06-HTTP未来
HTTP 有两个主要的缺点:安全不足和性能不高。
通过引入 SSL/TLS 在安全上达到了“极致”,但在性能提升方面却是乏善可陈,只优化了握手加密的环节,对于整体的数据传输没有提出更好的改进方案,还只能依赖于“长连接”这种“落后”的技术。
在 HTTPS 逐渐成熟之后,HTTP 就向着性能方面开始“发力”,走出了另一条进化的道路。
- Google 率先发明了 SPDY 协议,并应用于自家的浏览器 Chrome,打响了 HTTP 性能优化的“第一枪”。
- 随后互联网标准化组织 IETF 以 SPDY 为基础,综合其他多方的意见,终于推出了
HTTP/1的继任者HTTP/2,在性能方面有了一个大的飞跃。
0.1. HTTP/2特性
HTTP/2 工作组认为以前的“1.0”“1.1”造成了很多的混乱和误解,让人在实际的使用中难以区分差异,所以就决定 HTTP 协议不再使用小版本号(minor version),只使用大版本号(major version),从今往后 HTTP 协议不会出现
HTTP/2.0、2.1,只会有“HTTP/2”“HTTP/3”,这样就可以明确无误地辨别出协议版本的“跃进程度”,让协议在一段较长的时期内保持稳定,每当发布新版本的 HTTP 协议都会有本质的不同,绝不会有“零敲碎打”的小改良。
0.1.1. 兼容HTTP/1
由于 HTTPS 已经在安全方面做的非常好了,所以 HTTP/2 的唯一目标就是改进性能。但它同时还背负着 HTTP/1 庞大的历史包袱,所以协议的修改必须小心谨慎,兼容性是首要考虑的目标。
HTTP/2 把 HTTP 分解成了“语义”和“语法”两个部分,“语义”层不做改动,与 HTTP/1 完全一致(即 RFC7231)。比如请求方法、URI、状态码、头字段等概念都保留不变,基于 HTTP 的上层应用也不需要做任何修改,可以无缝转换到 HTTP/2。
与 HTTPS 不同,
HTTP/2没有在 URI 里引入新的协议名,仍然用“http”表示明文协议,用“https”表示加密协议。这是一个非常了不起的决定,可以让浏览器或者服务器去自动升级或降级协议,免去了选择的麻烦,让用户在上网的时候都意识不到协议的切换,实现平滑过渡。
在“语义”保持稳定之后,HTTP/2 在“语法”层做了“天翻地覆”的改造,完全变更了 HTTP 报文的传输格式。
0.1.2. 头部压缩
HTTP/1 里可以用头字段“Content-Encoding”指定 Body 的编码方式,比如用 gzip 压缩来节约带宽,但没有针对报文Header的优化手段。
由于报文 Header 一般会携带“User Agent”“Cookie”“Accept”“Server”等许多固定的头字段,多达几百字节甚至上千字节,但 Body 却经常只有几十字节(比如 GET 请求、204/301/304 响应)。
成千上万的请求响应报文里有很多字段值都是重复的,非常浪费,“长尾效应”导致大量带宽消耗在了这些冗余度极高的数据上。
HTTP/2 把“头部压缩”作为性能改进的一个重点,优化的方式是“压缩”。不过 HTTP/2 并没有使用传统的压缩算法,而是开发了专门的“HPACK”算法,在客户端和服务器两端建立“字典”,用索引号表示重复的字符串,还釆用哈夫曼编码来压缩整数和字符串,可以达到 50%~90% 的高压缩率。
HTTP/2的前身SPDY在压缩头部时使用了gzip,但发现会收到CRIME工攻击,所有开发了专用的压缩算法HPACK。
0.1.3. 二进制格式
HTTP/1 里纯文本形式的报文,它的优点是“一目了然”,用最简单的工具就可以开发调试,非常方便。
HTTP/2 在这方面没有“妥协”,不再使用肉眼可见的 ASCII 码,而是向下层的 TCP/IP 协议“靠拢”,全面采用二进制格式。这样虽然对人不友好,但却大大方便了计算机的解析。
原来使用纯文本的时候容易出现多义性,比如大小写、空白字符、回车换行、多字少字等等,程序在处理时必须用复杂的状态机,效率低,还麻烦。
二进制里只有“0”和“1”,可以严格规定字段大小、顺序、标志位等格式,解析起来没有歧义,实现简单,而且体积小、速度快,做到“内部提效”。
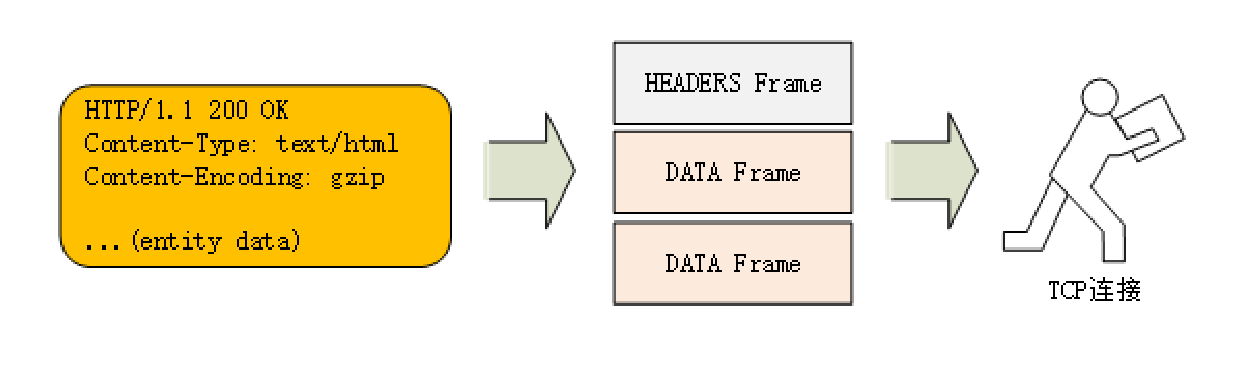
以二进制格式为基础,HTTP/2 把 TCP 协议的部分特性挪到了应用层,把原来的“Header+Body”的消息“打散”为数个小片的二进制“帧”(Frame),用“HEADERS”帧存放头数据、“DATA”帧存放实体数据。
这种做法有点像是“Chunked”分块编码的方式,也是“化整为零”的思路,但 HTTP/2 数据分帧后“Header+Body”的报文结构就完全消失了,协议看到的只是一个个的“碎片”。
0.1.4. 虚拟的“流”
消息的“碎片”到达目的地后应该怎么组装起来呢?
