01 CPU
Medium 英文原文。
曾三次获得 F1 世界冠军的杰基 • 斯图尔特 (Jackie Stewart) 表示,了解汽车的工作原理让他成为了一名更好的驾驶员。你并不需要先成为一个工程师才能去做一个赛车手,但是你得有一种机械同感 (Mechanical Sympathy)。
Martin Thompson (高性能消息库 LMAX Disruptor 的设计者) 就一直都把机械同感的理念应用到编程中。简而言之,了解计算机底层硬件能让我们作为一个更优秀的开发者去设计算法、数据结构等等。
基本原理
现代计算机处理器是基于一种叫对称多处理 (symmetric multiprocessing, SMP) 的概念。在一个 SMP 系统里,处理器的设计使两个或多个核心连接到一片共享内存 (也叫做主存,RAM)。另外,为了加速内存访问,处理器有着不同级别的缓存,分别是 L1、L2 和 L3。确切的体系结构可能因供应商、处理器模型等等而异。然而,目前最流行的模型是把 L1 和 L2 缓存内嵌在 CPU 核心本地,而把 L3 缓存设计成跨核心共享:
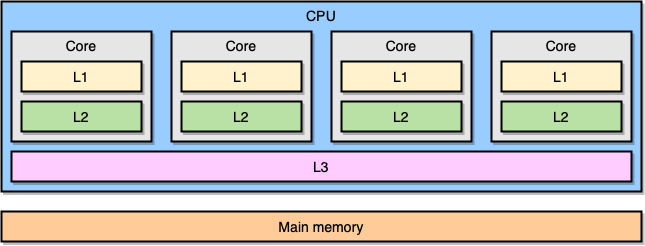
越靠近 CPU 核心的缓存,容量就越小,同时访问延迟就越低 (越快):
Cache | Latency | CPU cycles | Size ---------|----------|--------- L1 access|~1.2 ns|~4|Between 32 KB and 512 KB L2 access|~3 ns|~10|Between 128 KB and 24 MB L3 access|~12 ns|~40|Between 2 MB and 32 MB
同样的,这些具体的数字因不同的处理器模型而异。不过,我们可以做一个粗略的估算:假设 CPU 访问主存需要耗费 60 ns,那么访问 L1 缓存会快上 50 倍。
在处理器的世界里,有一个很重要的概念叫访问局部性 (locality of reference),当处理器访问某个特定的内存地址时,有很大的概率会发生下面的情况:
- CPU 在不久的将来会去访问相同的地址:这叫 时间局部性 (temporal locality) 原则。
- CPU 会访问特定地址附近的内存地址:这叫 空间局部性 (spatial locality) 原则。
之所以会有 CPU 缓存,时间局部性是其中一个重要的原因。不过,我们到底应该怎么利用处理器的空间局部性呢?比起拷贝一个单独的内存地址到 CPU 缓存里,拷贝一个缓存行 (Cache Line) 是更好的实现。一个缓存行是一个连续的内存段。
缓存行的大小取决于缓存的级别 (同样的,具体还是取决于处理器模型)。举个例子,这是我的电脑的 L1 缓存行的大小:
$ sysctl -a | grep cacheline
hw.cachelinesize: 64处理器会拷贝一段连续的 64 字节的内存段到 L1 缓存里,而不是仅仅拷贝一个单独的变量。举个例子,当处理器要拷贝一个由 int64 类型组成 Go 的切片到 CPU 缓存里的时候,它会一起拷贝 8 个元素,而不是单单拷贝 1 个。