Install-Manual
- 0.1. google镜像下载地址
- 0.2. 安装前检查
- 0.3. 安装运行时环境
- 0.4. Docker
- 0.5. Kubeadm、Kubelet、kubectl
- 0.6. 部署高可用集群
- 0.7. 部署堆叠集群
0.1. google镜像下载地址
0.2. 安装前检查
- Linux操作系统:Centos 7
- 2GB以上内存、2核以上CPU
- 集群之间网络互通
- 每个节点需要有唯一的hostname、MAC地址和produc_uuid
- 打开特定的端口
- 禁用swap(必须禁用swap才能使kubelet正常工作)
# 获取网络接口的MAC地址
ip link
ifconfig -a
# 查看product_uuid
sudo cat /sys/class/dmi/id/product_uuid某些虚拟机可能有相同的值,但是硬件设备具有唯一的值,Kubernetes使用这些值来唯一标识集群中的节点,如果这些值对于每个节点都不是唯一的,会导致安装失败。
如果有多个网络适配器,并且在默认路由上无法访问的Kubernetes组件,建议添加IP路由,以便通过适当的适配器访问Kubernetes群集。
0.2.1. Master
| 协议 | 方向 | 端口范围 | 目的 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 6443* | Kubernetes API server | All |
| TCP | 入站 | 2379-2380 | etcd server client API | kube-apiserver, etcd |
| TCP | 入站 | 10250 | Kubelet API | Self, Control plane |
| TCP | 入站 | 10251 | kube-scheduler | Self |
| TCP | 入站 | 10252 | kube-controller-manager | Self |
*标记的端口可以自定义为其他端口。etcd也可以使用集群外的集群或自定义的其他端口。
0.2.2. Worker
| 协议 | 方向 | 端口范围 | 目的 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 10250 | Kubelet API | Self, Control plane |
| TCP | 入站 | 30000-32767 | NodePort Services** | All |
**标记的端口是对外提供服务是的Service的默认端口范围。Pod的网络插件也需要使用特定的端口。
0.3. 安装运行时环境
kubeadm将尝试通过扫描已知的域套接字列表来自动检测Linux节点上的容器运行时,可以在下表中找到所使用的可检测运行时和套接字路径。
| Runtime | Domain Socket |
|---|---|
| Docker | /var/run/docker.sock |
| containerd | /run/containerd/containerd.sock |
| CRI-O | /var/run/crio/crio.sock |
如果同时检测到
Docker和containerd,则Docker优先。这是必需的,因为Docker 18.09附带了containerd,两者都是可检测的,如果检测到任何其他两个或更多运行时,kubeadm将退出并显示相应的错误消息。
如果选择的容器运行时是Docker,则通过kubelet内置的dockershim CRI实现使用它。
以root用户或者在增加命令前缀sudo。
0.4. Docker
# Install Docker CE
## Set up the repository
### Install required packages.
yum install yum-utils device-mapper-persistent-data lvm2
### Add Docker repository.
yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
## Install Docker CE.
yum update && yum install docker-ce-18.06.2.ce
## Create /etc/docker directory.
mkdir /etc/docker
# Setup daemon.
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"], #这个参数修改默认的Cgroups管理器
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
EOF
mkdir -p /etc/systemd/system/docker.service.d
# Restart Docker
systemctl daemon-reload
systemctl restart docker更多安装细节参考
0.5. Kubeadm、Kubelet、kubectl
每个节点都需要安装:
- kubeadm:用于安装集群
- kubelet:在群集中的所有计算机上运行的组件,并执行诸如启动pod和容器之类的操作
- kubectl:与集群通信的命令行工具
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
exclude=kube*
EOF
# Set SELinux in permissive mode (effectively disabling it)
# 关闭 SeLinux 使得容器能够访问宿主机文件系统(例如容器网络)
setenforce 0
sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
systemctl enable --now kubelet
# 由于iptables被绕过而导致流量路由不正确的问题
# 确保在`sysctl`中将`net.bridge.bridge-nf-call-iptables`设置为1
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
# 确保`br_netfilter`模块已经加载
lsmod | grep br_netfilter # 查看模块是否加载
modprobe br_netfilter # 加载模块完成以上设置后,kubelet进入一个crashloop中(每隔几秒重新启动一次)等待kubeadm告诉它该怎么做。
