07-Operator
- 0.1. 例子
- 0.2. Operator工作原理
- 0.3. Etcd集群的构建方式
- 0.4. Etcd Operator构建过程
- 0.5. 编写EtcdCluster这个CRD
- 0.6. Operator创建集群
- 0.7. Etcd Operator工作原理
- 0.8. Operator与StatefulSet对比
管理有状态应用的另一个解决方方案:Operator。
0.1. 例子
Etcd Operator。
- 克隆仓库
git clone https://github.com/coreos/etcd-operator- 部署Operator
$ example/rbac/create_role.sh
# 为Etcd Operator创建RBAC规则,
# 因为Etcd Operator需要访问APIServer具体的为Etcd OPerator定义了如下所示的权限:
- 具有Pod、Service、PVC、Deployment、Secret等API对象的所有权限
- 具有CRD对象的所有权限
- 具有属于etcd.database.coreos.com这个API Group的CR对象的所有权限
Etcd Operator本身是一个Deployment,如下所示:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: etcd-operator
spec:
replicas: 1
template:
metadata:
labels:
name: etcd-operator
spec:
containers:
- name: etcd-operator
image: quay.io/coreos/etcd-operator:v0.9.2
command:
- etcd-operator
env:
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
...创建这个Etcd Operator:
$ kubectl create -f example/deployment.yaml
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
etcd-operator-649dbdb5cb-bzfzp 1/1 Running 0 20s
$ kubectl get crd
NAME CREATED AT
etcdclusters.etcd.database.coreos.com 2018-09-18T11:42:55Z有一个名叫etcdclusters.etcd.database.coreos.com的CRD被创建,查看它的具体内容:
$ kubectl describe crd etcdclusters.etcd.database.coreos.com
...
Group: etcd.database.coreos.com
Names:
Kind: EtcdCluster
List Kind: EtcdClusterList
Plural: etcdclusters
Short Names:
etcd
Singular: etcdcluster
Scope: Namespaced
Version: v1beta2
...这个CRD告诉kubernetes集群,如果有API组(Group)是etcd.database.coreos.com,API资源类型(Kind)是EtcdCluster的YAML文件被提交时,就能够认识它。
上述操作是在集群中添加了一个名叫EtcdCluster的自定义资源类型,Etcd Operator本身就是这个自定义资源类型对应的自定义控制器。
Etcd Operator部署好之后,在集群中创建Etcd集群的工作就直接编写EtcdCluster的YAML文件就可以,如下:
$ kubectl apply -f example/example-etcd-cluster.yaml
# example-etcd-cluster.yaml文件描述了3个节点的Etcd集群
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
example-etcd-cluster-dp8nqtjznc 1/1 Running 0 1m
example-etcd-cluster-mbzlg6sd56 1/1 Running 0 2m
example-etcd-cluster-v6v6s6stxd 1/1 Running 0 2m具体看一下example-etcd-cluster.yaml的文件内容,如下:
apiVersion: "etcd.database.coreos.com/v1beta2"
kind: "EtcdCluster"
metadata:
name: "example-etcd-cluster"
spec:
size: 3
version: "3.2.13"这个yaml文件的内容很简单,只有集群节点数3,etcd版本3.2.13,具体创建集群的逻辑有Etcd Operator完成。
0.2. Operator工作原理
- 利用kubernetes的自定义API资源(CRD)来描述需要部署的有状态应用
- 在自定义控制器里,根据自定义API对象的变化,来完成具体的部署和运维工作
编写Operator和编写自定义控制器的过程,没什么不同。
0.3. Etcd集群的构建方式
Etcd Operator部署Etcd集群,采用的是静态集群(Static)的方式。
静态集群:
- 好处:它不必依赖于一个额外的服务发现机制来组建集群,非常适合本地容器化部署。
- 难点:必须在部署的时候就规划好这个集群的拓扑结构,并且能够知道这些节点固定的IP地址,如下所示。
$ etcd --name infra0 --initial-advertise-peer-urls http://10.0.1.10:2380 \
--listen-peer-urls http://10.0.1.10:2380 \
...
--initial-cluster-token etcd-cluster-1 \
--initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
--initial-cluster-state new
$ etcd --name infra1 --initial-advertise-peer-urls http://10.0.1.11:2380 \
--listen-peer-urls http://10.0.1.11:2380 \
...
--initial-cluster-token etcd-cluster-1 \
--initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
--initial-cluster-state new
$ etcd --name infra2 --initial-advertise-peer-urls http://10.0.1.12:2380 \
--listen-peer-urls http://10.0.1.12:2380 \
...
