02 TCP解密
- 0.1. 握手与挥手
- 0.2. 握手时异常处理
- 0.3. TCP 快速建立连接
- 0.4. TCP 重复确认和快速重传
- 0.5. TCP 流量控制
- 0.6. TCP 延迟确认与 Nagle 算法
- 0.7. TCP参数优化
0.1. 握手与挥手
通过实战分析HTTP协议来解密TCP协议。
# terminal-1
tcpdump -i any tcp and host 192.168.3.200 and port 80 -w http.pcap
# terminal-2
curl http://192.168.3.200停止tcpdump的运行,将抓取的数据用wireshark打开。

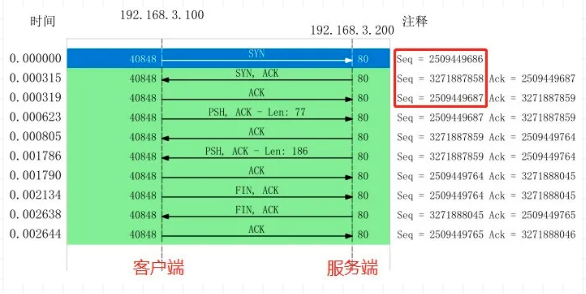
从图中看出数据包分为三个部分:
- 前三个:是TCP建立连接进行的握手
- 中间四个:是HTTP的请求和相应
- 最后三个:是TCP断开连接进行的挥手
使用wireshark的时序图(Statics->Flow Graph->TCP Flows)进一步分析:
理论上的三次握手和四次挥手过程:
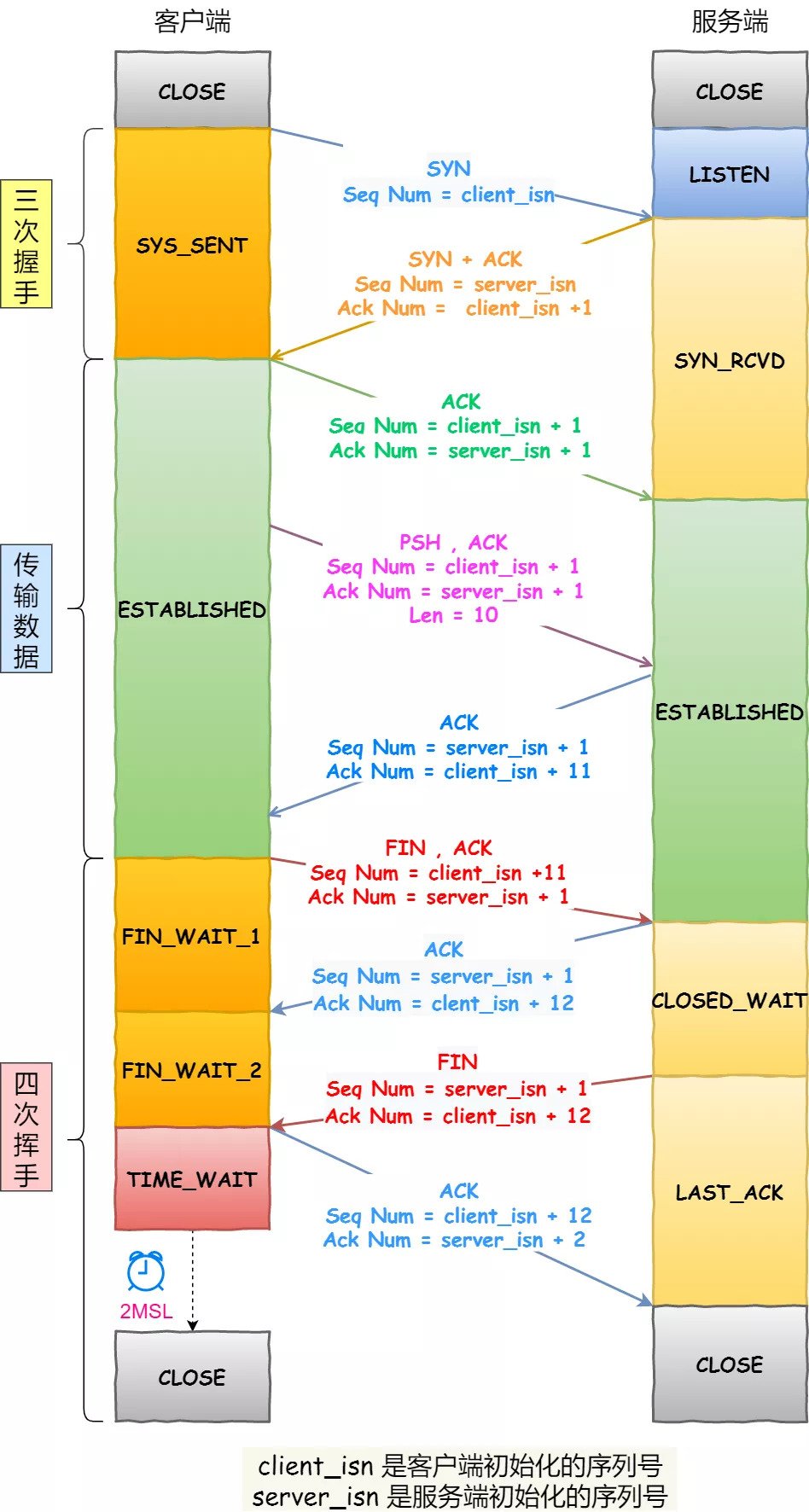
对比发现,理论上挥手是四次,而抓包的数据显示挥手是三次。因为,服务器端收到客户端的 FIN 后,服务器端同时也要关闭连接,这样就可以把 ACK 和 FIN 合并到一起发送,节省了一个包,变成了“三次挥手”。
在通常情况下,服务器端收到客户端的
FIN后,可能还没发送完数据,所以先回复客户端一个ACK包,完成所有数据包的发送后,才会发送FIN包,这就是四次挥手了。
0.2. 握手时异常处理
实验环境:
- Server:192.168.12.36(apache)
- Client:192.168.12.37(curl、telnet、tcpdump)
0.2.1. 第一次握手 SYN 丢包
断开客户端与服务器之间的网线。
curl请求服务器近1分钟后返回connection timed out。

客户端发起了 SYN 包后,一直没有收到服务端的 ACK ,所以一直超时重传了 5 次,并且每次 RTO超时时间是不同的:
- 第一次是在 1 秒超时重传
