04-Kubernetes本质
"容器",实际上是一个由Linux Namespace、Linux Cgroups和rootfs三种技术构建出来的进程的隔离环境。
一个正在运行的容器可以被“一分为二”看待:
- 一组联合挂载在
/var/lib/docker/aufs/mnt上的rootfs,这部分称为“容器镜像”,是容器的静态视图。 - 一个由Namespace+Cgroups构成的隔离环境,这部分称为“容器运行时”,是容器的动态视图。
作为一个开发者,我们并不关心容器运行时的差异,因为,在整个“开发->测试->发布”的流程中,真正承载着容器信息进行传递的,是容器镜像,而不是运行时。
这也正是在Docker项目成功后,迅速走向“容器编排”这个“上层建筑”的主要原因。
- 作为一家云服务商或者基础设施提供商,只要能够将用户提交的Docker镜像以容器的方式运行起来,就能够成为容器生态圈上的一个承载点,从而将整个容器技术栈上的价值,沉淀在这个节点上。
- 从这个承载点向Docker镜像制作者和使用者方向回溯,整条路径上的各个服务节点,比如CI/CD、监控、安全、网络、存储等,都有可以发挥和盈利的余地。
这个逻辑正是所有云计算提供商如此热衷容器技术的重要原因:通过容器镜像,它们可以和潜在用户(开发者)直接关联起来。
- 从单一容器到容器集群,容器技术实现了从“容器”到“容器云”的飞跃,标志着它真正得到了市场和生态的认可。
- 容器从开发者手中一个小工具,成为了云计算领域的主角,能够定义容器组织和管理规范的“容器编排”技术,则坐上了容器技术的“头把交椅”。
容器编排工具:
- Compose+Swarm (Docker)
- Kubernetes (Google + RedHat)
谷歌公开发表的基础设施体系(The Google Stack):
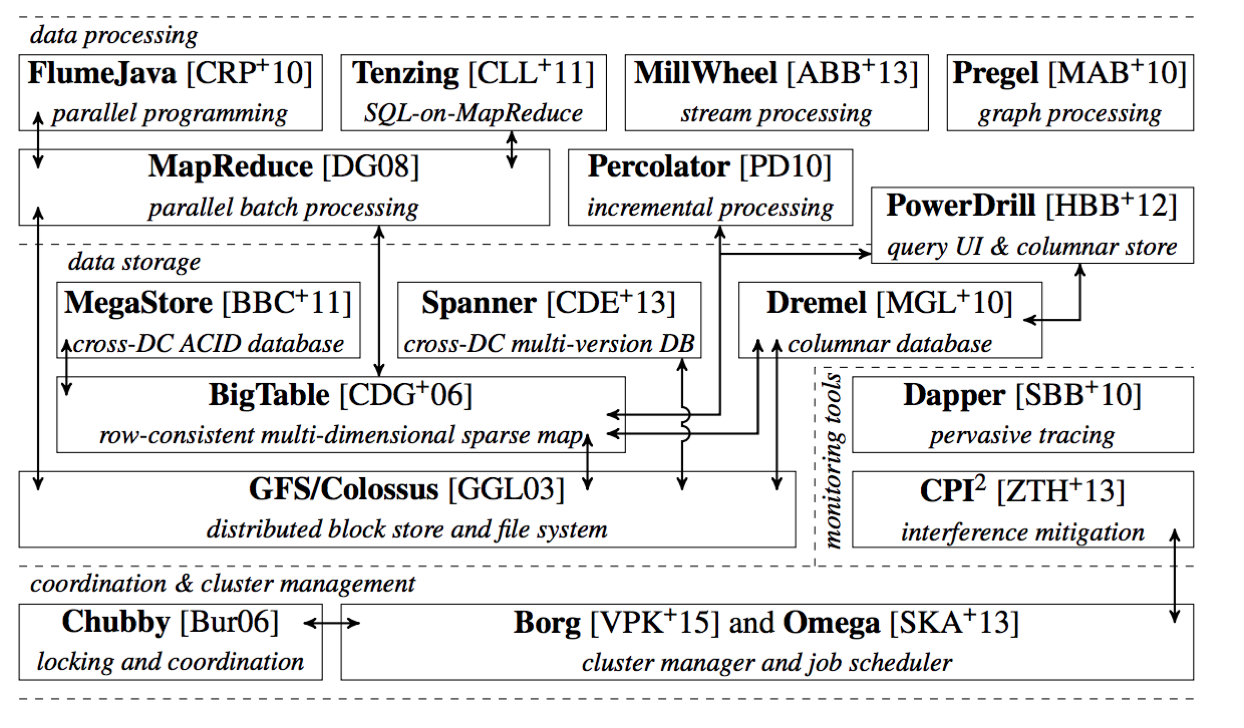
0.1. Kubernetes架构
0.1.1. Kubernetes要解决的问题是什么
编排?调度?容器云?集群管理?