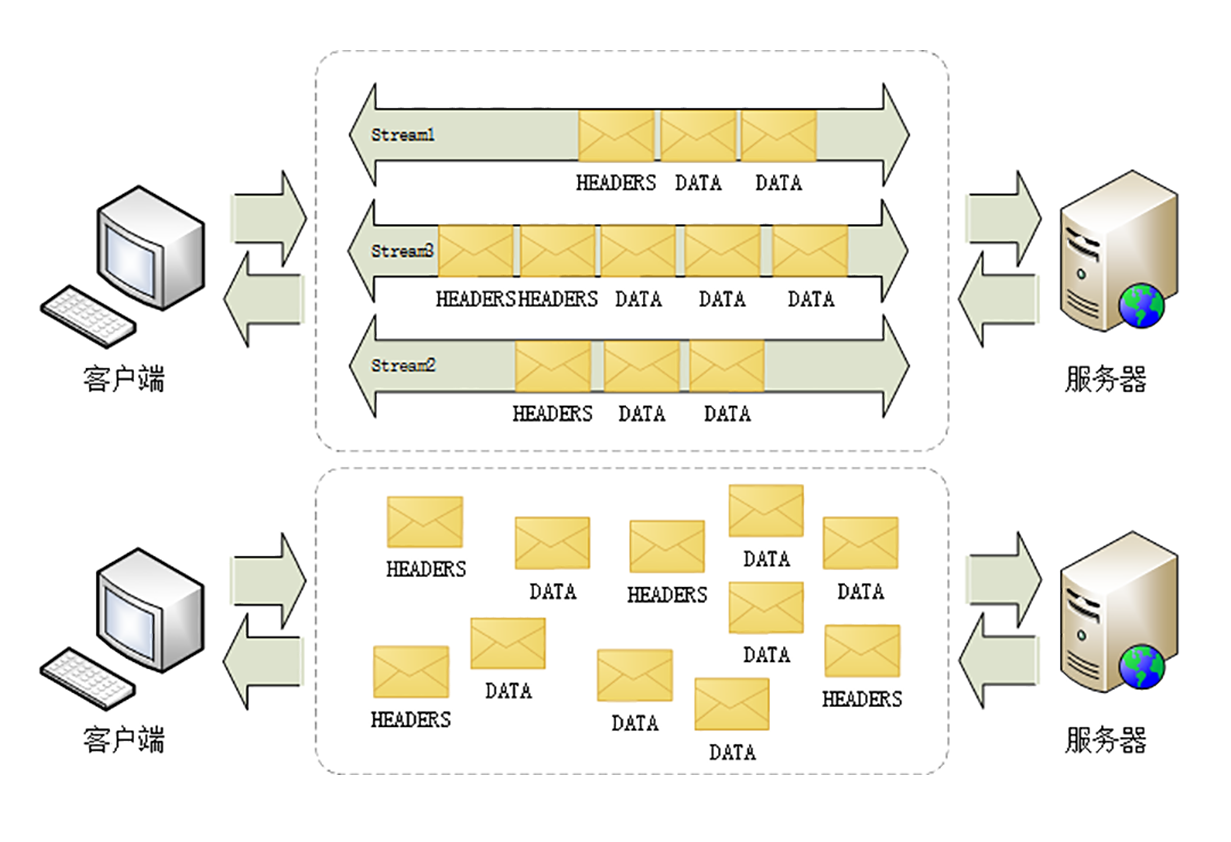
HTTP/2 为此定义了一个“流”(Stream)的概念,它是二进制帧的双向传输序列,同一个消息往返的帧会分配一个唯一的流 ID。想象一个虚拟的“数据流”,在里面流动的是一串有先后顺序的数据帧,这些数据帧按照次序组装起来就是 HTTP/1 里的请求报文和响应报文。
“流”是虚拟的,实际上并不存在,所以 HTTP/2 就可以在一个 TCP 连接上用“流”同时发送多个“碎片化”的消息,这就是“多路复用”( Multiplexing),在多个往返通信都复用一个连接来处理。
在“流”的层面上看,消息是一些有序的“帧”序列,而在“连接”的层面上,消息却是乱序收发的“帧”。多个请求/响应之间没有了顺序关系,不需要排队等待,也就不会再出现“队头阻塞”问题,降低了延迟,大幅度提高了连接的利用率。
为了更好地利用连接,加大吞吐量,HTTP/2 还添加了一些控制帧来管理虚拟的“流”,实现了优先级和流量控制,这些特性也和 TCP 协议非常相似。
HTTP/2 还在一定程度上改变了传统的“请求——应答”工作模式,服务器不再是完全被动地响应请求,也可以新建“流”主动向客户端发送消息。
比如,在浏览器刚请求 HTML 的时候就提前把可能会用到的 JS、CSS 文件发给客户端,减少等待的延迟,这被称为“服务器推送”(Server Push,也叫 Cache Push)。
0.1.5. 强化安全
出于兼容的考虑,HTTP/2 延续了 HTTP/1 的“明文”特点,可以使用明文传输数据,不强制使用加密通信,不过格式还是二进制,只是不需要解密。
由于 HTTPS 已经是大势所趋,而且主流的浏览器 Chrome、Firefox 等都公开宣布只支持加密的 HTTP/2,所以“事实上”的 HTTP/2 是加密的。
互联网上通常所能见到的
HTTP/2都是使用“https”协议名,跑在 TLS 上面。
为了区分“加密”和“明文”这两个不同的版本,HTTP/2 协议定义了两个字符串标识符:
- “h2”表示加密的
HTTP/2, - “h2c”表示明文的
HTTP/2,字母“c”的意思是“clear text”。
在
HTTP/2标准制定的时候(2015 年)已经发现了很多SSL/TLS的弱点,而新的 TLS1.3 还未发布,所以加密版本的HTTP/2在安全方面做了强化,要求下层的通信协议必须是 TLS1.2 以上,还要支持前向安全和 SNI,并且把几百个弱密码套件列入了“黑名单”,比如 DES、RC4、CBC、SHA-1 都不能在HTTP/2里使用,相当于底层用的是“TLS1.25”。
0.1.6. 协议栈
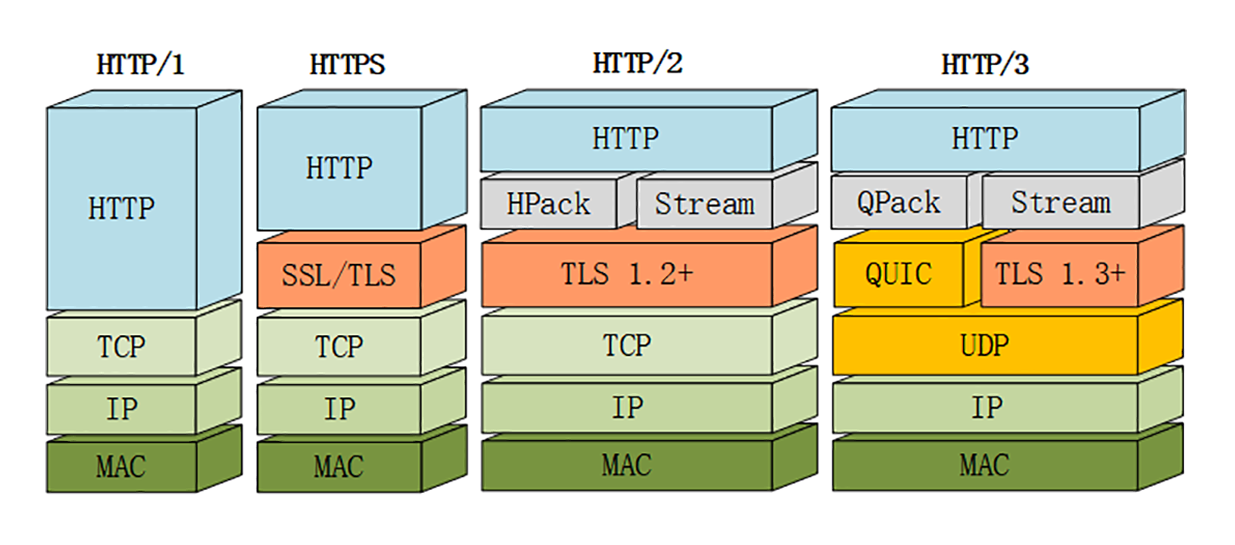
下图对比 HTTP/1、HTTPS 和 HTTP/2 的协议栈,HTTP/2 是建立在“HPack”“Stream”“TLS1.2”基础之上的,比 HTTP/1、HTTPS 复杂。
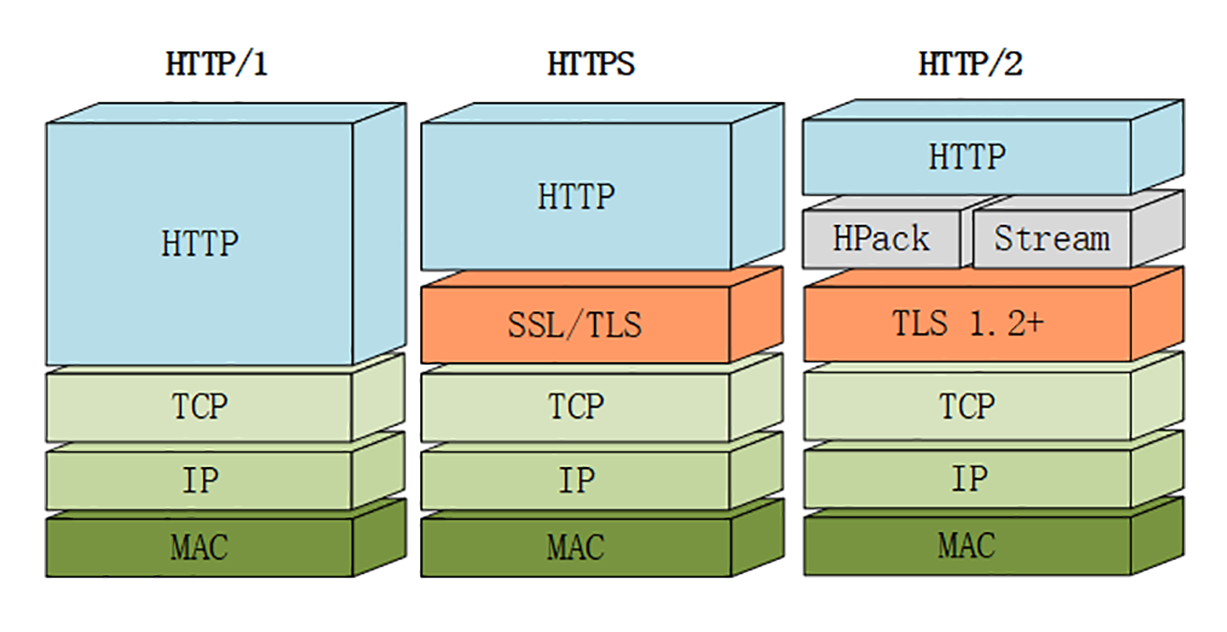
虽然 HTTP/2 的底层实现很复杂,但它的“语义”还是简单的 HTTP/1。
0.2. HTTP/2内核
0.2.1. 连接前言
