02-Go-kit架构设计
简介:Go kit核心概念
如果之前使用的是MVC样式框架,如:
- Symfony(PHP)
- Rails(Ruby)
- Django(Python)
那么首先要知道的是Go kit不是MVC框架。相反,Go kit服务分为三层:
- 传输层(Transport):这里可以用各种不同的通信方式,如 HTTP REST 接口或者 gRPC 接口(这是个很大的优点,方便切换成任何通信协议)
- 端点层(Endpoint):类似于 Controller 里面主要实现各种接口的 handler,负责
req/resp格式的转换(同时也是被吐槽繁杂的原因所在) - 服务层(Service):实现业务逻辑的地方
请求在第一层进入服务,然后流向第三层,而响应则是相反的过程。
这可能还会有调整,但是一旦懂了这些概念,便会发现Go kit的设计非常适合现代软件设计:微服务和所谓的优雅的单体架构。
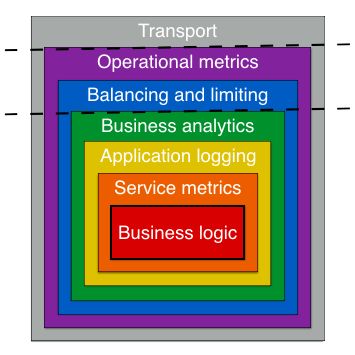
从下面的架构图来看,其中可以注意下中间件:类似于常见框架中的中间件模式,通常用来记录日志、限制频率、负载均衡以及分布式追踪等等,主要在 Endpoint 以及 Service 中实现。
依赖注入
太多的经验告诉我们,各个模块之间应该是 低耦合、高内聚,于是,Go kit 鼓励在 main 函数里面实现所有的组装,所有的模块的依赖都需要通过参数传入其它模块,减少甚至消灭所有全局状态,从根本上避免技术债务。
同时还有个很大的好处:便于测试,只要 mock 传入的依赖参数即可。
传输
传输域绑定到HTTP或gRPC之类的具体传输方式上,来决定使用哪种方式提供服务请求。在微服务可能支持一个或者多个传输方式的世界中,这是非常强大的。可以在单个微服务中支持旧版的HTTP API和新版的RPC服务。
在实现Restful HTTP API时,路由是在HTTP传输中定义的,最常见的情况是在HTTP的路由器中定义具体的路由,如下所示:
r.Methods("POST").Path("/profiles/").Handler(httptransport.NewServer(
e.PostProfileEndpoint,
decodePostProfileRequest,
encodeResponse,
options...,
))支持的传输协议
Go kit附带了对HTTP,gRPC,Thrift和net/rpc的支持。添加对新传输的支持很简单;如果需要的东西还没有提供,就提出一个issue。
端点
端点就像是控制器上的处理程序,它是安全且抗逻辑脆弱性的。如果实现了两种传输(HTTP和gRPC),那么可能有两种方法将请求发送到同一个端点。
它是Go-kit最重要的一层,是一个抽象的接收请求返回响应的函数类型,在这个定义的函数类型里面会去调用Service层的方法,组装成Response返回,Go-kit中所有中间件组件都是通过装饰者模式注入的。
服务
服务是实现所有业务逻辑的地方,可以理解为单体web框架中的控制器部分。在Go kit中,服务通常被建模为接口(interface),并且这些接口的实现包含业务逻辑。
Go kit的服务应该努力遵守“清洁架构”或者“六角架构”,也就是说,业务逻辑应该不了解端点或传输域的概念,服务不应该知道HTTP标头或gRPC错误代码。
中间件
Go kit试图通过使用中间件(修饰器)模式来严格分离关注点。中间件可以包装端点或服务以添加功能,例如日志记录、速率限制、负载均衡或分布式追踪。在端点或服务周围链接多个中间件是很常见的。
工具包
作为一个工具包,Go-kit提供了很多微服务工具组件。
| 组件名称 | 描述 |
|---|---|
| auth | 认证器(basic、jwt) |
| circuitbreaker | 回路熔断器 |
| log | 日志记录器 |
| metrics | 程序检测器 |
| ratelimit | 限流器 |
| sd | 服务发现器 |
| tracing | 分布式链路追踪器 |
| util | 连接相关工具 |
设计:Go kit微服务如何建模
综合所有这些概念,我们看到Go kit微服务的建模就像洋葱一样,有很多层。这些层可以分为三个域。
- 最里面是服务域:一切都基于特定的服务定义,所有业务逻辑都在此实现
- 中间是端点域:将服务的每种方法抽象到通用端点,它也是实现安全和防脆弱逻辑的地方
- 最外部是传输域:端点绑定到诸如HTTP或gRPC之类的具体传输协议的地方
可以通过定义服务的接口并提供具体的代码实现来实现核心业务逻辑。 然后,编写服务中间件以提供其他功能,例如日志记录,分析,检测,这些都需要业务领域的知识。
Go kit提供了端点和传输域中间件,以实现速率限制,断路器,负载均衡和分布式跟踪等功能,而所有这些功能通常都与业务领域无关。
简而言之,Go kit试图通过精心使用中间件(或修饰器)模式来强制将关注点严格分离。
依赖注入:为什么func main总是那么大
Go kit鼓励将服务设计为多个交互组件,包括多个单一用途的中间件。 经验告诉我们,在微服务中定义并连接组件最好方式是在main函数主体中显式声明各组件的依赖关系。
控制反转是其他框架的常见功能,可通过依赖注入或服务定位器模式实现。 但是在Go kit中,应该在main函数中将整个组件图连接起来。 这种风格强化了两个重要的优点:
- 通过严格保持组件生命周期处于main函数中,可以避免依赖全局状态作为捷径,这对于可测试性至关重要。
- 而且如果组件的作用域是main,则将它们作为对其他组件依赖的唯一方法是,作为参数显式传递给构造函数,这使依赖关系保持明确,从而在启动之前消除了很多技术债务。
例如,假设我们具有以下组件:
- Logger
- TodoService, 实现服务接口
- LoggingMiddleware,实现服务接口,依赖Logger和具体的TodoService
- Endpoints, 依赖服务接口
- HTTP (transport), 依赖端点
那么main函数应该以以下方式编写:
logger := log.NewLogger(...)