- 这个问题目前没有固定的答案,不同阶段,Kubernetes重点解决的问题不同。
- 但是对于用户来说,希望Kubernetes帮助我们把容器镜像在一个给定的集群上运行起来。(希望Kubernetes提供路由网关、水平扩展、监控、备份、灾难恢复等。)
以上功能,Docker的(Compose+Swarm)或者传统的PaaS就能做到,因此Kubernetes的核心定位不止于此,全局架构如下:
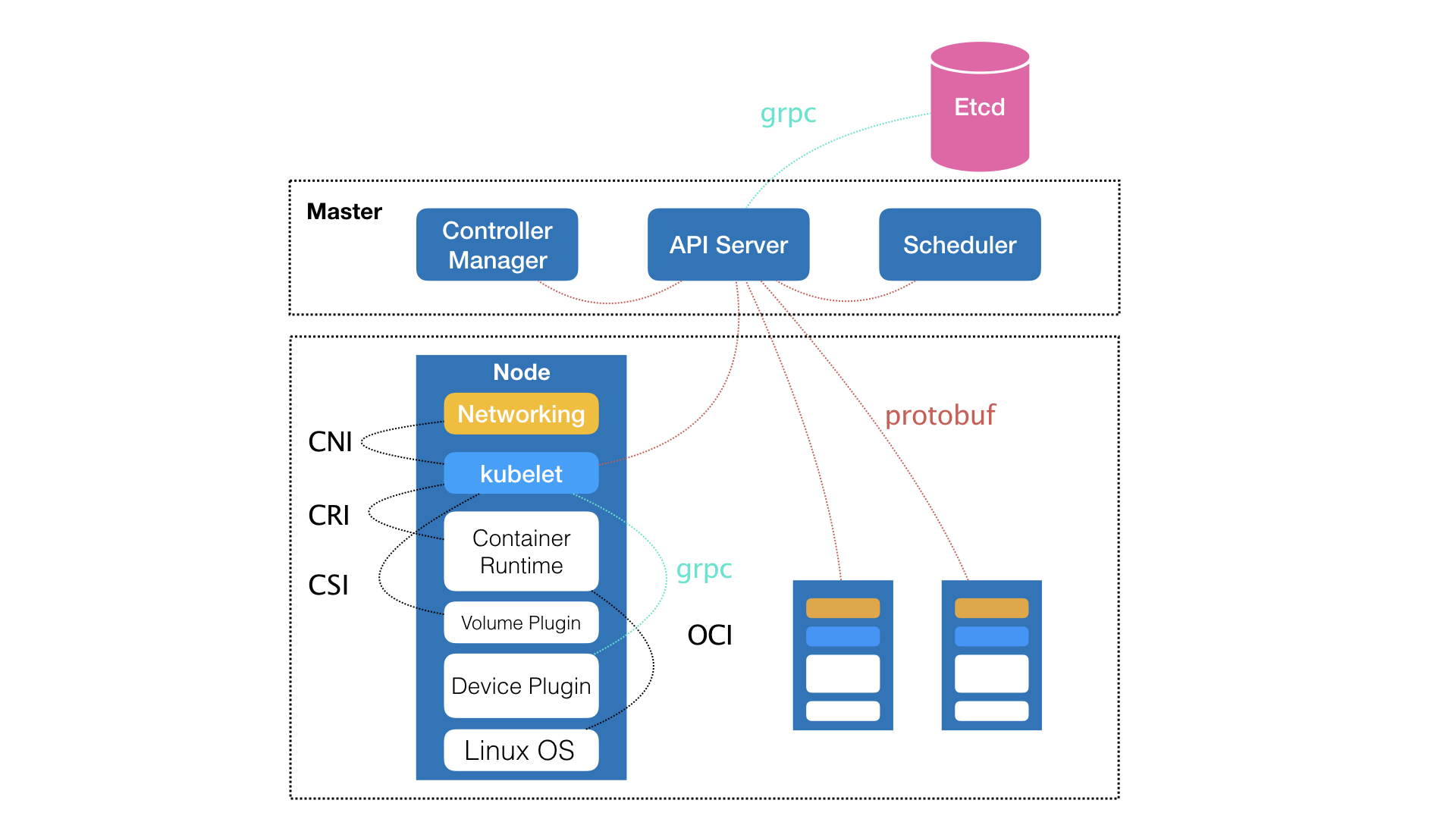
Kubernetes由Master和Node两种节点组成,分别对应这控制节点和计算节点。
0.1.1.1. 控制节点(Master)
出发点:如何编排、管理、调度用户提交的作业。
由三个密切协作的独立组件组合而成:
- 负责API服务的Kube-apiserver
- 负责调度的kube-scheduler
- 负责容器编排的kube-controller-manager
整个集群的持久化数据,由kube-apiserver处理后保存到Etcd中。
0.1.1.2. 计算节点(Node)
- kubelet,与容器运行时(比如Docker项目)交互,这个交互所依赖的是CRI(Container Runtime Interface)的远程调用接口。这个接口定义了容器运行时各项核心操作,比如:启动一个容器需要的所有参数。具体的容器运行时,比如Docker一般通过OCI规范与底层的Linux操作系统进行交互。也就是将CRI请求翻译成对Linux操作系统的调用(操作Linux Namespace和Cgroups等)。
因此,kubernetes项目并不关心部署的是什么容器运行时,使用的什么技术实现,只要容器运行时能够运行标准的容器,就可以通过实现CRI接入到Kubernetes中。
- kubelet通过gRPC协议与Device Plugin插件交互。这个插件是Kubernetes用来管理GPU等宿主机物理设备的主要组件,这个插件是基于Kubernetes项目进行机器学习训练,高性能作业支持等工作必须关注的功能。
