02-Scheduler
在kubernetes项目中,默认调度器的主要职责就是为一个新创建出来的Pod,寻找一个最适合的节点(Node)。
此处最合适的含义:
- 从集群所有的节点中,根据调度算法挑选出所有可以运行该Pod的节点
- 在上一步的结果中,在根据调度算法挑选一个最符合条件的节点作为最终结果
kubernetes发展的主旋律是整个开源项目的“民主化“,是组件的轻量化、接口化、插件化。所以有了CRI、CNI、CSI、CRD、Aggregated APIServer、Initializer、Device Plugin等各个层级的可扩展能力,默认调度器,却是kubernetes项目里最后一个没有对外暴露出良好的、定义过的、可扩展接口的组件。
0.1. 原理
默认调度器的具体的调度流程:
- 检查Node(调用Predicate算法)
- 给Node打分(调用Priority算法)
- 最高分Node(调度结果)
调度器对一个Pod调度成功,实际上就是将它的
spec.nodeName字段填上调度结果的Node名字。
上述调度机制的工作原理如下图所示:
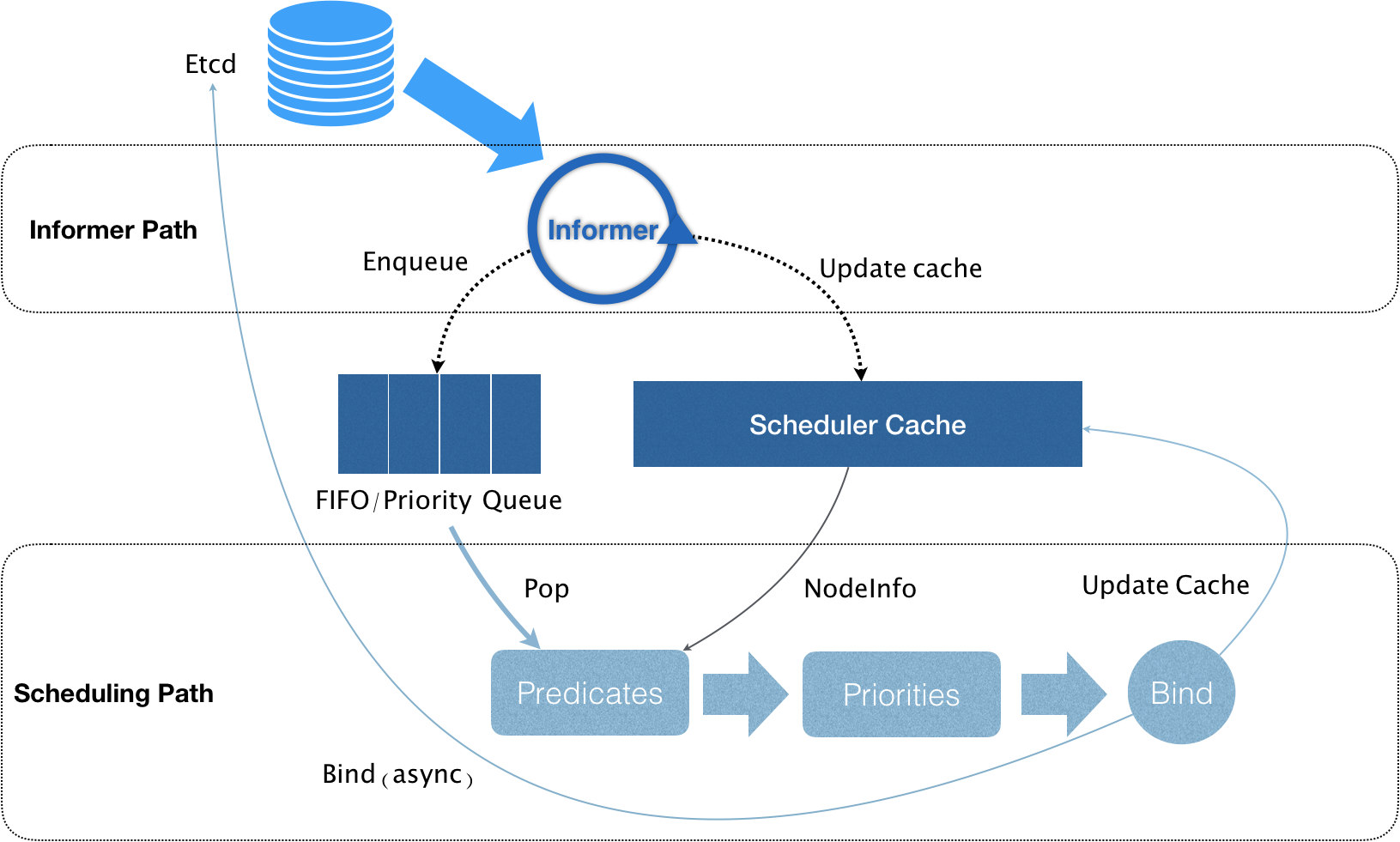
kubernetes的调度器的核心,实际上就是两个相互独立的控制循环。
0.1.1. Informer Path
主要目的是启动一系列Informer,用来监听(WATCH)Etcd中Pod、Node、Service等与调度相关的API对象的变化。
比如,当一个待调度Pod(即它的nodeName字段为空)被创建出来后,调度器就会通过Pod Informer的Handler将这个待调度Pod添加进调度队列。
在默认情况下,kubernetes的调度队列是一个PriorityQueue(优先级队列),并且当某些集群信息发生变化时,调度器还会对调度队列里的内容进行特殊的操作(调度优先级和抢占)。默认调度器还负责对调度器缓存进行更新,在kubernetes的调度部分进行性能优化的一个根本原则就是尽最大可能将集群信息Cache化,以便从根本上提高Predicate和Priority调度算法的执行效率。
0.1.2. Scheduling Path
调度器负责Pod调度的主循环,主要逻辑就是:
- 从调度队列里出队一个Pod
- 调用Predicate算法进行过滤,得到一组Node(所有可以运行这个Pod的宿主机列表)
Predicate算法需要的Node信息,都是从Scheduler Cache里直接拿到的,这是调度器保证算法执行效率的主要手段之一。
- 调度器再调用Priority算法为上述列表里的Node打分,分数从0到10,得分最高的Node作为这次调度的结果
- 调度算法执行完成后,调度器就需要将Pod对象的nodeName字段的值,修改为上述Node的名字(称为Bind)
为了不在关键调度路径里远程访问APIServer,kubernetes的默认调度器在Bind阶段,只会根据Scheduler Cache里的Pod和Node信息(这种基于乐观假设的API对象更新方式,称为Assume)。
- Assume之后,调度器会创建一个Goroutine来异步地向APIServer发起更新Pod的请求,来真正完成Bind操作
如果这次异步的Bind过程失败了,其实也没有太大关系,等Scheduler Cache同步之后一切就会恢复正常。
- 由于调度器的乐观绑定设计,当一个新的Pod完成调度需要在某个节点上运行起来之前,该节点上的kubelet会进行Admit操作,来再次验证该Pod是否能够运行在该节点上