HTTP/2“事实上”是基于 TLS,所以在正式收发数据之前,会有 TCP 握手和 TLS 握手。
TLS 握手成功之后,客户端必须要发送一个“连接前言”(connection preface),用来确认建立 HTTP/2 连接。
这个“连接前言”是标准的 HTTP/1 请求报文,使用纯文本的 ASCII 码格式,请求方法是特别注册的一个关键字“PRI”,全文只有 24 个字节:
PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n在 Wireshark 里,HTTP/2 的“连接前言”被称为“Magic”。
只要服务器收到这个“Magic”,就知道客户端在 TLS 上想要的是 HTTP/2 协议,而不是其他别的协议,后面就会都使用 HTTP/2 的数据格式。
0.2.2. 头部压缩
确立了连接之后,HTTP/2 就开始准备请求报文。
因为语义上它与 HTTP/1 兼容,所以报文还是由“Header+Body”构成的,但在请求发送前,必须要用“HPACK”算法来压缩头部数据。
“HPACK”算法是专门为压缩 HTTP 头部定制的算法,与 gzip、zlib 等压缩算法不同,它是一个“有状态”的算法,需要客户端和服务器各自维护一份“索引表”,也可以说是“字典”(这有点类似 brotli),压缩和解压缩就是查表和更新表的操作。
为了方便管理和压缩,HTTP/2 废除了原有的起始行概念,把起始行里面的请求方法、URI、状态码等统一转换成了头字段的形式,并且给这些“不是头字段的头字段”起了个特别的名字——“伪头字段”(pseudo-header fields)。而起始行里的版本号和错误原因短语因为没什么大用,顺便也给废除了。
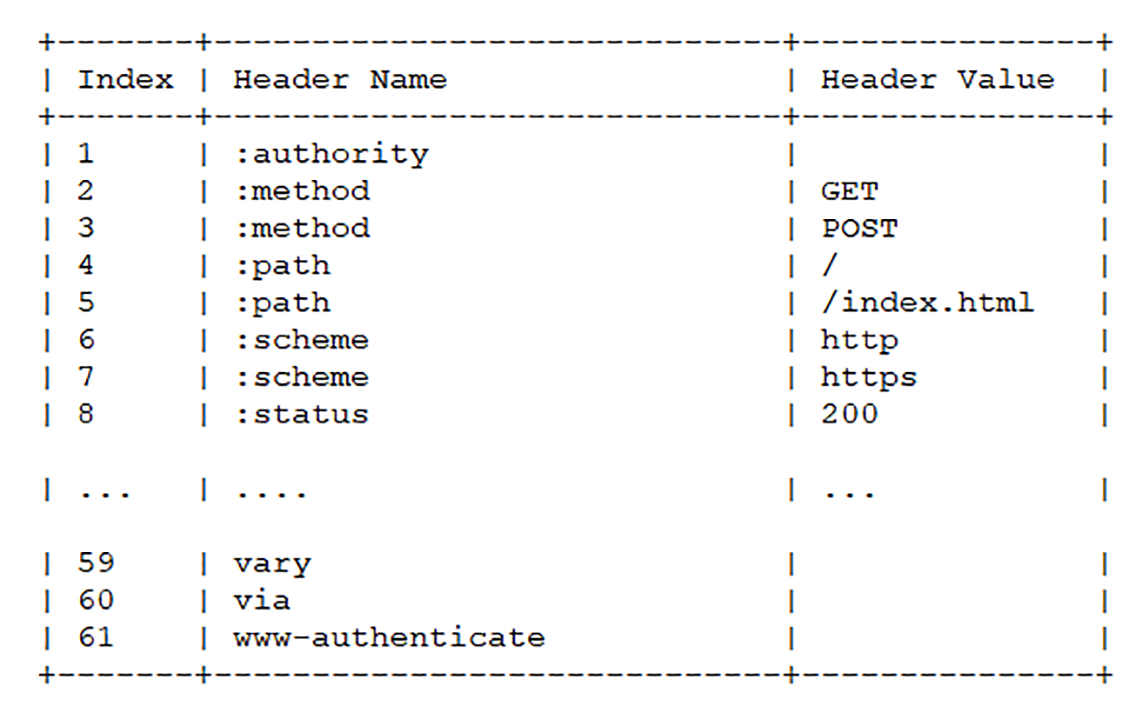
为了与“真头字段”区分开来,这些“伪头字段”会在名字前加一个“:”,比如“:authority” “:method” “:status”,分别表示的是域名、请求方法和状态码。
现在 HTTP 报文头就简单了,全都是“Key-Value”形式的字段,于是 HTTP/2 就为一些最常用的头字段定义了一个只读的“静态表”(Static Table)。
在
HTTP/1里头字段是不分区大写的,这在实践中造成了一些混乱,写法很随意,所有HTTP/2做出了明确的规定,要求所有的头字段必须全部小写,大写会任务是格式错误。
下面的这个表格列出了“静态表”的一部分,这样只要查表就可以知道字段名和对应的值,比如数字“2”代表“GET”,数字“8”代表状态码 200。
如果表里只有 Key 没有 Value,或者是自定义字段根本找不到,这就要用到“动态表”(Dynamic Table),它添加在静态表后面,结构相同,但会在编码解码的时候随时更新。
比如说,第一次发送请求时的“user-agent”字段长是一百多个字节,用哈夫曼压缩编码发送之后,客户端和服务器都更新自己的动态表,添加一个新的索引号“65”。那么下一次发送的时候就不用再重复发那么多字节了,只要用一个字节发送编号就好。
随着在 HTTP/2 连接上发送的报文越来越多,两边的“字典”也会越来越丰富,最终每次的头部字段都会变成一两个字节的代码,原来上千字节的头用几十个字节就可以表示了,压缩效果比 gzip 要好得多。