- 第二次是在 3 秒超时重传
- 第三次是在 7 秒超时重传
- 第四次是在 15 秒超时重传
- 第五次是在 31 秒超时重传
RTO (Retransmission Timeout 超时重传时间)。
每次超时时间 RTO 是指数(翻倍)上涨的,当超过最大重传次数后,客户端不再发送 SYN 包。
在Linux中,第一次握手的 SYN 超时重传次数,是如下内核参数指定的:
sugoi@sugoi:~$ cat /proc/sys/net/ipv4/tcp_syn_retries
5
# 修改这个值会影响重试次数0.2.2. TCP 第二次握手 SYN、ACK 丢包
客户端设置防火墙规则丢弃从服务器响应的数据。
iptables -I INPUT -s 192.168.12.36 -j DROP
curl请求服务器近1分钟后返回connection timed out。

客户端发起
SYN后,由于防火墙屏蔽了服务端的所有数据包,所以curl是无法收到服务端的SYN、ACK包,当发生超时后,就会重传SYN包(就是上一节的情况)服务端收到客户的
SYN包后,就会回SYN、ACK包,但是客户端一直没有回ACK,服务端在超时后,重传了SYN、ACK包,接着一会,客户端超时重传的SYN包又抵达了服务端,服务端收到后,超时定时器就重新计时,然后回了SYN、ACK包,所以相当于服务端的超时定时器只触发了一次又被重置了。最后,客户端
SYN超时重传次数达到了5次(tcp_syn_retries默认值5次),就不再继续发送SYN包了。
所以,当第二次握手的 SYN、ACK 丢包时,客户端会超时重发 SYN 包,服务端也会超时重传 SYN、ACK 包。
在Linux中,第二次握手的 SYN、ACk 超时重传次数,是如下内核参数指定的:
sugoi@sugoi:~$ cat /proc/sys/net/ipv4/tcp_synack_retries
5将客户端的tcp_syn_retries设置为1后重新发生请求,这样可以防止客户端多次重传SYN后重置服务器的超时计数器。
0.2.3. TCP 第三次握手 ACK 丢包
服务器配置防火墙屏蔽客户端TCP报文中标志位是