- kubelet调用网络插件和存储插件为容器配置网络和持久化存储。这两个插件与kubelet交互的接口:CNI(Container Networking Interface)和CSI(Container Storage Interface)
Kubernetes项目着重要解决的问题是:运行在大规模集群中的各种任务之间,实际上存在着各种各样的关系。这些关系的处理,才是作业编排和管理系统最困难的地方。
如何处理这些关系?利用Docker Swarm 和Compose来处理一些简单依赖关系。
比如,在Compose项目中,可以为两个容器定义一个“link”,Docker项目负责维护这个“link”关系,具体的做法,将两个容器相互访问所需要的IP地址,端口号等信息以环境变量的形式注入,供应用进程使用:
DB_NAME=/web/db
DB_PORT=tcp://172.17.0.5:5432
DB_PORT_5432_TCP=tcp://172.17.0.5:5432
DB_PORT_5432_TCP_PROTO=tcp
DB_PORT_5432_TCP_PORT=5432
DB_PORT_5432_TCP_ADDR=172.17.0.5当容器发生变化时(如镜像更新或者被迁移到其他宿主机),这些环境变量的值会由Docker项目自动更新。
简单的依赖关系,使用以上方法没有问题,但是如果要将所有的依赖关系都处理好,link这种简单的方式就不行了。
所以,Kubernetes项目最主要的设计思想是:从更宏观的角度,以统一的方式来定义任务之间的各种关系,并且为将来支持更多种类的关系保留余地。
0.1.2. Kubernetes对容器常见的“访问”进行了分类
常见的“紧密交互”关系:应用之间需要非常频繁的交互和访问或者通过本地文件进行信息交换。常规环境下,这些应用会被部署在同一台服务器,通过localhost通信,通过本地磁盘交换文件。在Kubernetes中,这些容器会被划分为一个Pod,Pod中的容器共享同一个Network Namespace、同一组数据卷,从而达到高效交换信息的目的。
