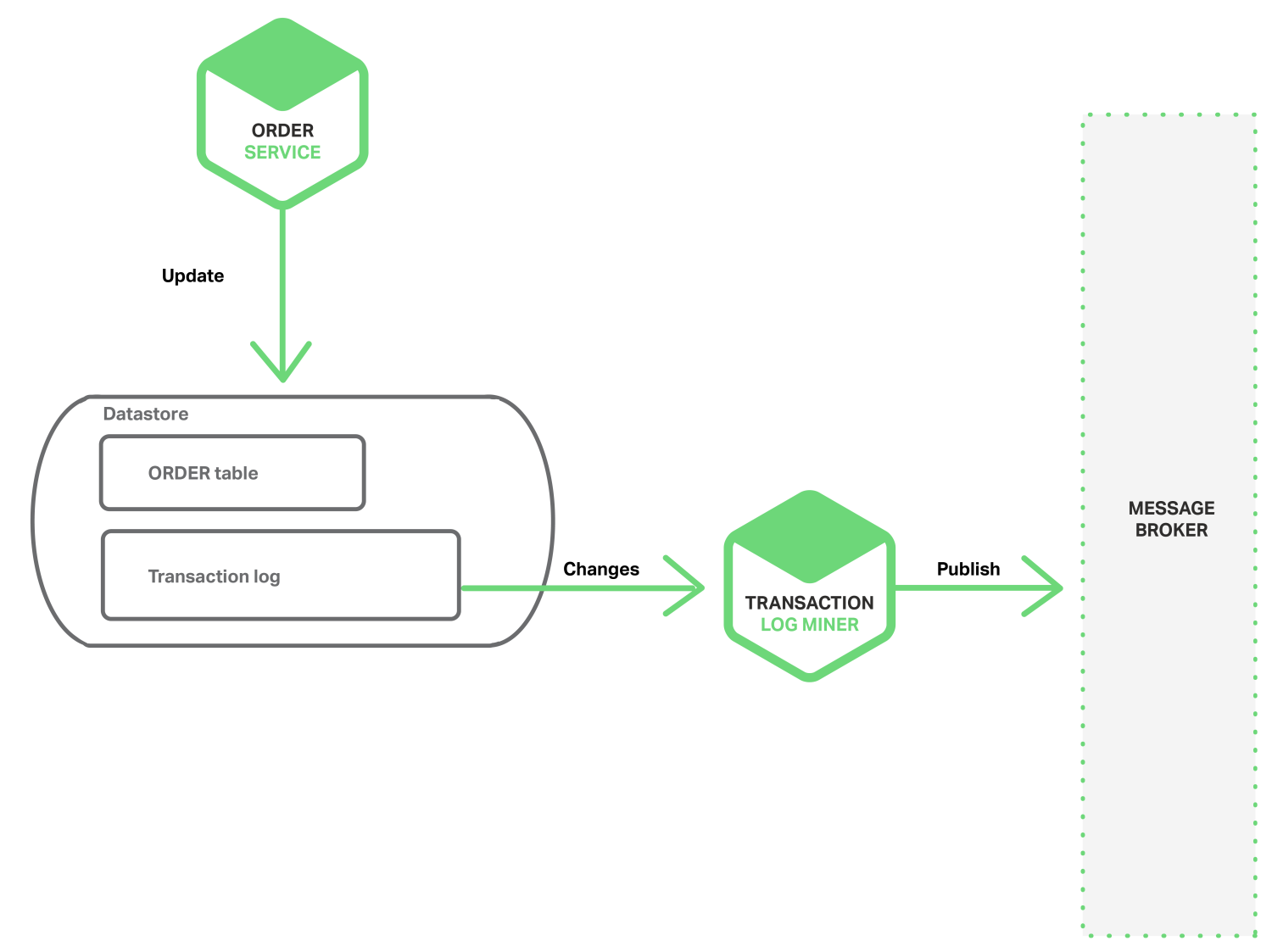
LinkedIn Databus项目。Databus挖掘Oracle事务日志并发布与更改相对应的事件。LinkedIn使用Databus来保持各种派生数据存储与记录系统一致。
AWS DynamoDB中的流机制,它是一个托管的NoSQL数据库。DynamoDB流包含在过去24小时内对DynamoDB表中的项目进行的按时间排序的更改(创建,更新和删除操作)序列。应用程序可以从流中读取这些更改,例如,将它们作为事件发布。
事务日志挖掘的优缺点:
- 好处:它保证在不使用分布式事务的情况下为每次更新发布事件。事务日志挖掘还可以通过将事件发布与应用程序的业务逻辑分离来简化应用程序。
- 缺点:事务日志的格式是每个数据库专有的,甚至可以在数据库版本之间进行更改。此外,从事务日志中记录的低级更新中反向设计高级业务事件可能很困难。
事务日志挖掘通过让应用程序做一件事来消除对分布式事务的需求:更新数据库。现在让我们看一个消除更新并仅依赖于事件的不同方法。
使用事件溯源
事件溯源通过使用完全不同的,以事件为中心的方法来保持业务实体,从而在没有分布式事务的情况下实现原子性。应用程序存储一系列状态改变事件,而不是存储实体的当前状态。应用程序通过重放事件来重建实体的当前状态,每当业务实体的状态发生变化时,都会在事件列表中附加一个新事件。由于保存事件是单个操作,因此它本质上是原子的。
要了解事件溯源的工作原理,请将Order实体视为示例:
- 在传统方法中,每个订单映射到ORDER表中的行(例如,ORDER_LINE_ITEM表中的行)。
- 在使用事件溯源时,订单服务会以状态更改事件的形式存储订单:已创建,已批准,已发货,已取消。每个事件都包含足够的数据来重建订单的状态。
