01-监控体系
kubernetes项目的监控体系曾经非常繁杂,如今已经演变为以Prometheus项目为核心的一套统一的方案。
0.1. Prometheus
与kubernetes一样,来自Google的Borg体系,原型系统是BorgMon,几乎与Borg同时诞生的内部监控系统。Prometheus与kubernetes一样,希望通过对用户友好的方式,将Google内部系统的设计理念,传递给用户和开发者。
作为一个监控系统,Prometheus项目的作用和工作方式,如下图所示:
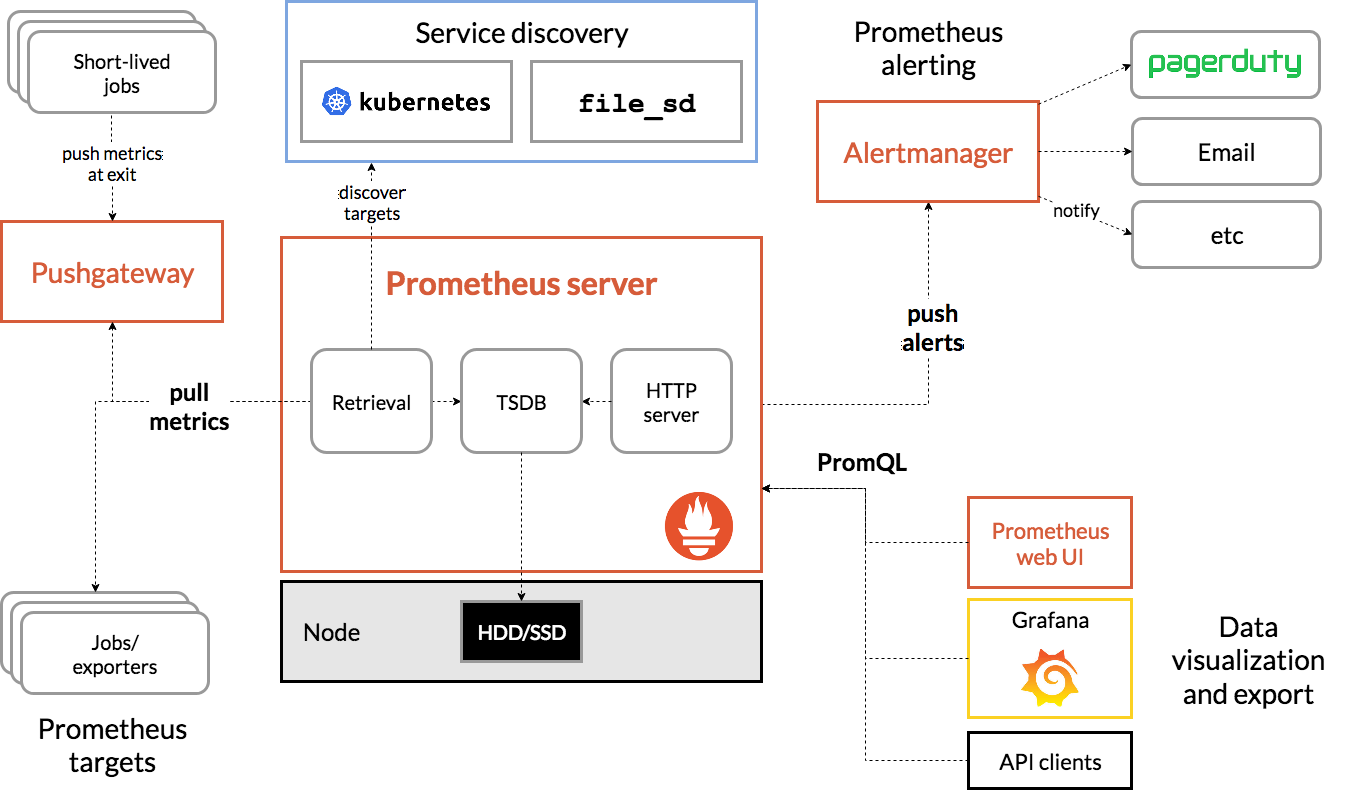
Prometheus项目工作的核心,是使用Pull(抓取)的方式去搜集被监控对象的Metrics数据(监控指标数据),然后,再把这些数据保存在一个TSDB(时序数据库,如OpenTSDB、InfluxDB等)当中,以便后续可以按照时间进行检索。有了这套核心的监控机制,剩下的组件就是用来配合这套机制运行的,如:
- Pushgateway,运行被监控对象以Push的方式向Prometheus推送Metrics数据
- Alertmanager,根据Metrics信息灵活地配置报警
- Grafana,对外暴露出可灵活配置的监控数据可视化界面
有了Prometheus之后,可以按照Metrics数据的来源,对kubernetes的监控体系做一个汇总:
- 第一种Metrics,是宿主机的监控数据。这部分数据借助Prometheus的Node Exporter工具,它以DaemonSet的方式运行在宿主机上。
所谓Exporter就是代替被监控对象来对Prometheus暴露出可以被抓取的Metrics信息的一个辅助进程。Node Exporter可以暴露给Prometheus采集的Metrics数据,也不单单是节点的负载(Load)、CPU、内存、磁盘以及网络等常规信息,还包括如下信息,参考这里https://github.com/prometheus/node_exporter#enabled-by-default。
- 第二种Metrics,是来自于kubernetes的APIServer、kubelet、等组件的/metrics API。除了常规的CPU、内存的信息外,还包括各组件的核心监控指标(如APIServer在/metrics API中暴露出各个Controller的工作队列的长度,请求的QPS和延迟数据等),这些信息是检查kubernetes本身工作情况的主要依据。
- 第三种Metrics,是kubernetes相关的监控数据(称为kubernetes核心监控数据core metrics)。包括Pod、Node、容器、Service等主要Kubernetes核心概念的Metrics。
其中容器相关的Metrics主要来自kubelet内置的cAdvisor服务(随着kubelet一起启动),它能够提供的信息可细化到每一个容器的CPU、文件系统、内存、网络等资源的使用。
这里提到的kubernetes核心监控数据,使用的是kubernetes的一个重要的扩展能力,Metrics Server。
Metrics Server在kubernetes社区的定位,是用来取代Heapster项目,早期使用Heapster是获取kubernetes的监控数据(如Pod和Node的资源使用情况)的主要渠道。Metrics Server则把这些信息,通过标准kubernetes API暴露出来,这样Metrics信息就跟Heapster完全解耦了,Heapster就退出了。
有了Metrics Server,用户可以通过标准的kubernetes API来访问这些监控数据,如下面的URL:
http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>访问这个API时,就会返回一个Pod的监控数据,这些数据是从kubelet的Summary API(<kubelet_ip>:<kubelet_port>/stats/summary)采集而来。Summary API返回的信息,既包括cAdVisor的监控数据,也包括kubelet本身汇总的信息。
Metrics Server并不是kube-apiserver的一部分,通过Aggregator插件机制,在独立部署的情况下同kube-apiserver一起统一对外服务。
0.2. Aggregator
Aggregator APIServer的工作原理如下图所示:
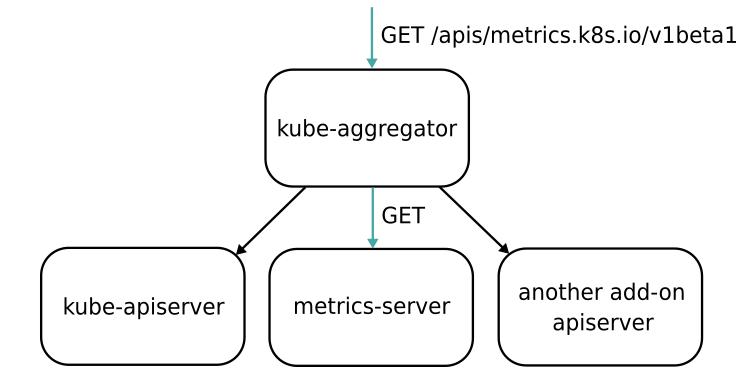
当kubernetes的API Server开启Aggregator模式后,访问apis/metrics.k8s.io/v1beta1的时候,实际上访问的是kube-aggregator的代理,而kube-apiserver真是这个代理的一个后端,Metrics Server是另一个后端。
在这种机制下,可以添加更多的后端给这个kube-aggregator,它其实是一个根据URL选择具体API的后端代理服务器。通过这种方式可以很方便的扩展kubernetes的API。