Admit操作实际上就是把一组称为GeneralPredicates的最基本的调度算法,比如:资源是否可用、端口是否冲突等在执行一遍,作为kubelet端的二次确认。
0.1.2.1. 无锁化
除了上述过程中的Cache化和乐观绑定,默认调度器还有一个重要的设计:无锁化。在Scheduling Path 上:
- 调度器会启动多个Goroutine以节点为粒度并发执行Predicates算法,从而提高这一阶段的执行效率
- Priorities算法也会以MapReduce的方式并行计算然后再进行汇总
在这个需要并发的路径上,调度器会避免设置任何全局的竞争资源。从而避免去使用锁进行同步带来的巨大的性能损耗。
所以,kubernetes调度器只有对调度队列和Scheduler Cache进行操作时,才需要加锁,而这两部分操作,都不在Scheduling Path的算法执行路径上。
kubernetes调度器的上述设计思想,也是在集群规模不断增长的演进过程中逐步实现的,尤其是”Cache化“,这个变化是kubernetes调度器性能得以提升的一个关键演化。
0.2. kubernetes默认调度器的可扩展性设计
如下图所示:
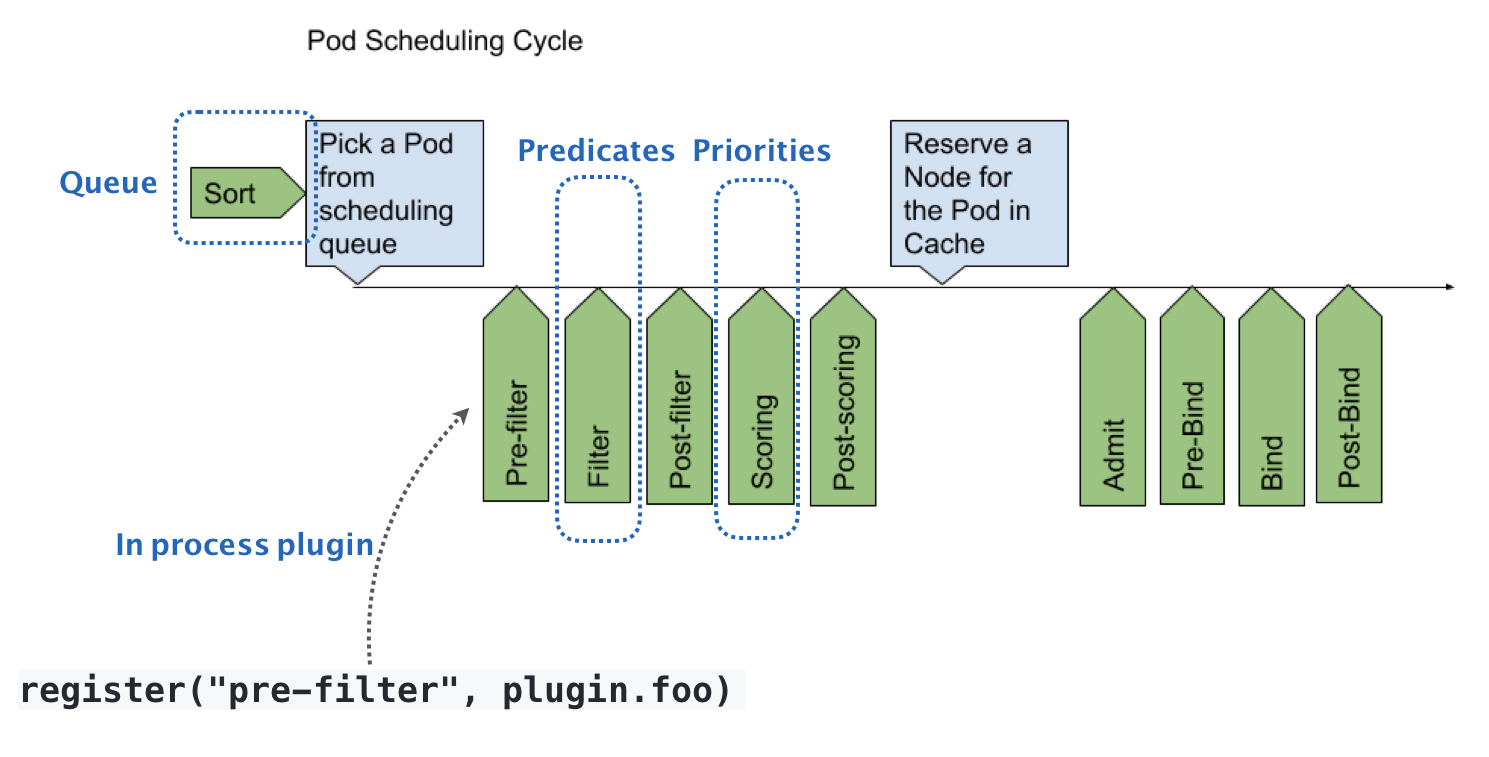
默认扩展器的可扩展机制,在kubernetes里叫作Scheduler Framework,这个设计的主要目的就是在调度器声明周期的各个关键点上,为用户暴露出可以进行扩展和实现的接口,从而实现有用户自定义调度器的能力。
每个绿色的箭头都是一个可以插入自定义逻辑的接口,如Queue部分可以提供一个自己的调度队列的实现,从而控制每个Pod开始被调度(出队)的时机。Predicates部分,意味着可以提供自定义的过滤算法实现,根据自己的需求,来决定选择哪些机器。这些可插拔式逻辑,都是标准的Go语言插件机制(Go plugin机制),需要在编译的时候选择把哪些插件编译进去。
0.3. 调度策略
在调度的过程中主要发生作用的是Predicates和Priorities两个调度策略。
0.3.1. Predicates
在调度的过程中,可以理解为Filter。按照调度策略,从当前集群的所有节点中,过滤出一些列符合条件的节点,这些节点都是可以运行待调度Pod的宿主机。目前,默认的调度策略有四种:
- GeneralPredicate
- Volume相关过滤规则
- 宿主机相关过滤规则
- Pod相关过滤规则
0.3.1.1. GeneralPredicate
这一组过滤规则负责的是最基础的调度策略:
| 调度策略 | 描述 |
|---|---|
| PodFitsResources | 宿主机的CPU和内存资源等是否够用 |
| PodFitsHost | 宿主机的名字是否跟Pod的spec.nodeName一致 |
| PodFitsHostPorts | Pod申请的宿主机端口(spec.nodePort)是不是跟已经被使用的端口有冲突 |
| PodMatchNodeSelector | Pod的nodeSelector或者nodeAffinity指定的节点,是否与待考察节点匹配 |
这一组GeneralPredicate正式Kubernetes考察一个Pod能不能运行在一个Node上最基本的过滤条件。所以,GeneralPredicate也会被其他组件(如kubelet在启动pod前,会执行Admit操作,就是再执行一次GeneralPredicate)直接调用。