--initial-cluster-token etcd-cluster-1 \
--initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
--initial-cluster-state new启动三个Etcd进程,组建三节点集群。当infra2节点启动后,这个Etcd集群中就会有infra0、infra1、infra2三个节点。节点的启动参数-initial-cluster正是当前节点启动时集群的拓扑结构,也就是当前界定在启动的时候,需要跟那些节点通信来组成集群。
--initial-cluster参数是由“<节点名字>=<节点地址>”格式组成的一个数组。--listen-peer-urls参数表示每个节点都通过2380端口进行通信,以便组成集群。--initial-cluster-token字段,表示集群独一无二的Token。
编写Operator就是要把上述对每个节点进行启动参数配置的过程自动化完成,即使用代码生成每个Etcd节点Pod的启动命令,然后把它们启动起来。
0.4. Etcd Operator构建过程
0.5. 编写EtcdCluster这个CRD
CRD对应的内容在types.go文件中,如下所示:
// +genclient
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
type EtcdCluster struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec ClusterSpec `json:"spec"`
Status ClusterStatus `json:"status"`
}
type ClusterSpec struct {
// Size is the expected size of the etcd cluster.
// The etcd-operator will eventually make the size of the running
// cluster equal to the expected size.
// The vaild range of the size is from 1 to 7.
Size int `json:"size"`
...
}EtcdCluster是一个有Status字段的CRD,在Spec中只需要关心Size(集群的大小)字段,这个字段意味着需要调整集群大小时,直接修改YAML文件即可,Operator会自动完成Etcd节点的增删操作。
这种scale能力,也是Etcd Operator自动化运维Etcd集群需要实现的主要功能。为了实现这个功能,不能在--initial-cluster参数中把拓扑结构固定死。所有Etcd Operator在构建集群时,虽然也是静态集群,但是是通过逐个节点动态添加的方式实现。
0.6. Operator创建集群
- Operator创建“种子节点”
- Operator创建新节点,逐一加入集群中,直到集群节点数等于size
生成不同的Etcd Pod时,Operator要能够区分种子节点和普通节点,这两个节点的不同之处在--initial-cluster-state这个启动参数:
- 参数值设为new,表示为种子节点,种子节点不需要通过
--initial-cluster-token声明独一无二的Token - 参数值为existing,表示为普通节点,Operator将它加入已有集群
需要注意,种子节点启动时,集群中只有一个节点,即
--initial-cluster参数的值为infra0=<http://10.0.1.10:2380>,其他节点启动时,节点个数依次增加,即--initial-cluster参数的值不断变化。
0.6.1. 启动种子节点
用户提交YAML文件声明要创建EtcdCluster对象,Etcd Operator先创建一个单节点的种子集群,并启动它,启动参数如下:
$ etcd
--data-dir=/var/etcd/data
--name=infra0
--initial-advertise-peer-urls=http://10.0.1.10:2380
--listen-peer-urls=http://0.0.0.0:2380
--listen-client-urls=http://0.0.0.0:2379
--advertise-client-urls=http://10.0.1.10:2379
--initial-cluster=infra0=http://10.0.1.10:2380 # 目前集群只有一个节点
--initial-cluster-state=new # 参数值为new表示是种子节点
--initial-cluster-token=4b5215fa-5401-4a95-a8c6-892317c9bef8 # 种子节点需要唯一指定token这个创建种子节点的阶段称为:Bootstrap。
0.6.2. 添加普通节点
对于其他每个节点,Operator只需要执行如下两个操作即可:
# 通过Etcd命令行添加新成员
$ etcdctl member add infra1 http://10.0.1.11:2380
# 为每个成员节点生成对应的启动参数,并启动它
$ etcd
--data-dir=/var/etcd/data
--name=infra1
--initial-advertise-peer-urls=http://10.0.1.11:2380
--listen-peer-urls=http://0.0.0.0:2380
--listen-client-urls=http://0.0.0.0:2379
--advertise-client-urls=http://10.0.1.11:2379
--initial-cluster=infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380 #目前集群有两个节点
--initial-cluster-state=existing # 参数值为existing表示为普通节点,并且不需要唯一的token继续添加,直到集群数量变成size为止。
0.7. Etcd Operator工作原理
与其他自定义控制器一样,Etcd Operator的启动流程也是围绕Informer,如下:
func (c *Controller) Start() error {
for {
err := c.initResource()
...
time.Sleep(initRetryWaitTime)
}
c.run()
}
func (c *Controller) run() {
...