常规需求,如web服务和数据库之间的访问关系;kubernetes提供了一种叫“Service”的服务。像这样的两个应用,往往故意部署在不同的机器上,从而提高容灾能力。但是对于一个容器来说IP地址是不固定的,那么Web怎么找到数据库容器对应的Pod呢?kubernetes通过给Pod绑定Service,而Service声明的IP地址始终不变。 这个Service主要作用是作为Pod的代理入口,从而代替Pod对外暴露一个固定的网络地址。
这样,Web应用只需要关心数据库Pod的Service的信息,Servie后端真正代理的Pod的IP地址、端口等信息的自动更新、维护,则是kubernetes项目的职责。
围绕Pod为核心,构建出Kubernetes项目的核心功能“全景图”:
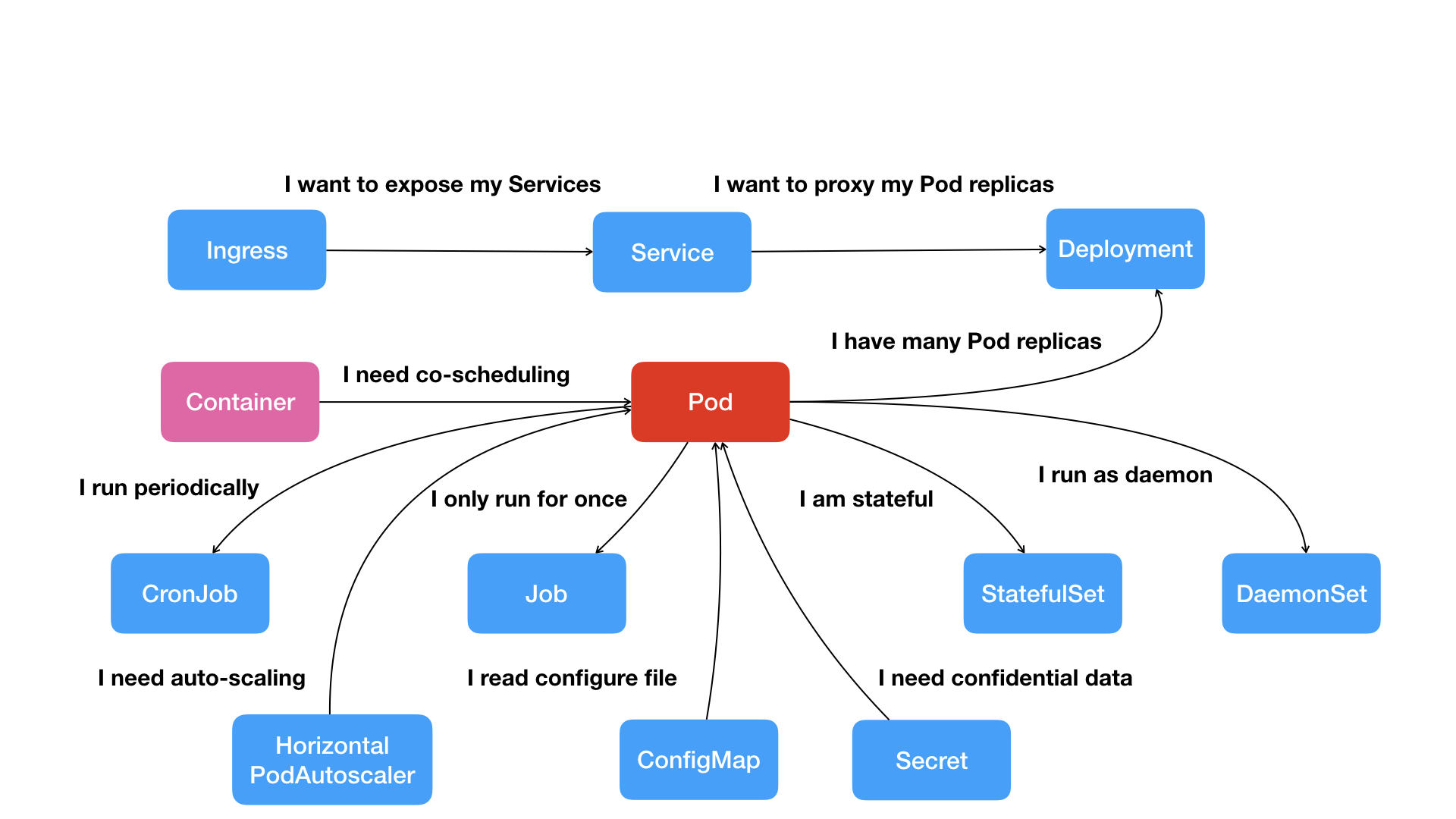
- 不同Pod之间不仅有访问关系,还要求发起时加上授权信息。那么如何实现?使用Secret对象,它其实是一个保存在Etcd里的键值对数据。把授权信息以Secret的方式存在Etcd里,Kubernetes会在指定的Pod启动时,自动把Secret里的数据以Volume的方式挂载到容器里。这样就可以使用授权信息进行容器之间的访问。
0.1.3. Kubernetes对容器的运行形态进行分类
- Pod
- 基于Pod改进的对象: Job,用来描述一次性运行的Pod(比如,大数据任务)。 CronJob,用于描述定时任务。DaemonSet,用来描述每个宿主机上必须且只能运行一个副本的守护进程服务
Kubernetes推崇的做法:
- 通过一个“编排对象”,如pod,job等,来描述你试图管理的应用
- 再定义一些“服务对象”,如Service,Secret,Horizontal Pod Autoscaler等,这些对象会负责具体的平台级功能
这就是所谓的声明式API,这些API对应的“编排对象”和“服务对象”,都是kubernetes项目中的API对象。
0.2. 总结
- 过去很多集群管理项目(Yarn、Mesos、Swarm)所擅长的是把一个容器,按照某种规则,放置在某个最佳节点上运行起来,这种功能称为“调度”。
- Kubernetes擅长的是按照用户意愿和整个系统的规则,完全自动化地处理好容器之间的各种关系,这种功能称为“编排”。
Kubernetes不仅提供了一个编排工具,更重要的是提供了一套基于容器构建分布式系统的基础依赖。