0.2.3. 二进制帧
头部数据压缩之后,HTTP/2 就要把报文拆成二进制的帧准备发送。HTTP/2 的帧结构有点类似 TCP 的段或者 TLS 里的记录,但报头很小,只有 9 字节,非常地节省( TCP 头最少是 20 个字节)。二进制的格式也保证了不会有歧义,而且使用位运算能够非常简单高效地解析。
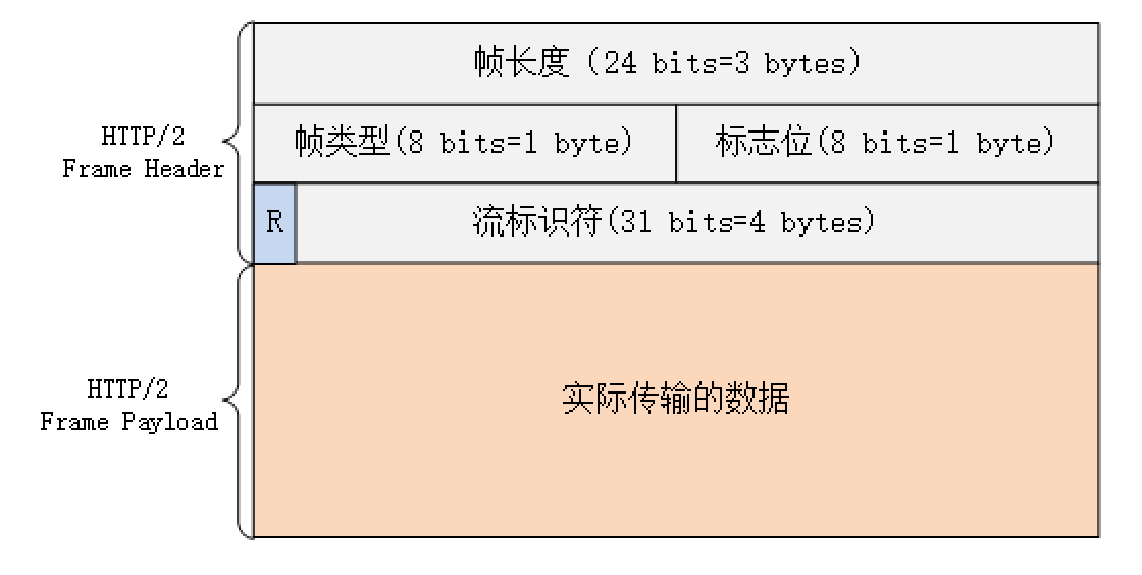
帧开头是 3 个字节的长度(但不包括头的 9 个字节),默认上限是 2^14,最大是 2^24,也就是说 HTTP/2 的帧通常不超过 16K,最大是 16M。
长度后面的 1 个字节是帧类型,大致可以分成数据帧和控制帧两类:
- HEADERS 帧和 DATA 帧属于数据帧,存放的是 HTTP 报文,
- SETTINGS、PING、PRIORITY 等则是用来管理流的控制帧。
HTTP/2 总共定义了 10 种类型的帧,一个字节可以表示最多 256 种,所以也允许在标准之外定义其他类型实现功能扩展。比如 Google 的 gRPC 就利用了这个特点,定义了几种自用的新帧类型。
第 5 个字节是非常重要的帧标志信息,可以保存 8 个标志位,携带简单的控制信息。常用的标志位有 :
END_HEADERS表示头数据结束,相当于HTTP/1里头后的空行(“\r\n”),END_STREAM表示单方向数据发送结束(即 EOS,End of Stream),相当于HTTP/1里 Chunked 分块结束标志(“0\r\n\r\n”)。
报文头里最后 4 个字节是流标识符,也就是帧所属的“流”,接收方使用它就可以从乱序的帧里识别出具有相同流 ID 的帧序列,按顺序组装起来就实现了虚拟的“流”。
流标识符虽然有 4 个字节,但最高位被保留不用,所以只有 31 位可以使用,也就是说,流标识符的上限是 2^31,大约是 21 亿。
Wireshark 抓包的帧实例:
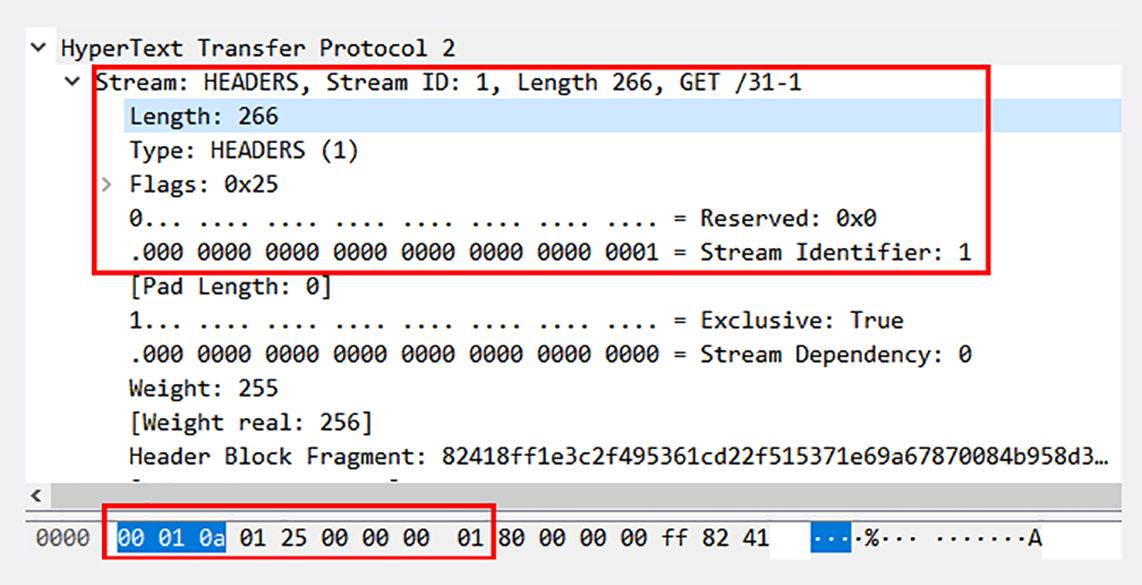
查看最后一行红色方框部分,共9个字节是报文的头。
- 帧长度【前三个字节】:
0x00010a,转换为十进制为266,表示数据长度是 266 字节。 - 帧类型【第四个字节】:
0x01,转换为十进制为1,表示数据帧中的 HEADERS 帧,负载(payload)里面存放的是被 HPACK 算法压缩的头部信息。 - 帧标志信息【第五个字节】:
0x25,转换成二进制为00100101,共有三个标志位为1,含义如下:PRIORITY表示设置了流的优先级,END_HEADERS表示这一个帧就是完整的头数据,END_STREAM表示单方向数据发送结束,后续再不会有数据帧(即请求报文完毕,不会再有 DATA 帧 /Body 数据)。
- 流标识符【最后四个字节】:
0x00000001,表示这是客户端发起的第一个流,后面的响应数据帧也会是这个 ID,也就是说在stream[1]里完成这个请求响应。
0.2.4. 流与多路复用
流与多路复用是 HTTP/2 最核心的部分,流是二进制帧的双向传输序列,理解流的关键是要理解帧头里的流 ID。