_, informer := cache.NewIndexerInformer(source, &api.EtcdCluster{}, 0, cache.ResourceEventHandlerFuncs{
AddFunc: c.onAddEtcdClus,
UpdateFunc: c.onUpdateEtcdClus,
DeleteFunc: c.onDeleteEtcdClus,
}, cache.Indexers{})
ctx := context.TODO()
// use workqueue to avoid blocking
informer.Run(ctx.Done())
}Etcd Operator:
- 第一步,创建EtcdCluster对象所需的CRD,即etcdclusters.etcd.database.coreos.com
- 第二步,定义EtcdCluster对象的Informer
注意,Etcd Operator并没有使用work queue来协调Informer和控制循环。
因为在控制循环中执行的业务逻辑(如创建Etcd集群)往往比较耗时,而Informer的WATCH机制对API对象变化的响应,非常迅速。所以控制器里的业务逻辑会拖慢Informer的执行周期,甚至可能block它,要协调快慢任务典型的解决方案,就是引入工作队列。
在Etcd Operator里没有工作队列,在它的EventHandler部分,就不会有入队的操作,而是直接就是每种事件对应的具体的业务逻辑。Etcd Operator在业务逻辑的实现方式上,与常规自定义控制器略有不同,如下所示:
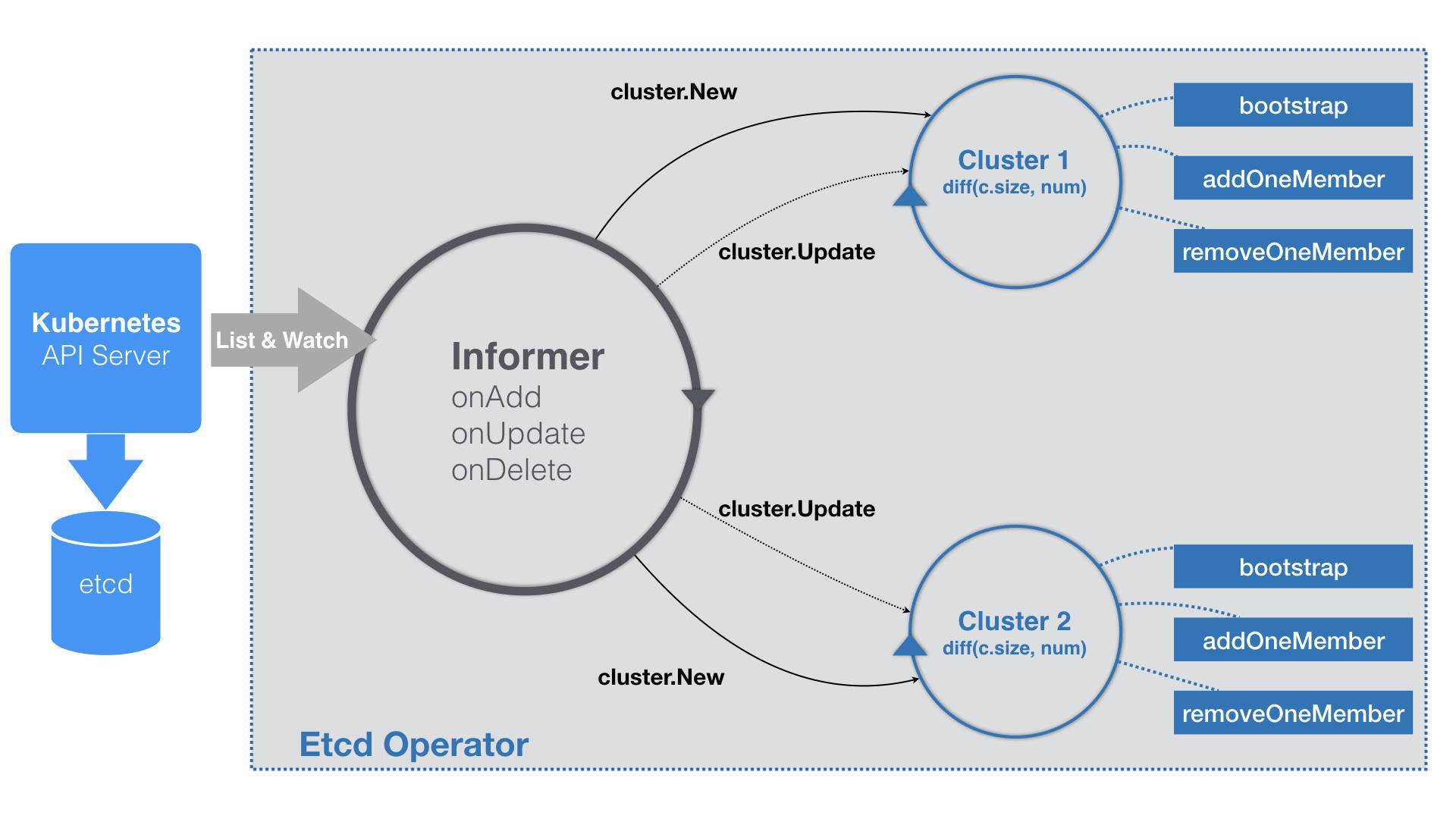
不同之处在于,Etcd Operator为每一个EtcdCluster对象都启动一个控制循环,并发地响应这些对象的变化。这样不仅可以简化Etcd Operator的代码实现,还有助于提高响应速度。
0.8. Operator与StatefulSet对比
- StatefulSet里,它为Pod创建的名字是带编号的,这样就把整个集群的拓扑状态固定,而在Operator中名字是随机的
Etcd Operator在每次添加节点或删除节点时都执行
etcdctl命令,整个过程会更新Etcd内部维护的拓扑信息,所以不需要在集群外部通过编号来固定拓扑关系。
- 在Operator中没有为EtcdCluster对象声明Persistent Volume,在节点宕机时,是否会导致数据丢失?