PodFitsResources检查的只是Pod的requests字段,kubernetes的调度器没有为GPU等硬件资源定义具体的资源类型,而是统一用External Resource的,Key-Value格式的扩展字段来描述,如下例子。
apiVersion: v1
kind: Pod
metadata:
name: extended-resource-demo
spec:
containers:
- name: extended-resource-demo-ctr
image: nginx
resources:
requests:
alpha.kubernetes.io/nvidia-gpu: 2 # 声明使用两个NVIDIA类型的GPU
limits:
alpha.kubernetes.io/nvidia-gpu: 2在PodFitsResources里,调度器并不知道这个字段的key的含义是GPU,而是直接使用后面的value进行计算,在Node的Capacity字段了,需要相应的加上这台宿主机上GPU的总数(如alpha.kubernetes.io/nvidia-gpu=4)。
0.3.1.2. Volume相关过滤规则
这一组过滤规则,负责的是跟容器持久化Volume相关的调度策略:
| 调度策略 | 描述 |
|---|---|
| NoDiskConfict | 多个Pod声明挂载的持久化Volume是否冲突 |
| MaxPDVolumeCountPredicate | 一个节点上某种类型的持久化Volume是不是已经超过了一定数目,如果超过则声明该类型的持久化Voluem的Pod就不能再调度到这个节点上 |
| VolumeZonePredicate | 检查持久化Volume的Zone(高可用域)标签,是否与待考察节点的Zone标签相匹配 |
| VolumeBindingPredicate | Pod对应的PV的nodeAffinity字段是否与某个节点的标签相匹配 |
Local Persistent Volume(本地持久化卷),必须使用nodeAffinity来跟某个具体节点绑定,这就意味着Predicates节点,Kubernetes就必须能够根据Pod的Volume属性来进行调度。如果该Pod的PVC还没有跟具体的PV绑定,调度器还要负责检查所有待绑定PV,当有可用的PV存在并且该PV的nodeAffinity与待考察节点一致时,VolumeBindingPredicate这条规则才会返回成功,如下所示。
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-local-pv
spec:
capacity:
storage: 500Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage
local:
path: /mnt/disks/vol1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- my-node这个PV对应的持久化目录,只能出现在my-node宿主机上,任何一个通过PVC使用这个PV的Pod,都必须被调度到my-node上可以正常工作,VolumeBindingPredicate正是调度器里完成这个决策的位置。
0.3.1.3. 宿主机相关过滤规则
这一组规则主要考察待调度Pod是否满足Node本身的某些条件:
| 调度策略 | 描述 |
|---|---|
| PodToleratesNodeTaints | 检查Node的污点,只要Pod的Toleration字段与Node的Taint字段匹配,Pod才会被调度到该节点 |