ACK的包。iptables -I INPUT -s 192.168.12.37 -p tcp --tcp-flag ACK ACK -j DROP
# 服务器无法收到第三次握手的ACK包,一直处于SYN_RECV状态
netstat -tnap | grep 192.168.12.37
tcp 0 0 192.168.12.36:80 192.168.12.37:36008 SYN_RECV -
# 客户端是已完成 TCP 连接建立,处于 ESTABLISHED 状态
netstat -tnap | grep 192.168.12.37
tcp 0 0 192.168.12.337:36008 192.168.12.36:80 ESTAVLISGED 8844/telnet近1分钟后,再次查看发现,服务器上TCP连接消失了,而客户端的TCP连接依然处于ESTABLISHED。
在客户端的telnet中输入内容,一段时间后,telnet断开连接。

- 客户端发送
SYN包给服务端,服务端收到后,回了个SYN、ACK包给客户端,此时服务端的 TCP 连接处于SYN_RECV状态 - 客户端收到服务端的
SYN、ACK包后,给服务端回了个ACK包,此时客户端的 TCP 连接处于ESTABLISHED状态 - 由于服务端配置了防火墙,屏蔽了客户端的
ACK包,所以服务端一直处于SYN_RECV状态 - 服务端超时重传了
SYN、ACK包,重传了5次后停止重传,此时服务端的TCP连接主动中止,原来处于SYN_RECV状态的TCP连接断开,而客户端依然处于ESTABLISHED状态 - 虽然服务端 TCP 断开,但客户端依然处于
ESTABLISHED状态,通过客户端的telnet会话输入了字符 - 服务端已断开连接,客户端发送的数据报文,一直在超时重传(每重传一次,RTO 的值是指数增长),持续一段时间后,客户端的
telnet报错退出,共重传15次
在Linux中,TCP连接建立后,数据包超时重传次数,是如下内核参数指定的:
sugoi@sugoi:~$ cat /proc/sys/net/ipv4/tcp_retries2
150.2.4. TCP 保活机制
如果客户端不发生数据,那么已经建立的TCP连接(即状态为ESTABLISHED)的何时断开?