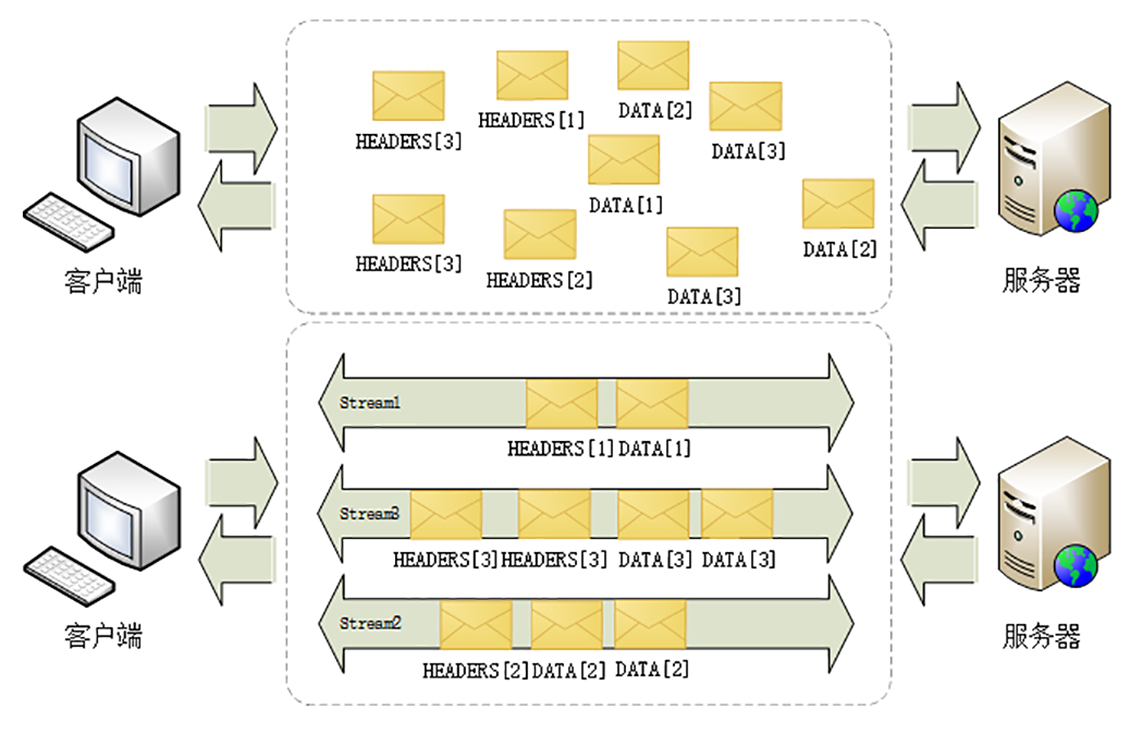
在 HTTP/2 连接上,虽然帧是乱序收发的,但只要它们都拥有相同的流 ID,就都属于一个流,而且在这个流里帧不是无序的,而是有着严格的先后顺序。
在概念上,一个 HTTP/2 的流就等同于一个 HTTP/1 里的“请求——应答”。在 HTTP/1 里一个“请求——响应”报文来回是一次 HTTP 通信,在 HTTP/2 里一个流也承载了相同的功能。
对照 TCP 的概念,TCP 运行在 IP 之上,其实从 MAC 层、IP 层的角度来看,TCP 的“连接”概念也是“虚拟”的。
但从功能上看,无论是 HTTP/2 的流,还是 TCP 的连接,都是实际存在的,所以不必纠结于流的“虚拟”性,把它当做是一个真实存在的实体来理解就好。
HTTP/2 流的特点:
- 流是并发的,一个
HTTP/2连接上可以同时发出多个流传输数据,也就是并发多请求,实现“多路复用”; - 客户端和服务器都可以创建流,双方互不干扰;
- 流是双向的,一个流里面客户端和服务器都可以发送或接收数据帧,也就是一个“请求——应答”来回;
- 流之间没有固定关系,彼此独立,但流内部的帧是有严格顺序的;
- 流可以设置优先级,让服务器优先处理,比如先传
HTML/CSS,后传图片,优化用户体验; - 流 ID 不能重用,只能顺序递增,客户端发起的 ID 是奇数,服务器端发起的 ID 是偶数;
- 在流上发送“
RST_STREAM”帧可以随时终止流,取消接收或发送; - 第 0 号流比较特殊,不能关闭,也不能发送数据帧,只能发送控制帧,用于流量控制。
如下图显示了连接中无序的帧是如何依据流 ID 重组成流的。
从这些特性中,还可以推理出一些深层次的知识点。
比如,HTTP/2 在一个连接上使用多个流收发数据,那么它本身默认是长连接,所以永远不需要“Connection”头字段(keepalive 或 close)。
比如,下载大文件的时候想取消接收,在 HTTP/1 里只能断开 TCP 连接重新“三次握手”,成本很高,而在 HTTP/2 里就可以简单地发送一个“RST_STREAM”中断流,而长连接会继续保持。
比如,客户端和服务器两端都可以创建流,而流 ID 有奇数偶数和上限的区分,所以大多数的流 ID 都会是奇数,而且客户端在一个连接里最多只能发出 2^30,也就是 10 亿个请求。所以 ID 用完了可以再发一个控制帧“GOAWAY”,真正关闭 TCP 连接。
0.2.5. 流状态转换
为了更好地描述运行机制,HTTP/2 借鉴了 TCP,根据帧的标志位实现流状态转换。当然,这些状态也是虚拟的,只是为了辅助理解。
HTTP/2 的流也有一个状态转换图,比 TCP 要简单一点,如下图,对应到一个标准的 HTTP“请求——应答”。
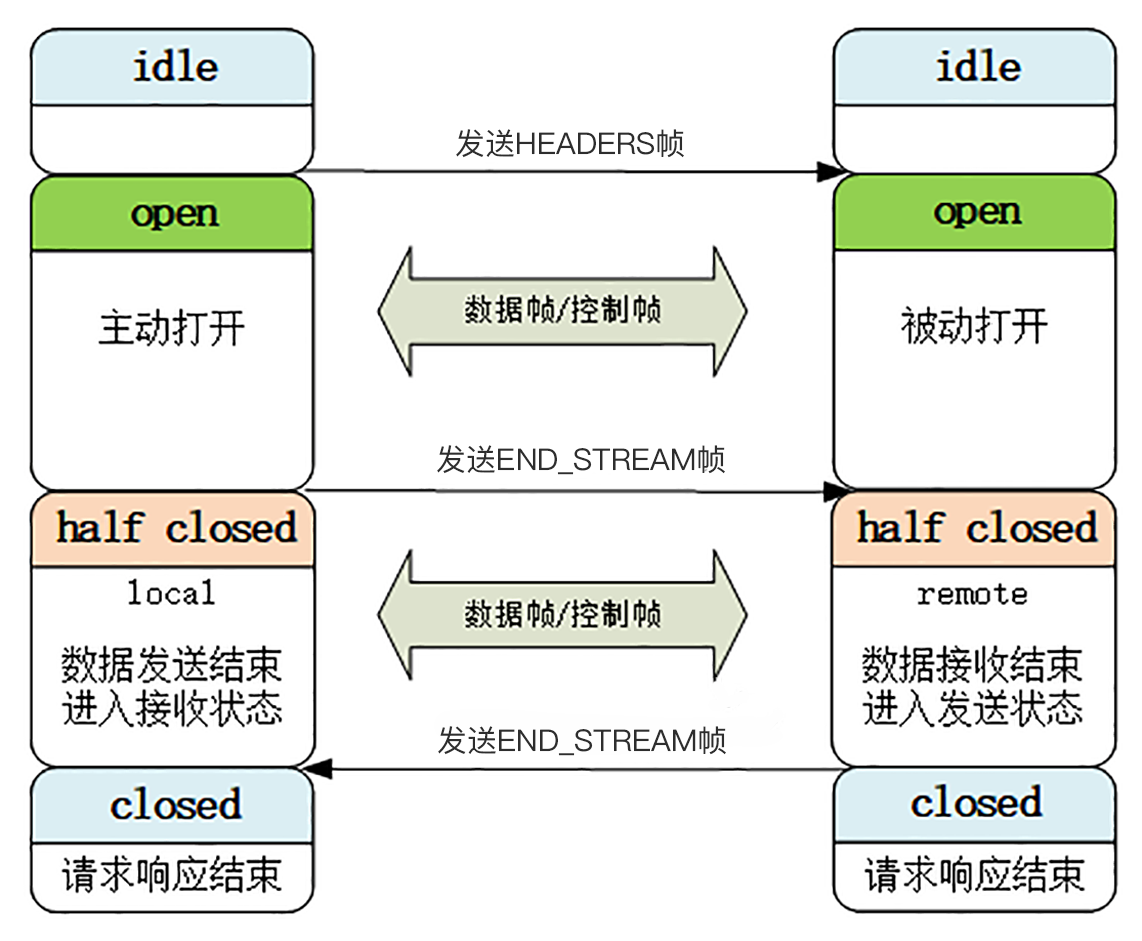
- 最开始流都是“空闲”(idle)状态,也就是“不存在”,可以理解成是待分配的“号段资源”。
- 当客户端发送
HEADERS帧后,有了流 ID,流就进入了“打开”状态,两端都可以收发数据, - 然后客户端发送一个带“