| NodeMemoryPressurePredicate | 检查当前节点的内存是否已经不够充足,如果是,待调度Pod就不能被调度到该节点上 |
0.3.1.4. Pod相关过滤规则
这一组规则,与GeneralPredicates大多数是重合的,比较特殊的是:
| 调度策略 | 描述 |
|---|---|
| PodAffinityPredicate | 检查待调度Pod与Node上的已有Pod之间的亲密(Affinity)和反亲密(Anti-Affinity)关系 |
如下面的例子:
# podAntiAffinity
apiVersion: v1
kind: Pod
metadata:
name: with-pod-antiaffinity
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: docker.io/ocpqe/hello-pod
# podAntiAffinity规则就是指定这个Pod不希望跟任何携带了security=S2标签的Pod存在与同一个Node上
# PodAffinityPredicate的作用域,如上kubernetes.io/hostname标签的Node有效
# 这是topologykey关键词的作用
# podAffinity
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: failure-domain.beta.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: docker.io/ocpqe/hello-pod
# podAffinity规则就是只会调度已经有携带了security=S1标签的Pod运行的Node上
# podAffinity的作用域,如上failure-domain.beta.kubernetes.io/zone标签的Node有效例子中requiredDuringSchedulingIgnoredDuringExecution字段的含义是:
- 这条规则必须在Pod调度是进行检查(requiredDuringScheduling)
- 如果已经在运行的Pod发生变化(如Label被修改),造成不再适合运行在这个Node上的时候,kubernetes不会进行主动修改(IgnoredDuringExecution)
在具体执行的时候,当开始调度一个Pod时,kubernetes调度器会同时启动16个Goroutine,来并发地为集群里的所有Node计算Predicates,最后返回可以运行这个Pod的宿主机列表。
每个Node执行Predicates时,调度器会按照规定的顺序来进行检查。这个顺序是按照Predicates本身的含义确定的。如宿主机相关的Predicates会被放在相对靠前的位置进行检查。否则一台资源严重不足的宿主机上来就开始计算PodAffinityPredicate是没有实际意义的。
0.3.2. Priorities
在Predicates阶段完成了节点的“过滤”后,Priorities阶段的工作就是为这些节点打分(0-10分),得分最高的节点就是最后被Pod绑定的最佳节点。
| 调度规则 | 描述 |
|---|---|
| LeastRequestPriority | 选择空闲资源最多的宿主机 |
| BalancedResourceAllocation | 选择各种资源分配最均衡的宿主机 |