这就涉及到TCP的保活机制。
保活机制原理:定义一个时间段,在这个时间段内,如果没有任何连接相关的活动,
TCP保活机制开始作用,每隔一个时间间隔,发送一个「探测报文」,该探测报文包含的数据非常少,如果连续几个探测报文都没有得到响应,则认为当前的TCP连接已经死亡,系统内核将错误信息通知给上层应用程序。
在 Linux 内核有对应的参数可以设置保活时间、保活探测次数、保活探测时间间隔,以下都为默认值:
貌似在/etc/sysctl.conf中
net.ipv4.tcp_keepalive_time=7200 # 保活时间7200秒(2小时),两小时内没有任何连接相关活动则启动
net.ipv4.tcp_keepalive_intvl=75 # 保活探测时间间隔75秒
net.ipv4.tcp_keepalive_probes=9 # 保活探测次数9次,无响应则认为对方不可达,从而中断连接在 Linux 系统中,最少需要经过 2 小时 11 分 15 秒才可以发现一个「死亡」连接。
0.3. TCP 快速建立连接
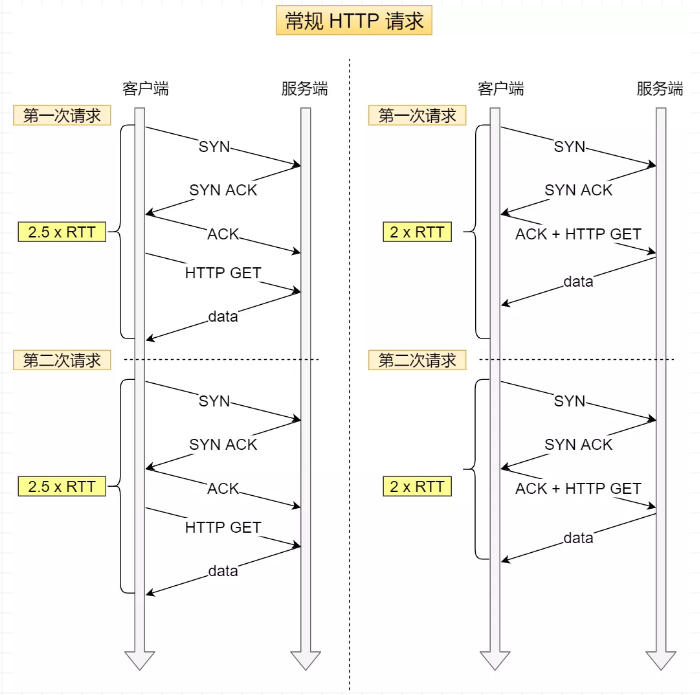
RTT (Round-Trip Time 往返时延),就是数据从网络一端传送到另一端所需的时间,也就是包的往返时间。
客户端在向服务端发起 HTTP GET 请求时,一个完整的交互过程,需要 2.5 个 RTT 时延。第三次握手是可以携带数据的,如果在第三次握手发起 HTTP GET 请求,需要 2 个 RTT 时延。
但是在下一次(在另一个 TCP 连接)发起 HTTP GET 请求时,经历的 RTT 也是一样,如下图:
在 Linux 3.7 内核版本中,提供了 TCP Fast Open 功能,可以减少 TCP 连接建立的时延。
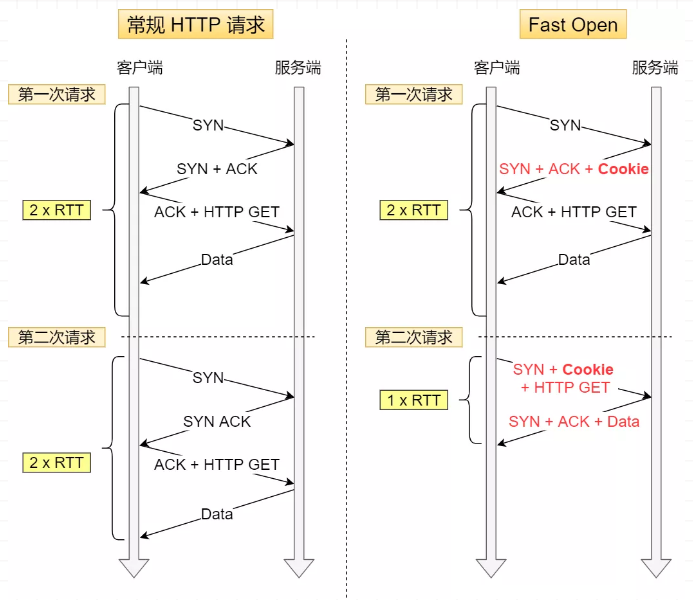
第一次建立连接时,服务端在第二次握手产生一个
Cookie(已加密)并通过SYN、ACK包一起发给客户端,客户端缓存这个Cookie,所以第一次发起HTTPGET请求需要2个RTT时延;再次请求(另一个
TCP连接)时,客户端在SYN包带上Cookie发给服务端,可以跳过三次握手的过程,因为Cookie中维护了一些信息,服务端可以从Cookie获取TCP相关的信息,这时发起的HTTPGET请求就只需要1个RTT时延;
注:客户端在请求并存储了
Fast Open Cookie之后,可以不断重复TCP Fast Open直至服务器认为Cookie无效(通常为过期)。
0.3.1. 开启 Fast Open
可以通过设置 net.ipv4.tcp_fastopn 内核参数,来打开 Fast Open 功能。
net.ipv4.tcp_fastopn 各个值的意义:
- 0 :关闭
- 1 :作为客户端使用 Fast Open 功能
- 2 :作为服务端使用 Fast Open 功能
- 3 :无论作为客户端还是服务器,都可以使用 Fast Open 功能
0.4. TCP 重复确认和快速重传
当接收方收到乱序数据包时,会发送重复的 ACK,以使告知发送方要重发该数据包,当发送方收到 3 个重复 ACK 时,就会触发快速重传,立该重发丢失数据包。
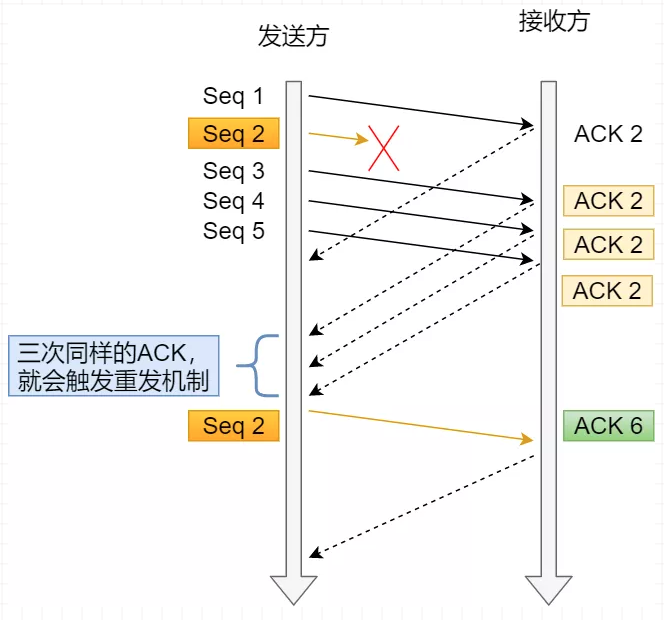
SACK( Selective Acknowledgment 选择性确认),在 TCP 头部「选项」字段里加一个 SACK。Duplicate SACK 又称 D-SACK,其主要使用了 SACK 来告诉「发送方」有哪些数据被重复接收了。
在 TCP 三次握手时协商开启选择性确认 SACK,一旦数据包丢失并收到重复 ACK,在丢失数据包之后成功接收其他数据包,则只需重传丢失的数据包。如果不启用 SACK,就必须重传丢失包之后的每个数据包。
如果要支持 SACK,必须双方都要支持。在 Linux 下,可以通过 net.ipv4.tcp_sack 内核参数打开这个功能(Linux 2.4 后默认打开)。
0.5. TCP 流量控制
TCP 为了防止发送方无脑的发送数据,导致接收方缓冲区被填满,所以有滑动窗口机制,利用接收方的接收窗口来控制发送方要发送的数据量,也就是流量控制。
窗口大小就是指无需等待确认应答,而可以继续发送数据的最大值。
接收窗口是接收方指定的值,存储在 TCP 头部中,它可以告诉发送方自己的 TCP 缓冲区大小,这个缓冲区是给应用程序读取数据的空间:
- 如果应用程序读取了缓冲区的数据,那么缓冲区的就会把被读取的数据移除
- 如果应用程序没有读取数据,则数据会一直滞留在缓冲区
接收窗口的大小,是在 TCP 三次握手中协商好的,后续数据传输时,接收方发送确认应答 ACK 报文时,会携带当前的接收窗口的大小,以此来告知发送方。
如果接收方接收到数据后,应用层能很快的从缓冲区里读取数据,那么窗口大小会一直保持不变,但现实中服务器会出现繁忙的情况,当应用程序读取速度慢,那么缓存空间会慢慢被占满,于是为了保证发送方发送的数据不会超过缓冲区大小,则服务器会调整窗口大小的值,接着通过
ACK报文通知给对方,告知现在的接收窗口大小,从而控制发送方发送的数据大小。