0.5.1. 配置主节点的kubelet的Cgroup驱动
当使用Docker作为容器运行时,kubeadm会自动检测cgroup驱动,并且在运行时期间将其设置在/var/lib/kubelet/kubeadm-flags.env文件中。
如果使用其他CRI,需要修改/etc/default/kubelet文件中cgroup-driver的值,例如:KUBELET_EXTRA_ARGS=--cgroup-driver=<value>
kubeadm init和kubeadm join将使用此文件为kubelet提供额外的用户定义参数。
请注意,如果CRI的cgroup驱动程序不是cgroupfs,才需要进行修改,因为这已经是kubelet中的默认值。
修改完成之后,需要重启kubelet:
systemctl daemon-reload
systemctl restart kubelet0.6. 部署高可用集群
0.6.1. 为kube-apiserver部署负载均衡器
创建一个名称可解析为DNS的kube-apiserver负载均衡器
- 负载平衡器必须能够通过apiserver端口与所有控制平面节点通信,还必须允许其监听端口上的传入流量
- HAProxy可以作为一个负载均衡器
- 确保负载均衡器的地址始终与kubeadm的
Control Plane Endpoint的地址匹配
添加第一个控制平面节点到负载均衡器中,并测试通信
nc -v LOAD_BALANCER_IP PORT由于apiserver尚未运行,因此预计会出现连接拒绝错误。但是,超时意味着负载均衡器无法与控制平面节点通信。如果发生超时,请重新配置负载平衡器以与控制平面节点通信。
将剩余的控制平面节点添加到负载平衡器目标组
0.6.2. 安装keepalived & HAProxy
通过keepalived + haproxy实现的,其中:
- keepalived是提供一个VIP,通过VIP关联所有的Master节点
- 然后haproxy提供端口转发功能
由于VIP在Master的机器上,默认配置API Server的端口是
6443,所以需要将另外一个端口关联到这个VIP上,一般用8443。如下图所示:
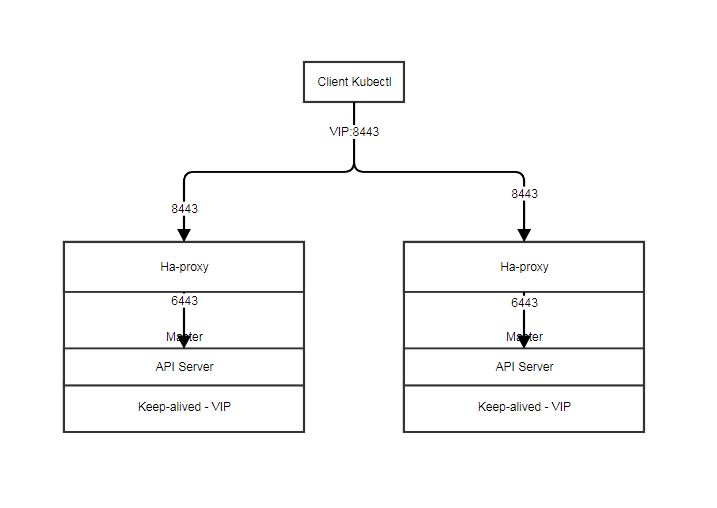
在Master手工安装keepalived, haproxy
yum install keepalived yum install haproxy修改HAProxy的配置文件
配置文件是:
haproxy.cfg,默认路径是/etc/haproxy/haproxy.cfg,同时需要手动创建/run/haproxy目录,否则haproxy会启动失败。注意:
- bind绑定的就是VIP对外的端口号,这里是8443
- balance指定的负载均衡方式是roundrobin方式
- server指定的就是实际的Master节点地址以及真正工作的端口号,这里是6443,有多少台Master就写多少条记录
# haproxy.cfg sample global log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy stats socket /var/run/haproxy-admin.sock mode 660 level admin stats timeout 30s user haproxy group haproxy daemon nbproc 1 defaults log global timeout connect 5000 timeout client 50000 timeout server 50000 listen admin_stats bind 0.0.0.0:10080 mode http log 127.0.0.1 local0 err stats refresh 30s stats uri /status stats realm welcome login\ Haproxy stats auth admin:123456 stats hide-version stats admin if TRUE listen kube-master bind 0.0.0.0:8443 mode tcp option tcplog balance roundrobin server tuo-1 172.18.52.34:6443 check inter 10000 fall 2 rise 2 weight 1 server tuo-2 172.18.52.33:6443 check inter 10000 fall 2 rise 2 weight 1 server tuo-3 172.18.52.32:6443 check inter 10000 fall 2 rise 2 weight 1修改keepalived的配置文件
修改keepalived的配置文件,配置正确的VIP,keepalived的配置文件
keepalived.conf的默认路径是/etc/keepalived/keepalived.conf注意:
- priority决定Master的主次,数字越小优先级越高
- virtual_router_id决定当前VIP的路由号,实际上VIP提供了一个虚拟的路由功能,该VIP在同一个子网内必须是唯一
- virtual_ipaddress提供的就是VIP的地址,该地址在子网内必须是空闲未必分配的
# keepalived.cfg sample(Master) global_defs { router_id K8s_Master } vrrp_script check_haproxy { script "killall -0 haproxy" interval 3 weight -2 fall 10 rise 2 } vrrp_instance VI-kube-master { state MASTER interface eno16777728 priority 150 virtual_router_id 51 advert_int 3 authentication { auth_type PASS auth_pass transwarp } virtual_ipaddress { 172.18.52.33 } track_script { check_haproxy } } # keepalived.cfg sample(Backup) global_defs { router_id K8s_Backup_1 } vrrp_script check_haproxy { script "killall -0 