| NodeAffinityPriority | 与PodMatchNodeSelector的含义和计算方法类似,一个Node满足上述规则的字段数越多,得分越高 |
| TaintTolerationPriority | PodToleratesNodeTaints的含义和计算方法类似,一个Node满足上述规则的字段数越多,得分越高 |
| InterPodAffinityPriority | PodAffinityPredicate的含义和计算方法类似,一个Node满足上述规则的字段数越多,得分越高 |
| ImageLocalityPriority | v1.12中的新调度规则,如果待调度Pod需要使用的镜像很大,并且已经存在与某些Node上,那么这些Node的得分就会比较高 |
最常用的打分规则是LeastRequestPriority,计算公式如下:
score = (cpu((capacity-sum(requested))10/capacity) + memory((capacity-sum(requested))10/capacity))/2
# 这个算法实际上是在选择空闲资源(CPU和内存)最多的宿主机与LeastRequestPriority一起发挥作用的还有BalancedResourceAllocation,它的计算公式如下:
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)*10
# 每种资源的Fraction的定义是:Pod请求的资源/节点上的可用资源。
# variance算法的作用是计算没两种资源Fraction之间的距离
# 最后选择的是资源Fraction差距最小的节点BalancedResourceAllocation选择的是调度完成后,所有节点里各种资源分配最均衡的那个节点,从而避免一个节点上CPU被大量分配而内存大量剩余的情况。
为了避免ImageLocalityPriority算法引擎调度堆叠,调度器在计算得分的时候,还会根据镜像的分布进行优化,如果大镜像分布的节点数目很少,那么这些节点的权重就会被降低,从而“对冲”掉引起调度堆叠的风险。
在实际执行中,调度器中关于集群和Pod的信息已经缓存化,所有这些算法的执行过程比较快。
对于比较复杂的调度算法,如PodAffinityPredicate,在计算的时候不止关注待调度Pod和待考察Node,还需要关注整个集群的信息,如遍历所有节点,读取它们的Labels。kubernetes调度器会在为每个待调度Pod执行该调度算法之前,先将算法需要的集群信息初步计算一遍,然后缓存起来。这样,在真正执行该算法的时候,调度器只需要读取缓存信息进行计算即可,从而避免了为每个Node计算Predicates的时候反复获取和计算整个集群的信息。
在kubernetes调度器里其实还有一些默认不开启的策略,可以通过为kube-Scheduler指定一个配置文件或者创建一个ConfigMap,来配置哪些规则需要开启,哪些规则需要关闭,并且可以通过为Priorties设置权重,来控制调度器的调度行为。
0.4. 优先级(Priority)和抢占机制(Preemption)
优先级与抢占机制解决的是Pod调度失败时该怎么办的问题。
正常情况下,当一个Pod调度失败后,他就会被暂时“搁置”,直到Pod被更新,或者集群状态发生变化,调度器才会对这个Pod进行重新调度。
特殊情况下,当一个高优先级的Pod调度失败后,该Pod并不会被“搁置”,而是会“挤走”某个Node上的一些低优先级的Pod,这样就能保证这个高优先级Pod的调度成功。