END_STREAM”标志位的帧,流就进入了“半关闭”状态。这个“半关闭”状态很重要,意味着客户端的请求数据已经发送完了,需要接受响应数据,而服务器端也知道请求数据接收完毕,之后就要内部处理,再发送响应数据。 - 响应数据发完了之后,也要带上“
END_STREAM”标志位,表示数据发送完毕,这样流两端就都进入了“关闭”状态,流就结束了。 - 流 ID 不能重用,所以流的生命周期就是
HTTP/1里的一次完整的“请求——应答”,流关闭就是一次通信结束。 - 下一次再发请求就要开一个新流(而不是新连接),流 ID 不断增加,直到到达上限,发送“
GOAWAY”帧开一个新的 TCP 连接,流 ID 就又可以重头计数。
这张图和 HTTP/1 里的标准“请求——应答”过程很像,只不过这是发生在虚拟的“流”上,而不是实际的 TCP 连接,又因为流可以并发,所以 HTTP/2 就可以实现无阻塞的多路复用。
服务器端发起推送流需要使用
PUSH_PROMISE帧,状态转换与客户端基本类似,只是方向不同。
在RST_STREAM和GOAWAY帧里面可以携带32为的错误代码,表示终止流的原因,它是真正的错误,与状态码的含义是不同的。
0.3. HTTP/3
HTTP/2 做出许多努力,比如头部压缩、二进制分帧、虚拟的“流”与多路复用,性能方面比 HTTP/1 有了很大的提升,“基本上”解决了“队头阻塞”这个问题。
0.3.1. HTTP/2的队头阻塞
HTTP/2 虽然使用“帧”“流”“多路复用”,没有了“队头阻塞”,但这些手段都是在应用层里,而在下层,也就是 TCP 协议里,还是会发生“队头阻塞”。
在 HTTP/2 把多个“请求——响应”分解成流,交给 TCP 后,TCP 会再拆成更小的包依次发送(在 TCP 里应该叫 segment,也就是“段”)。
在网络良好的情况下,包可以很快送达目的地。但如果网络质量比较差,像手机上网的时候,就有可能会丢包。而 TCP 为了保证可靠传输,有个特别的“丢包重传”机制,丢失的包必须要等待重新传输确认,其他的包即使已经收到了,也只能放在缓冲区里,上层的应用拿不出来,只能“干着急”。
例如,客户端用 TCP 发送了三个包,但服务器所在的操作系统只收到了后两个包,第一个包丢了。那么内核里的 TCP 协议栈就只能把已经收到的包暂存起来,“停下”等着客户端重传那个丢失的包,这样就又出现了“队头阻塞”。这种“队头阻塞”是 TCP 协议固有的,所以
HTTP/2即使设计出再多的“花样”也无法解决。
Google 在推 SPDY 的时候就已经意识到了这个问题,于是就又发明了一个新的“QUIC”协议,让 HTTP 跑在 QUIC 上而不是 TCP 上。
“HTTP over QUIC”就是 HTTP 协议的下一个大版本,HTTP/3。它在 HTTP/2 的基础上又实现了质的飞跃,真正“完美”地解决了“队头阻塞”问题。
不过 HTTP/3 目前还处于草案阶段,正式发布前可能会有变动,HTTP/3 的协议栈如下图。
0.3.2. QUIC协议
上图中 HTTP/3 有一个关键的改变,把下层的 TCP 换成了 UDP。因为 UDP 是无序的,包之间没有依赖关系,从根本上解决了“队头阻塞”。
UDP 是一个简单、不可靠的传输协议,只是对 IP 协议的一层很薄的包装,和 TCP 相比,它实际应用的较少。