- Etcd是一个基于Raft协议实现的高可用键值对存储,根据Raft协议的设计原则,当Etcd集群里只有半数以下的节点失效时,当前集群依然可用,此时,Etcd Operator只需要通过控制循环创建出新的Pod,然后加入到现有集群中,就完成了期望状态和实际状态的调谐工作。
- 当集群中半数以上的节点失效时,这个集群就会丧失数据写入能力,从而进入“不可用”状态,此时,即使Etcd Operator 创建出新的Pod出来,Etcd集群本身也无法自动恢复起来。这个时候就必须使用Etcd本身的备份数据(由单独的Etcd Backup Operator完成)来对集群进行恢复操作。
创建和使用Etcd Backup Operator的过程:
# 首先,创建 etcd-backup-operator
$ kubectl create -f example/etcd-backup-operator/deployment.yaml
# 确认 etcd-backup-operator 已经在正常运行
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
etcd-backup-operator-1102130733-hhgt7 1/1 Running 0 3s
# 可以看到,Backup Operator 会创建一个叫 etcdbackups 的 CRD
$ kubectl get crd
NAME KIND
etcdbackups.etcd.database.coreos.com CustomResourceDefinition.v1beta1.apiextensions.k8s.io
# 我们这里要使用 AWS S3 来存储备份,需要将 S3 的授权信息配置在文件里
$ cat $AWS_DIR/credentials
[default]
aws_access_key_id = XXX
aws_secret_access_key = XXX
$ cat $AWS_DIR/config
[default]
region = <region>
# 然后,将上述授权信息制作成一个 Secret
$ kubectl create secret generic aws --from-file=$AWS_DIR/credentials --from-file=$AWS_DIR/config
# 使用上述 S3 的访问信息,创建一个 EtcdBackup 对象
$ sed -e 's|<full-s3-path>|mybucket/etcd.backup|g' \
-e 's|<aws-secret>|aws|g' \
-e 's|<etcd-cluster-endpoints>|"http://example-etcd-cluster-client:2379"|g' \
example/etcd-backup-operator/backup_cr.yaml \
| kubectl create -f -注意,每次创建一个EtcdBackup对象,就相当于为它所指定的Etcd集群做了一次备份。EtcdBackup对象的etcdEndpoints字段,会指定它要备份的Etcd集群的访问地址。在实际环境中,可以把备份操作编写成一个CronJob。
当Etcd集群发生故障时,可以通过创建一个EtcdRestore对象来完成恢复操作。需要事先创建Etcd Restore Operator,如下:
# 创建 etcd-restore-operator
$ kubectl create -f example/etcd-restore-operator/deployment.yaml
# 确认它已经正常运行
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
etcd-restore-operator-4203122180-npn3g 1/1 Running 0 7s
# 创建一个 EtcdRestore 对象,来帮助 Etcd Operator 恢复数据,记得替换模板里的 S3 的访问信息
$ sed -e 's|<full-s3-path>|mybucket/etcd.backup|g' \
-e 's|<aws-secret>|aws|g' \
example/etcd-restore-operator/restore_cr.yaml \
| kubectl create -f -当一个EtcdRestore对象创建成功之后,Etcd Restore Operator就会通过上述信息,恢复出一个全新的Etcd集群,然后Etcd Operator会把这个新的集群直接接管从而重新进入可用状态。