0.2.1. 开启Aggregator
- 使用kubeadm或者kube-up.sh脚本部署kubernetes集群,Aggregator模式是默认开启的
- 手动搭建,需要在kube-apiserver的启动参数中加上如下配置
--requestheader-client-ca-file=<path to aggregator CA cert>
--requestheader-allowed-names=front-proxy-client
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
--proxy-client-cert-file=<path to aggregator proxy cert>
--proxy-client-key-file=<path to aggregator proxy key>这些配置的作用,主要是为Aggregator这一层设置对应的key和cert文件。这些文件的生成需要手动完成,具体流程参考这里:https://github.com/kubernetes-incubator/apiserver-builder-alpha/blob/master/docs/concepts/auth.md
Aggregator功能开启之后,只需要将Metrics Server的YAML文件部署起来,如下所示:
$ git clone https://github.com/kubernetes-incubator/metrics-server
$ cd metrics-server
$ kubectl create -f deploy/1.8+/
# metrics.k8s.io这个API会出现在kubernetes API列表中作为用户只需要将Prometheus Operator在kubernetes集群里部署起来,然后把Metrics源配置起来,让Prometheus自己进行采集即可。
在具体的监控指标规划上,可采用业界统一的USE原则和RED原则。
USE原则指的是,按照如下三个维度来规划资源监控指标:
- 利用率(Utilization),资源被有效利用起来提供服务的平均时间占比
- 饱和度(Saturation),资源拥挤的程度,比如工作队的长度
- 错误率(Errors),错误的数量
RED原则指的是,按照如下三个维度规划服务监控指标:
- 每秒请求数量(Rate)
- 每秒错误数量(Errors)
- 服务响应时间(Duration)
USE原则主要关注资源,如某个节点和容器的资源使用情况,RED原则主要关注服务,如kube-apiserver或者某个应用的工作情况。
0.3. 自定义监控指标
借助于Prometheus监控体系,kubernetes可以提供非常拥有的能力Custom Metrics,自定义监控指标。
Auto Scaling,自动水平扩展,往往只能依据某种指定的类型资源(CPU、内存的使用值)执行水平扩展。在真是场景中,用户需要进行Auto Scaling的依据往往是自定义的监控指标(如某个应用的等待队列长度或者某种应用相关资源的使用情况)。
复杂多变的需求,在传统PaaS项目或容器编排中,比较难实现,而凭借强大的API扩展机制,Custom Metrics已经成为了kubernetes的一项标准能力。并且,kubernetes的自动扩展器组件Horizontal Pod Autoscaler(HPA),也可以直接使用Custom Metrics来执行用户指定的扩展策略,整个过程非常灵活。
kubernetes的Custom Metrics机制,借助于Aggregator APIServer扩展机制来实现,具体原理是,当Custom Metrics APIServer启动之后,kubernetes里就会出现一个叫作custom.metrics.k8s.io的API,访问这个URL时,Aggregator就会把请求转发给Custom Metrics APIServer。
Custom Metrics APIServer的实现,其实是一个Prometheus项目的Adaptor。
0.3.1. 例子
实现一个根据指定Pod收到的HTTP请求数量来进行Auto Scaling的Custom Metrics,这个Metrics就可以通过访问如下的自定义监控URL获取到:
https://<apiserver_ip>/apis/custom-metrics.metrics.k8s.io/v1beta1/namespaces/default/pods/sample-metrics-app/http_requests
# 当访问这个URL的时候,Custom Metrics APIServer就会去Prometheus里查询
# sample-metrics-app这个Pod的http_requests指标的值,然后按照固定的格式返回给访问者http_requests指标的值,需要Prometheus按照核心监控体系,从目标Pod上采集来,实现这个目标最普遍的做法是让Pod里的应用本身暴露出一个/metrics API,然后这个API里返回自己收到的HTTP的请求的数量。HPA只需要定时访问自定义监控URL,然后根据这些值计算是否要执行Scaling即可。
具体实现的例子如下,这个是GitHub库:
# 1.部署Prometheus项目。使用Prometheus Operator来完成
$ kubectl apply -f demos/monitoring/prometheus-operator.yaml
clusterrole "prometheus-operator" created
serviceaccount "prometheus-operator" created
clusterrolebinding "prometheus-operator" created
deployment "prometheus-operator" created
$ kubectl apply -f demos/monitoring/sample-prometheus-instance.yaml
clusterrole "prometheus" created
serviceaccount "prometheus" created
clusterrolebinding "prometheus" created
prometheus "sample-metrics-prom" created
service "sample-metrics-prom" created
# 2.把Custom Metrics APIServer部署起来
$ kubectl apply -f demos/monitoring/custom-metrics.yaml
namespace "custom-metrics" created
serviceaccount "custom-metrics-apiserver" created
clusterrolebinding "custom-metrics:system:auth-delegator" created
rolebinding "custom-metrics-auth-reader" created
clusterrole "custom-metrics-read" created
clusterrolebinding "custom-metrics-read" created
deployment "custom-metrics-apiserver" created
service "api" created
apiservice "v1beta1.custom-metrics.metrics.k8s.io" created
clusterrole "custom-metrics-server-resources" created
clusterrolebinding "hpa-controller-custom-metrics" created
# 3.为CustomMetrics APIServer创建对应的ClusterRoleBinding,以便能够使用curl来直接访问Custom Metrics的API
$ kubectl create clusterrolebinding allowall-cm --clusterrole custom-metrics-server-resources --user system:anonymous
clusterrolebinding "allowall-cm" created
# 4.把待监控的应用和HPA部署起来
$ kubectl apply -f demos/monitoring/sample-metrics-app.yaml
deployment "sample-metrics-app" created
service "sample-metrics-app" created
servicemonitor "sample-metrics-app" created # 这个是Prometheus Operator用来指定被监控Pod的一个配置文件
horizontalpod
scaler "sample-metrics-app-hpa" created
ingress "sample-metrics-app" createdServiceMonitor的yaml文件如下:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: sample-metrics-app
labels:
service-monitor: sample-metrics-app
spec:
selector:
matchLabels:
app: sample-metrics-app
endpoints:
- port: web
# 通过Label Selector为Prometheus指定被监控的应用HPA的yaml文件如下:
apiVersion:
scaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: sample-metrics-app-hpa
spec:
scaleTargetRef: # 指定被监控的对象,包括API、类型、名字
apiVersion: apps/v1
kind: Deployment
name: sample-metrics-app
minReplicas: 2 # 指定被监控对象的最小实例数目
maxReplicas: 10 # 指定被监控对象的最大实例数目
metrics: # 指定这个HPA进行Scale的依据
- type: Object
object: # 获取这个Metrics的途径,包括类型和名字
target:
kind: Service
name: sample-metrics-app
metricName: http_requests # Metrics的名字
targetValue: 100
# HPA的配置,就是设置Auto Scaling规则的地方有了以上yaml文件,HPA就可以向如下所示的URL发起请求来获取Custom Metrics的值:
https://<apiserver_ip>/apis/custom-metrics.metrics.k8s.io/v1beta1/namespaces/default/services/sample-metrics-app/http_requests
# 这个URL对应的被监控对象,是应用对应的Service,这与Pod的Custom Metrics URL不同
# 对于一个多实例应用来说,通过Service来采集Pod的Custom Metrics才是合理的做法# 通过hey测试工具来对应用增加一些访问压力:
$ # Install hey
$ docker run -it -v /usr/local/bin:/go/bin golang:1.8 go get github.com/rakyll/hey
$ export APP_ENDPOINT=$(kubectl get svc sample-metrics-app -o template --template {{.spec.clusterIP}}); echo ${APP_ENDPOINT}
$ hey -n 50000 -c 1000 http://${APP_ENDPOINT}
# 此时访问Service的Custom Metrics URL,就能看到这个URL已经可以返回应用收到的HTTP请求的数量
$ curl -sSLk https://<apiserver_ip>/apis/custom-metrics.metrics.k8s.io/v1beta1/namespaces/default/services/sample-metrics-app/http_requests
{
"kind": "MetricValueList",
"apiVersion": "custom-metrics.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom-metrics.metrics.k8s.io/v1beta1/namespaces/default/services/sample-metrics-app/http_requests"
},
"items": [
{
"describedObject": {
"kind": "Service",
"name": "sample-metrics-app",
"apiVersion": "/__internal"
},
"metricName": "http_requests",
"timestamp": "2018-11-30T20:56:34Z",
"value": "501484m"
}
]
}此处注意Custom Metrics API返回的Value格式,在为应用编写/metrics API的返回值时,比较容易计算的是该Pod收到的HTTP request的总数,代码如下:
if (request.url == "/metrics") {
response.end(
"# HELP http_requests_total The amount of requests served by the server in total\n"+
"# TYPE http_requests_total counter\nhttp_requests_total " + totalrequests + "\n");
return;
}
// 应用的/metrics对应的HTTP response里返回的,是http_request_total的值,也是Prometheus收集到的值。Custom Metrics APIServer在收到对http_requests指标的访问请求之后,从Prometheus里查询http_requests_total的值,然后把它折算成一个以时间为单位的请求率,最后把这个结果作为http_requests指标对应的值返回回去。
例子中的“501484m”,这里的格式是milli-requests(相当于10^-3),相当于在过去两分钟内,每秒有501个请求。这样就不需要关心如何计算每秒钟的请求个数,这样的请求率的格式是可以直接被HPA拿来使用的。