0.5.1. 零窗口通知与窗口探测
- 如果接收方处理数据的速度跟不上接收数据的速度,缓存就会被占满,从而导致接收窗口为 0,当发送方接收到零窗口通知时,就会停止发送数据,这就是窗口关闭。
- 接着,发送方会定时发送窗口大小探测报文(时间逐渐翻倍递增),以便及时知道接收方窗口大小的变化。
发送窗口:决定一口气发多少字节,取值为min(拥塞窗口,接收窗口);
MSS决定这些字节要分多少包才能发完。
0.6. TCP 延迟确认与 Nagle 算法
当 TCP 报文承载的数据非常小(如几个字节),那么整个网络的效率是很低的,因为每个 TCP 报文中都有会 20 个字节的 TCP 头部,和 20 个字节的 IP 头部,而数据只有几个字节,所以在整个报文中有效数据占有的比重就会非常低。
第一种,常见策略来减少小报文的传输,Nagle算法,默认打开,只要以下条件有一个不满足,就囤积数据,等到满足再发生,Nagle 算法一定会有一个小报文,也就是在最开始的时候:
- 没有已发送未确认报文时,立刻发送数据
- 存在未确认报文时,直到「没有已发送未确认报文」或「数据长度达到 MSS 大小」时,再发送数据
没有携带数据的 ACK 的网络效率也是很低的,因为它也有 40 个字节的 IP 头 和 TCP 头,但没有携带数据。
在 Socket 设置 TCP_NODELAY 选项来关闭这个算法(关闭 Nagle 算法没有全局参数,需要根据每个应用自己的特点来关闭,如ssh和telnet这种交互性强的程序需要关闭)。
setsockopt(sock_fd,IPPROTO_TCP,TCP_NODELAY,(char *)&value,sizeof(int));第二种常见策略来解决 ACK 传输效率低问题,就是 TCP 延迟确认:
- 当有响应数据要发送时,
ACK会随着响应数据一起立刻发送给对方 - 当没有响应数据要发送时,
ACK将会延迟一段时间,以等待是否有响应数据可以一起发送 - 如果在延迟等待发送
ACK期间,对方的第二个数据报文又到达了,这时就会立刻发送ACK
在Linux中,TCP延迟确认,是如下内核参数指定的:
sugoi@sugoi:~$ cat /boot/config-5.4.0-33-generic | grep '^CONFIG_HZ='
CONFIG_HZ=250
# define TCP_DELACK_MAX ((unsigned)(HZ/5)) 最大延迟确认时间
# define TCP_DELACK_MAX ((unsigned)(HZ/25)) 最小延迟确认时间
# 上述结果为:50ms和10ms在 Socket 设置 TCP_QUICKACK 选项来关闭TCP延迟确认:
setsockopt(sock_fd,IPPROTO_TCP,TCP_QUICKACK,(char *)&value,sizeof(int));0.6.1. 延迟确认 和 Nagle 算法混合使用
延迟确认 和 Nagle 算法混合使用会产生耗时增长的问题:
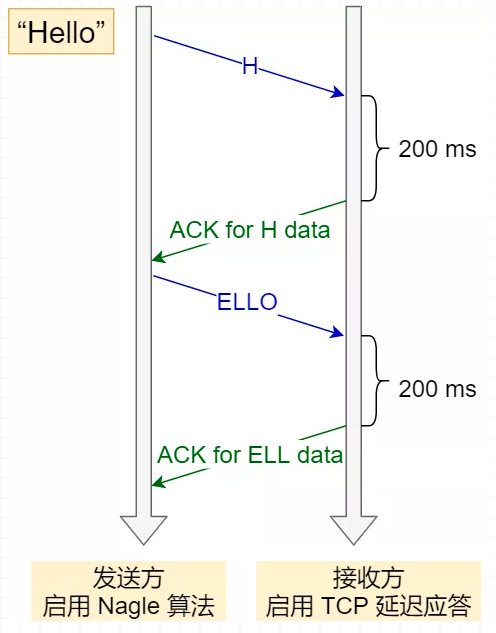
发送方使用了 Nagle 算法,接收方使用了 TCP 延迟确认会发生如下的过程:
- 发送方先发出一个小报文,接收方收到后,由于延迟确认机制,自己又没有要发送的数据,只能干等着发送方的下一个报文到达
- 而发送方由于 Nagle 算法机制,在未收到第一个报文的确认前,是不会发送后续的数据
- 所以接收方只能等待最大时间
200ms 后,才回ACK报文,发送方收到第一个报文的确认报文后,也才可以发送后续的数据
同时使用会造成额外的时延,这就会使得网络"很慢"的感觉,要解决这个问题,只有两个办法:
- 要么发送方关闭 Nagle 算法
- 要么接收方关闭 TCP 延迟确认
0.7. TCP参数优化
Linux系统中,TCP参数都在这里:
sugoi@sugoi:~$ ll /proc/sys/net/ipv4/tcp*
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_abort_on_overflow
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_adv_win_scale
-rw-r--r-- 1 root root 0 6月 17 13:2优化9 /proc/sys/net/ipv4/tcp_allowed_congestion_control
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_app_win
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_corking
-r--r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_available_congestion_control
-r--r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_available_ulp