v1.10版本之后,要使用这个机制,需要在kubernetes里提交一个PriorityClass的定义,如下所示:
# 创建PriorityClass
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000 # 一百万
globalDefault: false # 设置为true意味着PriorityClass的值会成为系统的默认值
# false表示该PriorityClass的Pod拥有值为1000000的优先级
# 没有声明PriorityClass的Pod来说,优先级为0
description: "This priority class should be used for high priority service pods only."
# 创建Pod,声明使用上面的PriorityClass
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority # Pod提交后,kubernetes的PriorityAdmissionController
# 就会自动将pod的spec.priority字段设置为1000000kubernetes规定,优先级是一个32bit的整数,最大值不超过十亿,并且值越大代表优先级越高。而大于十亿的值,其实是被kubernetes保留下来分配给系统Pod使用的。这样的目的就是保证系统Pod不会被用户抢占掉。
优先级 在调度器里维护着一个调度队列,当Pod拥有了优先级之后,高优先级的Pod就可能会比低优先级的Pod提前出队,从而尽早完成调度过程,这个过程就是“优先级”这个概念在kubernetes里的主要体现。
抢占 当一个高优先级的Pod调度失败的时候,调度器的抢占能力就会被触发,这时调度器就会试图从当前集群里寻找一个节点,使得当前这个节点上的一个或者多个低优先级的Pod被删除后,待调度高优先级Pod就可以被调度到这个节点上。这个过程,就是“抢占”这个概念在kubernetes里的主要体现。
将高优先级Pod称为抢占者,当上述抢占过程发生时:
- 抢占者并不会立刻被调度到被抢占的Node上,调度器只会将抢占者的
spec.nominatedNodeName字段,设置为被抢占的Node的名字 - 抢占者会重新进入下一个调度周期
- 在新的调度周期来决定是不是要运作在被抢占的节点上
- 在下一个周期,调度器也不能保证抢占者一定会运行在被抢占的节点上
这样设计的重要原因是,调度器只会通过标准的DELETE API来删除被抢占的Pod,所有,这些Pod必然是有一定的“优雅退出”时间(默认30秒),在这段时间里,其他节点也可能会变成能够调度的,或者有新节点加入集群中,所以鉴于优雅退出期间,集群的可调度性可能会发生变化,把抢占者交给下一个调度周期再处理,是一个非常合理的选择。 在抢占者等待被调度的过程中,如果有其他更高优先级的Pod也要抢占同一个节点,那么调度器就会清空原抢占者的
spec.nominatedNodeName字段,从而运行更高级别的抢占者执行抢占,并且原抢占者也有机会重新抢占其他节点,这是设置nominatedNodeName字段的主要目的。
0.4.1. 抢占机制的设计
抢占发生的原因一定是一个高优先级的Pod调度失败,高优先级Pod成为“抢占者”,被抢占的Pod为“牺牲者”。
kubernetes调度器实现抢占算法的一个重要设计就是在调度队列的实现里,使用了两个不同的队列:
- activeQ:凡是在activeQ里的Pod都是下一个调度周期需要调度的对象