haproxy" interval 3 weight -2 fall 10 rise 2 } vrrp_instance VI-kube-master { state BACKUP interface eno16777728 priority 140 virtual_router_id 51 advert_int 3 authentication { auth_type PASS auth_pass transwarp } virtual_ipaddress { 172.18.52.33 } track_script { check_haproxy } }优先启动主Master的keepalived和haproxy
systemctl enable keepalived systemctl start keepalived systemctl enable haproxy systemctl start haproxy检查keepalived是否启动成功
ip a s
# 查看是否有VIP地址分配
# 如果看到VIP地址已经成功分配在eth0网卡上,说明keepalived启动成功
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:50:56:a9:d5:be brd ff:ff:ff:ff:ff:ff
inet 10.86.13.32/23 brd 10.86.13.255 scope global eth0
valid_lft forever preferred_lft forever
**inet 10.86.13.36/32 scope global eth0**
valid_lft forever preferred_lft forever
inet6 fe80::250:56ff:fea9:d5be/64 scope link
valid_lft forever preferred_lft forever
# 更保险的方法是查看keepalived的状态和HAProxy的状态
systemctl status keepalived -l
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2018-02-01 10:24:51 CST; 1 months 16 days ago
Main PID: 13448 (keepalived)
Memory: 6.0M
CGroup: /system.slice/keepalived.service
├─13448 /usr/sbin/keepalived -D
├─13449 /usr/sbin/keepalived -D
└─13450 /usr/sbin/keepalived -D
Mar 20 04:51:15 kube32 Keepalived_vrrp[13450]: VRRP_Instance(VI-kube-master) Dropping received VRRP packet...
**Mar 20 04:51:18 kube32 Keepalived_vrrp[13450]: (VI-kube-master): ip address associated with VRID 51 not present in MASTER advert : 10.86.13.36
Mar 20 04:51:18 kube32 Keepalived_vrrp[13450]: bogus VRRP packet received on eth0 !!!**
systemctl status haproxy -l
● haproxy.service - HAProxy Load Balancer
Loaded: loaded (/usr/lib/systemd/system/haproxy.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2018-02-01 10:33:22 CST; 1 months 16 days ago
Main PID: 15116 (haproxy-systemd)
Memory: 3.2M
CGroup: /system.slice/haproxy.service
├─15116 /usr/sbin/haproxy-systemd-wrapper -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid
├─15117 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds
└─15118 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds
# 查看kubernetes集群信息
kubectl version
**Client Version: version.Info{Major:"1", Minor:"9", GitVersion:"v1.9.1", \
GitCommit:"3a1c9449a956b6026f075fa3134ff92f7d55f812", GitTreeState:"clean", \
BuildDate:"2018-01-03T22:31:01Z", GoVersion:"go1.9.2", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"9", GitVersion:"v1.9.1", \
GitCommit:"3a1c9449a956b6026f075fa3134ff92f7d55f812", GitTreeState:"clean", \
BuildDate:"2018-01-03T22:18:41Z", GoVersion:"go1.9.2", Compiler:"gc", Platform:"linux/amd64"}**此时,说明keepalived和haproxy都是成功,可以依次将其他Master节点的keepalived和haproxy启动。
此时,通过
ip a s命令去查看其中一台非主Master时看不到VIP,因为VIP永远只在主Master节点上,只有当主Master节点挂掉后,才会切换到其他Master节点上。
主Master获取VIP是需要时间的,如果多个Master同时启动,会导致冲突。最稳妥的方式是先启动一台主Master,等VIP确定后再启动其他Master。
0.7. 部署堆叠集群
0.7.1. 部署第一个控制平面节点
在第一个控制平面节点上创建