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_base_mss
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_challenge_ack_limit
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_comp_sack_delay_ns
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_comp_sack_nr
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_congestion_control
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_dsack
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_early_demux
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_early_retrans
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_ecn
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_ecn_fallback
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_fack
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_fastopen
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_fastopen_blackhole_timeout_sec
-rw------- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_fastopen_key
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_fin_timeout
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_frto
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_fwmark_accept
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_invalid_ratelimit
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_keepalive_intvl
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_keepalive_probes
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_keepalive_time
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_l3mdev_accept
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_limit_output_bytes
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_low_latency
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_max_orphans
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_max_reordering
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_max_syn_backlog
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_max_tw_buckets
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_mem
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_min_rtt_wlen
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_min_snd_mss
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_min_tso_segs
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_moderate_rcvbuf
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_mtu_probe_floor
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_mtu_probing
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_no_metrics_save
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_notsent_lowat
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_orphan_retries
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_pacing_ca_ratio
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_pacing_ss_ratio
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_probe_interval
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_probe_threshold
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_recovery
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_reordering
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_retrans_collapse
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_retries1
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_retries2
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_rfc1337
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_rmem
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_rx_skb_cache
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_sack
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_slow_start_after_idle
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_stdurg
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_synack_retries
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_syncookies
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_syn_retries
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_thin_linear_timeouts
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_timestamps
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_tso_win_divisor
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_tw_reuse
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_tx_skb_cache
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_window_scaling
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_wmem
-rw-r--r-- 1 root root 0 6月 17 13:29 /proc/sys/net/ipv4/tcp_workaround_signed_windows0.7.1. 优化策略
0.7.1.1. 提升三次握手性能
- 客户端优化:
echo 5 > /proc/sys/net/ipv4/tcp_syn_retries,调整超时重试次数 - 服务端优化:
echo 1024 > /proc/sys/net/ipv4/tcp_max_syn_backlog && echo 1024 > /proc/sys/net/ipv4/somaxconn,增大半连接队列echo 1 > /proc/sys/net/ipv4/tcp_syncookies,在不使用 SYN 半连接队列的情况下成功建立连接echo 5 > /proc/sys/net/ipv4/tcp_synack_retries,调整超时重试次数echo 1 > /proc/sys/net/ipv4/tcp_abort_on_overflow,调整 accept 队列已满后的策略
- 两者优化:
echo 3 > /proc/sys/net/ipv4/tcp_fastopen,绕过三次握手,实现快速连接
accept 队列的长度取决于 somaxconn 和 backlog 之间的最小值,也就是 min(somaxconn, backlog),其中:
- somaxconn 是 Linux 内核的参数,默认值是 128,可以通过 net.core.somaxconn 来设置其值;
- backlog 是 listen(int sockfd, int backlog) 函数中的 backlog 大小;Tomcat、Nginx、Apache 常见的 Web 服务的 backlog 默认值都是 511。
查看服务端进程 accept 队列的长度:
ss -ltn;Recv-Q:当前 accept 队列的大小,Send-Q:accept 队列最大长度。
syncookies 的工作原理:服务器根据当前状态计算出一个值,放在己方发出的 SYN+ACK 报文中发出,当客户端返回 ACK 报文时,取出该值验证,如果合法,就认为连接建立成功。
syncookies 参数主要有以下三个值:
- 0 值,表示关闭该功能;
- 1 值,表示仅当 SYN 半连接队列放不下时,再启用它;
- 2 值,表示无条件开启功能;
tcp_abort_on_overflow 共有两个值分别是 0 和 1,其分别表示:
- 0 :如果 accept 队列满了,那么 server 扔掉 client 发过来的 ack ;
- 1 :如果 accept 队列满了,server 发送一个 RST 包给 client,表示废掉这个握手过程和这个连接;
把
tcp_abort_on_overflow设置为1,这时如果在客户端异常中可以看到很多connection reset by peer的错误,那么就可以证明是由于服务端TCP全连接队列溢出的问题。通常情况下,应当把tcp_abort_on_overflow设置为0,因为这样更有利于应对突发流量。
0.7.1.2. 提升四次挥手性能
客户端和服务端双方都可以主动断开连接,通常先关闭连接的一方称为主动方,后关闭连接的一方称为被动方。
- 主动方优化:
- RST报文:暴力关闭,不挥手
- FIN报文:挥手
- close:完全断开连接,主动方成为孤儿连接
- shutdown:优雅关闭,控制只关闭一个方向的连接
- SHUT_RD(0):关闭连接的「读」这个方向
- SHUT_WR(1):关闭连接的「写」这个方向
- SHUT_RDWR(2):相当于 SHUT_RD 和 SHUT_WR 操作各一次,关闭套接字的读和写两个方向
echo 5 > /proc/sys/net/ipv4/tcp_orphan_retries,调整FIN报文重传次数(默认为0,特指8次)echo 16384 > /proc/sys/net/ipv4/tcp_max_orphans,调整孤儿连接最大个数echo 60 > /proc/sys/net/ipv4/tcp_fin_timeout,调整孤儿连接 FIN_WAIT2状态,默认60echo 5000 > /proc/sys/net/ipv4/tcp_max_tw_buckets,调整timewait最大个数echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse,打开tcp_tw_reuse功能echo 1 > /proc/sys/net/ipv4/tcp_timestamps,打开时间戳功能,默认为1echo 0 > /proc/sys/net/ipv4/tcp_tw_recycle,关闭 tcp_tw_recycle
- 被动方优化
echo 1 > /proc/sys/net/ipv4/tcp_window_scaling,启用窗口扩大因子功能,默认打开echo "4096 16384 4194304" > /proc/sys/net/ipv4/tcp_wmem,调整TCP发送缓冲区范围echo "4096 87380 6291456" > /proc/sys/net/ipv4/tcp_rmem,调整TCP接收缓冲区范围echo 1 > /proc/sys/net/ipv4/tcp_moderate_rcvbuf,调整TCP接收缓冲区自动调节功能echo "88560 118080 177120" > /proc/sys/net/ipv4/tcp_mem,调整TCP内存范围