正是因为它简单,不需要建连和断连,通信成本低,也就非常灵活、高效,“可塑性”很强。所以,QUIC 就选定了 UDP,在它之上把 TCP 的那一套连接管理、拥塞窗口、流量控制等“搬”了过来,打造出了一个全新的可靠传输协议,可以认为是“新时代的 TCP”。
- QUIC 最早是由 Google 发明的,被称为 gQUIC,它混合了 UDP、TLS、HTTP,是一个应用层的协议。
- 当前正在由 IETF 标准化的 QUIC 被称为 iQUIC,它对 gQUIC 做了“清理”,把应用部分分离出来,形成了
HTTP/3,原来的 UDP 部分“下放”到了传输层,所以 iQUIC 也叫“QUIC-transport”
两者的差异非常大,甚至比当年的 SPDY 与 HTTP/2 的差异还要大。
0.3.3. QUIC协议特点
下面的 QUIC 都是指 iQUIC,它与早期的 gQUIC 不同,是一个传输层的协议,和 TCP 是平级的。
QUIC虽然是个传输层协议,但它并不由操作系统内核实现,而是运行在用户空间,所以能够不受操作系统的限制,快速迭代演化,有点像Intel的DPDK。
QUIC 基于 UDP,而 UDP 是“无连接”的,根本就不需要“握手”和“挥手”,所以天生就要比 TCP 快。就像 TCP 在 IP 的基础上实现了可靠传输一样,QUIC 也基于 UDP 实现了可靠传输,保证数据一定能够抵达目的地。
它还引入了类似 HTTP/2 的“流”和“多路复用”,单个“流”是有序的,可能会因为丢包而阻塞,但其他“流”不会受到影响。
为了防止网络上的中间设备(Middle Box)识别协议的细节,QUIC 全面采用加密通信,可以很好地抵御窜改和“协议僵化”(ossification)。
因为 TLS1.3 已经在2018正式发布,所以 QUIC 就直接应用了 TLS1.3,顺便也就获得了 0-RTT、1-RTT 连接的好处。但 QUIC 并不是建立在 TLS 之上,而是内部“包含”了 TLS。它使用自己的帧“接管”了 TLS 里的“记录”,握手消息、警报消息都不使用 TLS 记录,直接封装成 QUIC 的帧发送,省掉了一次开销。
0.3.4. QUIC内部细节
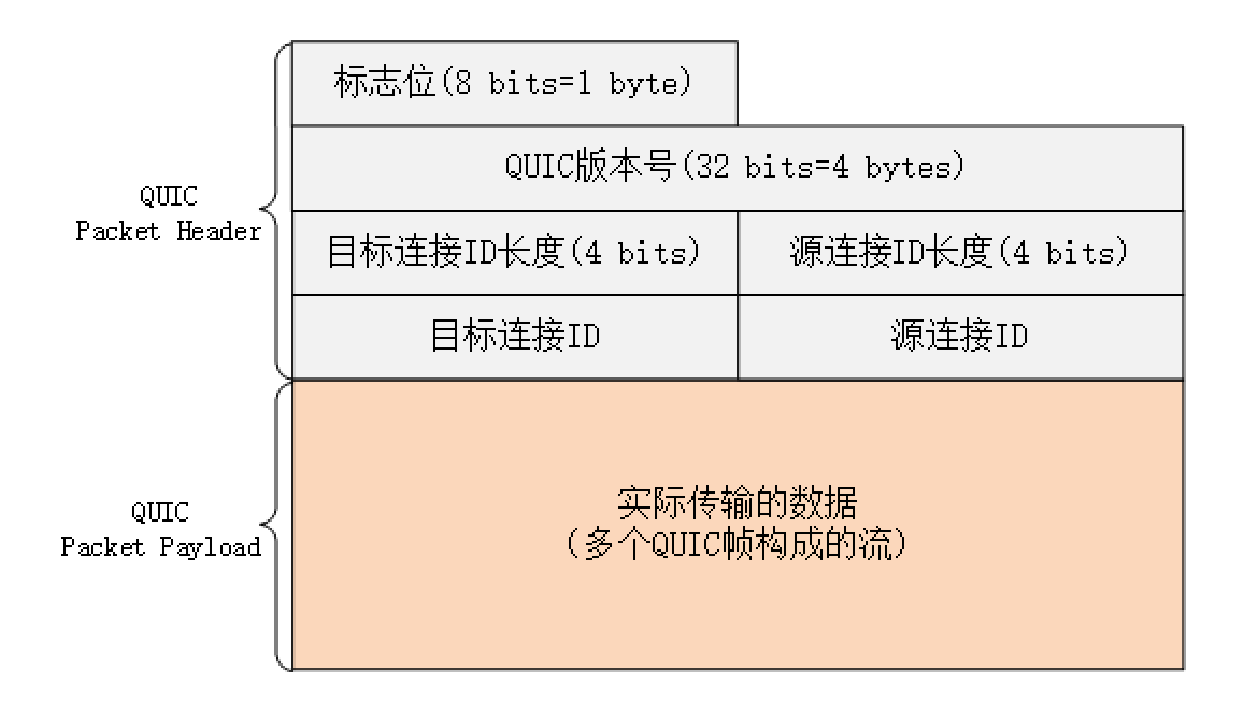
由于 QUIC 在协议栈里比较偏底层,QUIC 的基本数据传输单位是包(packet)和帧(frame),一个包由多个帧组成,包面向的是“连接”,帧面向的是“流”。
QUIC 使用不透明的“连接 ID”来标记通信的两个端点,客户端和服务器可以自行选择一组 ID 来标记自己,这样就解除了 TCP 里连接对“IP 地址 + 端口”(即常说的四元组)的强绑定,支持“连接迁移”(Connection Migration)。
比如,你下班回家,手机会自动由 4G 切换到 WiFi。这时 IP 地址会发生变化,TCP 就必须重新建立连接。而 QUIC 连接里的两端连接 ID 不会变,所以连接在“逻辑上”没有中断,它就可以在新的 IP 地址上继续使用之前的连接,消除重连的成本,实现连接的无缝迁移。