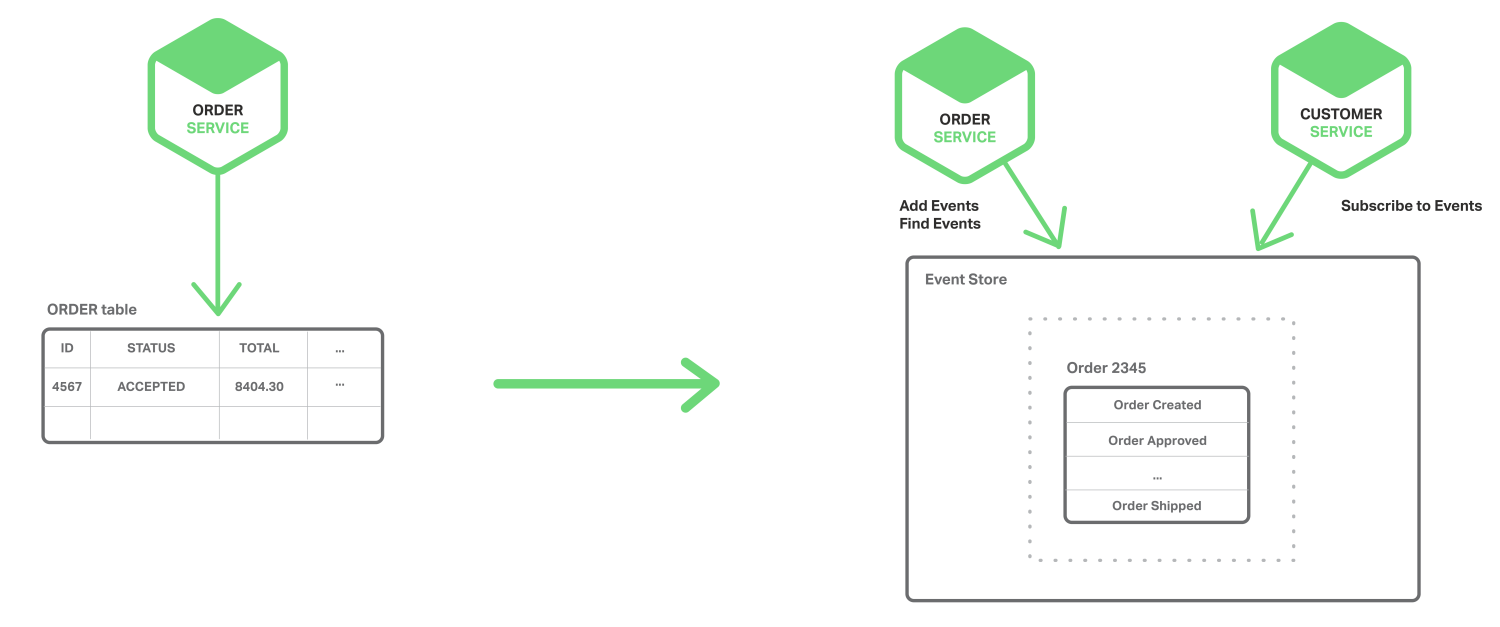
事件持续存储在事件存储器中,事件存储器是保存事件的数据库。
事件存储器有一个用于添加和检索实体事件的API。事件存储器的行为与我们之前描述的体系结构中的消息代理服务相似,它提供了一个API,使服务可以订阅事件。事件存储器向所有感兴趣的订阅者提供所有事件状态变更数据。事件存储器是事件驱动的微服务架构的支柱。
事件溯源的好处:
- 它解决了实现事件驱动架构的关键问题,可以在状态变更时可靠地发布事件
- 它解决了微服务架构中的数据一致性问题
- 它持久存储事件而不是域对象,所以它避免了对象-关系不匹配问题
- 它还提供对业务实体更改时100%可靠的审计日志,并且可以实现在任何时间点确定实体状态的时态查询功能
- 业务逻辑由交换事件的松散耦合的业务实体组成,这使得从单体应用迁移到微服务架构变得更加容易
事件溯源的缺点:这是一种不同的,不熟悉的编程风格,因此有一定学习成本。事件存储仅直接支持按主键查找业务实体,必须使用命令查询责任隔离(CQRS)来实现查询。因此,应用程序必须处理最终一致的数据。
总结
在微服务架构中,每个微服务都有自己的私有数据存储。不同的微服务可能使用不同的SQL和NoSQL数据库。虽然此数据库体系结构具有显着优势,但它会产生一些分布式数据管问题:
- 第一个挑战是:如何实现维护多个服务之间一致性的业务事务。
- 第二个挑战是:如何实现从多个服务检索数据的查询。
对于许多应用程序,解决方案是使用事件驱动的体系结构。
实现事件驱动架构的一个挑战是:如何以原子方式更新状态以及如何发布事件。有几种方法可以实现此目的,包括:
- 将数据库用作消息队列
- 数据库事务日志挖掘
- 事件溯源
在未来的博客文章中,我们将继续深入研究微服务的其他方面。