- unschedulableQ:专门用来存储调度失败的Pod,在这个队列中的Pod被更新后,调度器会自动把Pod移动到activeQ,从而给一次重新调度的机会
调度失败后,抢占者进入unschedulableQ,这次失败时间会触发调度器为抢占者寻找牺牲者的流程:
- 调度器检查这次失败事件的原因,来确认抢占是不是可以帮助抢占者找到一个新节点,因为有很多Predicate的失败是不能通过抢占来解决的。
如PodFitsHost算法,负责检查Pod的nodeSelector与Node的名字是否匹配,除非Node的名字发生变化,否则即使删除再多Pod也不能调度成功的
- 如果确定抢占可以发生,那么调度器就会把自己缓存的所有节点信息复制一份,然后使用这个副本来模拟抢占过程
抢占的过程就是调度器检查缓存副本里的每一个节点,然后从该节点上最低优先级的Pod开始,逐一删除这些Pod,每删除一个Pod调度器都会检查一下抢占者是否能够运行在该Node上,一旦可以运行,调度器就会记录下这个Node的名字和被删除Pod的列表,这就是一次抢占过程的结果。
0.4.2. 抢占操作
得到了最佳的抢占结果之后,这个结果里的Node,就是即将被抢占的Node,被删除的Pod列表就是牺牲者,然后调度器开始真正的抢占操作,分为三个步骤:
- 调度器检查牺牲者列表,清理这些Pod所携带的nominatedNodeName字段
- 调度器会把抢占者的nominatedNodeName设置为被抢占者的Node名字(此处出发从unschedulableQ到activeQ的过程)
- 调度器会开启一个Goroutine,同步删除牺牲者
- 调度器通过正常的调度流程把抢占者调度成功(在这个正常的调度流程里,一切皆有可能,所有调度器并不会保证抢占的结果)
对于任何一个待调度Pod来说,因为存在上述抢占者,它的调度过程,是有一些特殊情况需要处理的,具体来说,在为某一对Pod和Node执行Predicates算法的时候,如果待检测的Node是一个即将被抢占的节点,即调度队列里有nominatedNodeName字段值是该Node名字的Pod存在(潜在抢占者),调度器就会对这个Node将同样的Predicates算法运行两遍。
- 第一遍,调度器假设上述“潜在的抢占者”已经运行在这个节点上,然后执行Predicates算法
- 第二遍,调度器正常执行Predicates算法,不考虑潜在的抢占者
只有这两遍Predicates算法都通过时,这个Pod和Node才会被认为是可以绑定的。
执行第一遍的原因是InterPodAffinity规则的存在,该规则关系待考察节点上所有Pod之间的互斥性,所以在执行调度算法时必须考虑,如果抢占者已经存在于待考察Node上,待调度Pod还能不能调度成功。这里只需要考虑优先级大于等于待调度Pod的抢占者。
执行第二遍Predicates算法的原因是,潜在抢占者最后不一定会运行在待考察的Node上。因为kubernetes调度器并不会保证抢占者一定会运行在当初选定的被抢占的Node上。
0.5. 总结
Pod的优先级和抢占机制是在v1.11版之后是Beta了,性能稳定可以使用,从而提高集群的资源利用率。
当整个集群发生可能会影响调度结果的变化,如添加或者更新Node、添加或者更新PV、Service等,调度器会执行MoveAllToActiveQueue的操作,把所有调度失败的Pod从unschedulableQ移动到activeQ里面。
当一个已经调度成功的Pod被更新时,调度器会将unschedulableQ里所更整个Pod有Affinity/Anti-Affinity关系的Pod,移动activeQ里面。