var service todo.Service // interface
service = todo.NewService() // concrete struct
service = todo.NewLoggingMiddleware(logger)(service)
endpoints := todo.NewEndpoints(service)
transport := todo.NewHTTPTransport(endpoints)以拥有潜在的巨大main函数为代价,显式声明组件的连接。有关更通用的Go设计技巧,请参阅六周年:Go最佳实践。
部署
这完全取决于你。
- 可以构建一个静态二进制文件,将其scp到服务器,然后使用
runit之类的管理程序 - 可以使用
Packer之类的工具来创建AMI,并将其部署到EC2自动伸缩组中 - 可以将服务打包到一个容器中,将其运送到注册表,然后将其部署到
Kubernetes等云原生平台上
Go kit主要与服务中的良好软件工程有关; 它试图与任何类型的平台或基础架构很好地集成。
错误:如何编码错误
服务方法可能会返回错误,两个选项可以在端点中对其进行编码:
- 在响应结构中包含错误字段,然后在其中返回业务域错误
- 在端点错误返回值中返回业务域错误
两种方法都可以起作用。 但是端点直接返回的错误会被检查故障的中间件识别,例如断路器。 服务中的业务域错误不太可能导致断路器在客户端跳闸。 因此,可能应该在响应结构中编码错误。
addsvc包含这两种方法的示例。
服务发现
支持的服务发现系统
Go kit附带对Consul,etcd,ZooKeeper和DNS SRV记录的支持。
是否需要使用sd包
这取决于基础架构。
某些平台(例如Kubernetes)自身负责注册服务实例,并通过平台特定的概念(service)使它们自动可发现。因此,如果在Kubernetes上运行,则可能不需要使用sd软件包。
但是,如果将自己的基础架构或平台与开源组件组合在一起,则服务可能需要在服务注册表中进行注册。或者,如果已达到内部负载均衡器成为瓶颈的规模,则可能需要让服务直接订阅记录系统,并维护自己的连接池(这是客户端服务发现模式)。在这种情况下,sd包将很有用。
可观察性:支持哪些监控系统
Go kit附带了对现代监控系统(如Prometheus和InfluxDB)以及更传统的系统(如statsd,Graphite和expvar)以及托管系统(如通过DogStatsD和Circonus的Datadog)的支持。
强烈推荐使用:Prometheus
日志记录
经验告诉我们,一个好的日志记录程序包应基于最小的接口,并应执行所谓的结构化日志记录。 基于这些不变性,Go kit的套件日志经过多次设计迭代,广泛的基准测试以及大量实际使用而演变成当前状态。
有了明确定义的核心规约,就可以使用熟悉的修饰器模式轻松地解决诸如日志等级、彩色输出和同步之类的辅助问题。 刚开始时可能会感到有些陌生,但是我们认为log包在可用性,可维护性和性能之间取得了理想的平衡。
有关log包演变的更多详细信息,请参阅问题和PR 63、76、131、157和252。
有关日志记录原理的更多信息,请参见 The Hunt for a Logger Interface,Let’s talk about logging和Logging v. instrumentation.
如何聚合日志
收集,运输和聚合日志是平台的责任,而不是单个服务的责任。因此,只需确保将日志写入stdout/stderr,然后让另一个组件来处理其余部分。
Panics
运行时恐慌表示程序员编码错误,并发出错误的程序状态信号。 不应将它们视为错误或ersatz异常。 通常,不应明确地从恐慌中恢复:应该允许它们使程序或处理程序goroutine崩溃,并允许服务将中断的响应返回给调用客户端。 可观察性堆栈应在出现这些问题时发出提醒,然后应尽快修复它们。
话虽如此,如果需要处理异常,最好的策略可能是使用执行恢复的传输层的特定中间件包装具体的传输协议。例如,使用HTTP:
var h http.Handler
h = httptransport.NewServer(...)
h = newRecoveringMiddleware(h, ...)
// use h normally持久性:如何使用数据库和数据存储
访问数据库通常是核心业务逻辑的一部分。因此,包含一个*sql.DB指针在服务的具体实现中。
type MyService struct {
db *sql.DB
value string
logger log.Logger
}
func NewService(db *sql.DB, value string, logger log.Logger) *MyService {
return &MyService{
db: db,
value: value,
logger: logger,
}
}更好的是:考虑定义一个接口来对持久性操作进行建模。 该接口将处理业务域对象,并具有包装数据库句柄的实现。 例如,为用户配置文件考虑一个简单的持久层。
type Store interface {
Insert(Profile) error
Select(id string) (Profile, error)
Delete(id string) error
}
type databaseStore struct{ db *sql.DB }
func (s *databaseStore) Insert(p Profile) error { /* ... */ }
func (s *databaseStore) Select(id string) (Profile, error) { /* ... */ }
func (s *databaseStore) Delete(id string) error { /* ... */ }在这种情况下,在具体的实现中包含一个store,而不是一个*sql.DB。