QUIC 的帧里有多种类型,PING、ACK 等帧用于管理连接,而 STREAM 帧专门用来实现流。QUIC 里的流与 HTTP/2 的流非常相似,也是帧的序列。但 HTTP/2 里的流都是双向的,而 QUIC 则分为双向流和单向流。
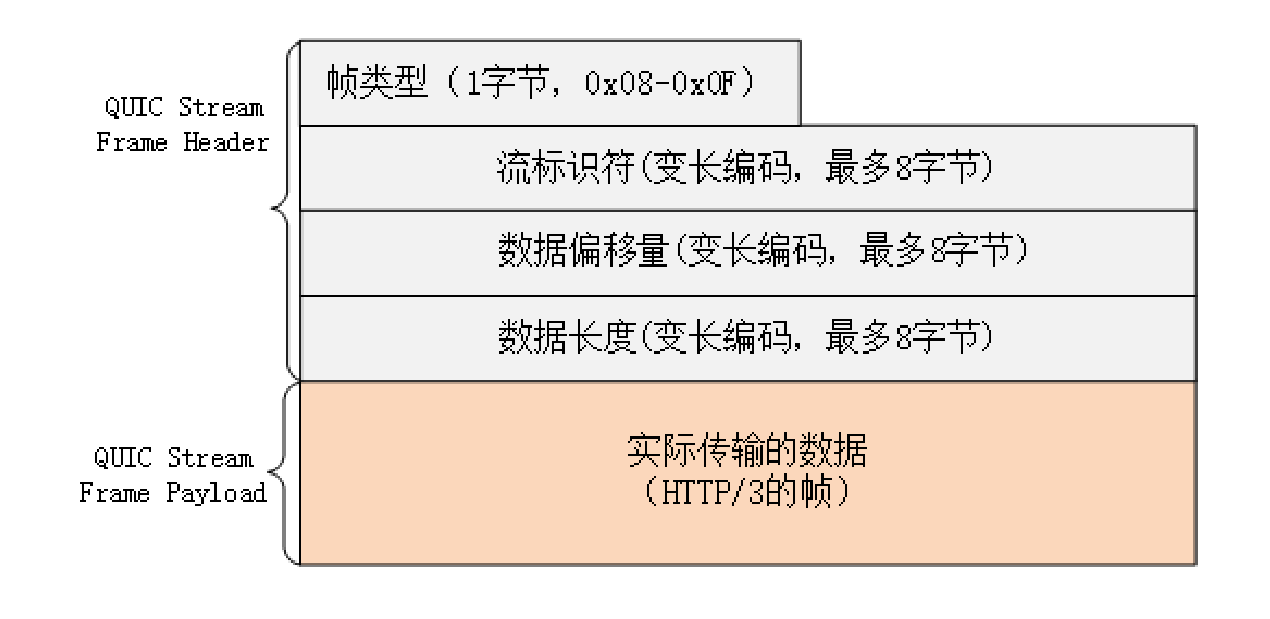
QUIC 帧普遍采用变长编码,最少只要 1 个字节,最多有 8 个字节。
流 ID 的最大可用位数是 62,数量上比 HTTP/2 的 2^31 大大增加。
流 ID 还保留了最低两位用作标志,第 1 位标记流的发起者,0 表示客户端,1 表示服务器;第 2 位标记流的方向,0 表示双向流,1 表示单向流。
所以 QUIC 流 ID 的奇偶性质和 HTTP/2 刚好相反,客户端的 ID 是偶数,从 0 开始计数。
0.3.5. HTTP/3协议
QUIC 本身就已经支持了加密、流和多路复用,所以 HTTP/3 的工作减轻了很多,把流控制都交给 QUIC 去做。调用的不再是 TLS 的安全接口,也不是 Socket API,而是专门的 QUIC 函数。这个“QUIC 函数”还没有形成标准,必须要绑定到某一个具体的实现库。
HTTP/3 里仍然使用流来发送“请求——响应”,但它自身不需要像 HTTP/2 那样再去定义流,而是直接使用 QUIC 的流,相当于做了一个“概念映射”。
HTTP/3 里的“双向流”可以完全对应到 HTTP/2 的流,而“单向流”在 HTTP/3 里用来实现控制和推送,近似地对应 HTTP/2 的 0 号流。
由于流管理被“下放”到了 QUIC,所以 HTTP/3 里帧的结构也变简单了。帧头只有两个字段:类型和长度,而且同样都采用变长编码,最小只需要两个字节。
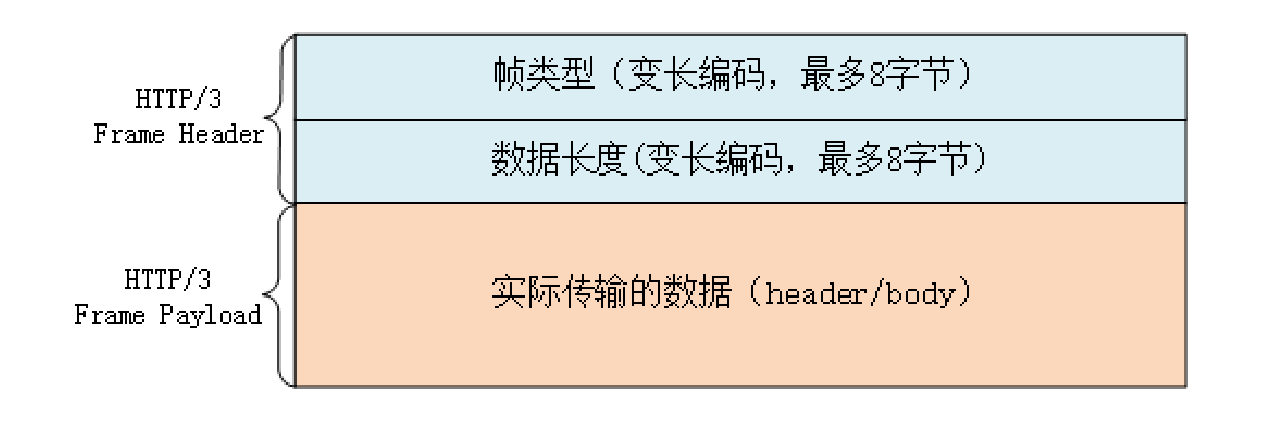
HTTP/3 里的帧仍然分成数据帧和控制帧两类,HEADERS 帧和 DATA 帧传输数据,但其他一些帧因为在下层的 QUIC 里有了替代,所以在 HTTP/3 里就都消失了,比如 RST_STREAM、WINDOW_UPDATE、PING 等。
头部压缩算法在 HTTP/3 里升级成了“QPACK”,使用方式上也做了改变。虽然也分成静态表和动态表,但在流上发送 HEADERS 帧时不能更新字段,只能引用,索引表的更新需要在专门的单向流上发送指令来管理,解决了 HPACK 的“队头阻塞”问题。
另外,QPACK 的字典也做了优化,静态表由之前的 61 个增加到了 98 个,而且序号从 0 开始,也就是说“:authority”的编号是 0。
0.3.6. HTTP/3 服务发现
HTTP/3 没有指定默认的端口号,也就是说不一定非要在 UDP 的 80 或者 443 上提供 HTTP/3 服务。
HTTP/3 用 HTTP/2 里的“扩展帧”进服务发现。
- 浏览器需要先用
HTTP/2协议连接服务器, - 然后服务器可以在启动
HTTP/2连接后发送一个“Alt-Svc”帧,包含一个“h3=host:port”的字符串,告诉浏览器在另一个端点上提供等价的HTTP/3服务。 - 浏览器收到“Alt-Svc”帧,会使用 QUIC 异步连接指定的端口,如果连接成功,就会断开
HTTP/2连接,改用新的HTTP/3收发数据。