kubeadm-config.yaml文件:apiVersion: kubeadm.k8s.io/v1beta1 kind: ClusterConfiguration kubernetesVersion: stable # 应该设置为使用的版本,例如stable controlPlaneEndpoint: "LOAD_BALANCER_DNS:LOAD_BALANCER_PORT" # 应匹配负载均衡器的地址(或DNS)和端口 ClusterConfiguration: networking: podSubnet: 192.168.0.0/16建议kubeadm,kubelet,kubectl和Kubernetes的版本匹配。
注意,一些CNI网络插件,需要CIDR,如192.168.0.0/16,但是有些不需要。在
ClusterConfiguration配置项的networking对象中设置podSubnet:192.168.0.0/16字段来为Pod设置CIDR。初始化控制平台
sudo kubeadm init --config=kubeadm-config.yaml --experimental-upload-certs # --experimental-upload-certs参数用于将需要在所有控制平面节点之间共享的证书上传到集群中 # 删除这个参数,实现手动证书复制分发 # 命令执行完成后,会看到如下信息 ... You can now join any number of control-plane node by running the following command on each as a root:\ kubeadm join 192.168.0.200:6443 --token 9vr73a.a8uxyaju799qwdjv --discovery-token-ca-cert-hash \ sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866 \ --experimental-control-plane --certificate-key f8902e114ef118304e561c3ecd4d0b543adc226b7a07f675f56564185ffe0c07 Please note that the certificate-key gives access to cluster sensitive data, keep it secret!\ As a safeguard, uploaded-certs will be deleted in 2 hours; If necessary, you can use kubeadm init phase upload-certs to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root:\ kubeadm join 192.168.0.200:6443 --token 9vr73a.a8uxyaju799qwdjv \ --discovery-token-ca-cert-hash sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866 # 将输出信息保存到文本中,添加控制平面节点和工作节点到集群时,需要使用 # 在kubeadm init的时候使用了`experimental-upload-certs`参数后,主控制平面的证书被加密并上传到kubeadm-certs Secret中 # 要重新上传证书并生成新的解密密钥,请在已加入群集的控制平面节点上使用以下命令: sudo kubeadm init phase upload-certs --experimental-upload-certs注意,
kubeadm-certsSecret和解密秘钥的有效时间是两个小时。部署CNI插件
必须安装pod网络插件,以便pod可以相互通信,且每个集群只能安装一个Pod网络。
必须在任何应用程序之前部署网络。此外,CoreDNS将不会在安装网络之前启动。 kubeadm仅支持基于容器网络接口(CNI)的网络(并且不支持kubenet)。
注意,Pod网络不能与任何主机网络网络重叠。如果网络插件的首选Pod网络与某些主机网络之间发生冲突,应该考虑一个合适的CIDR替换,并在kubeadm init期间使用--pod-network-cidr并在网络插件的YAML中替换它。
- 安装Flannel时需要在
kubeadm init中添加参数--pod-network-cidr=10.244.0.0/16 - 设置
/proc/sys/net/bridge-nf-call-iptables的值为1,将桥接的IPv4流量传递给iptables的链 - 保防火墙规则允许参与覆盖网络的所有主机的UDP端口8285和8472流量
一旦pod网络安装完成,CoreDNS就能正常运行,然后就可以开始添加其他节点。
0.7.2. 添加其他控制平面节点
警告:只有在第一个节点完成初始化后,才能按顺序添加新的控制平面节点。
对于每一个控制平面节点,执行如下操作:
- 执行先前由第一个节点上的kubeadm init输出提供给您的join命令
sudo kubeadm join 192.168.0.200:6443 --token 9vr73a.a8uxyaju799qwdjv \
--discovery-token-ca-cert-hash sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866 \
--experimental-control-plane --certificate-key f8902e114ef118304e561c3ecd4d0b543adc226b7a07f675f56564185ffe0c07
# `--experimental-control-plane`参数是告诉kubeadm join创建一个新的控制平面节点
# ` --certificate-key`参数将导致控制平面证书从集群中下`kubeadm-certs`Secret中下载下来,并使用对应的秘钥进行解密其余控制平面节点添加完成后,开始添加worker节点。
0.7.3. 添加worker节点
可以使用先前存储的命令将工作节点连接到集群,作为kubeadm init命令的输出:
sudo kubeadm join 192.168.0.200:6443 --token 9vr73a.a8uxyaju799qwdjv \
--discovery-token-ca-cert-hash sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866