01-隔离与限制
- 0.1. 进程
- 0.2. 隔离与限制
容器技术的兴起源于PaaS技术的普及
Docker项目具有里程碑式的意义
Docker项目通过“容器镜像”,解决了应用打包这个根本性难题
容器本身没有价值,有价值的是“容器编排"。
0.1. 进程
Docker 容器单进程是只有一个进程是可控的(回收与生命周期管理),不是只能运行一个进程,其他运行的进程是不受docker控制的。
数据 + 代码本身的二进制文件,放在磁盘上,就是我们平常说的一个“程序”,也叫可执行镜像。
计算机运行程序的过程:
- 操作系统从“程序”中发现输入数据保存在一个文件中,这些数据被加载到内存中待命
- 操作系统又读取到代码表示的计算指令,指示CPU完成相应操作
- CPU与内存协作进行运算,需要使用寄存器存放数值,内存堆栈保存执行的命令和变量
- 计算机中被打开的文件,各种各样的I/O设备在不断调用中修改自己的状态
“程序”被执行起来,从磁盘上的二进制文件,变成了计算机内存中的数据、寄存器里的值、堆栈中的指令、被打开的文件,以及各种设备状态信息的一个集合。这样一个程序运行起来后的计算机执行环节的总和,就是进程。
进程:
- 静态表现:安安静静待在磁盘上的程序
- 动态表现:计算机里数据和状态的总和
容器技术的核心功能,就是通过约束和修改进程的动态变化,从而为其创造出一个“边界”。
对于Docker等大多数Linux容器来说:
- Cgroups技术是用来制作约束的主要手段
- Namespace技术则是用来修改进程视图的主要方法
0.1.1. Namespace
Namespace其实只是Linux创建新进程的一个可选参数,在Linux系统中创建进程的系统调用是clone(),如下:
int pid = clone(main_function, stack_size, SIGCHLD, NULL);这个系统调用创建一个新的进程,并返回它的进程号pid。
当调用clone()系统调用创建一个新进程时,可以在参数中指定CLONE_NEWPID参数,比如:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);这时,新创建的这个进程会“看到”一个全新的进程空间,这个进程空间里,它的PID是1。但是在宿主机真实的进程空间里,这个进程的PID还是真实的数值。
通过多次执行clone()调用,可以创建多个PID Namespace,每个Namespace里的进程,都认为自己是当前容器的第1号进程,它即看不到宿主机里面真真的进程空间,也看不到其他PID Namespace里的具体情况。
除了PID Namespace,Linux操作系统还通过了Mount、UTS、IPC、Network和User这些Namespace,用来对各种进程上下文进行隔离操作。
比如:
- Mount Namespace:用来让被隔离进程只看到当前Namespace里的挂载点信息
- Network Namespace:用来让被隔离的进程只看到当前Namespace里的网络设备和配置
这是Linux容器最基本的实现原理。容器其实是一种特殊的进程而已。
Docker容器实际上是在创建进程时,指定这个进程所需启用的一组Namespace参数,这样容器就只能看到当前Namespace所限定的资源、文件、设备、状态、配置。对于宿主机以及其他不相关的程序,它们完全看不到。
与真实存在的虚拟机不同,在使用Docker的时候,并没有一个真正的“Docker容器”运行在宿主机里面,Docker项目帮助用户启动的,还是原来的进程,只不过在创建这个进程时,Docker为它们加上了各种各样的Namespace参数。
此时,这些进程就会觉得自己是各自PID Namespace里的第1号进程,只能看到各自Mount Namespace里挂在的目录和文件,只能访问各自Network Namespace里的网络设备,就仿佛运行在一个个“容器”里面,与世隔绝。
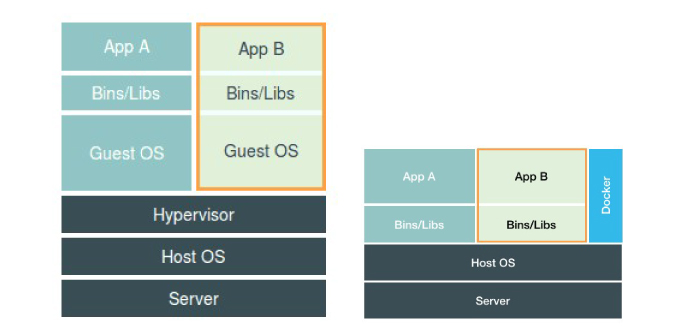
0.2. 隔离与限制
Namespace技术实际上修改了应用进程看待整个计算机的“视图”,即它的“视线”被操作系统做了限制,只能看到某些指定的内容,但是对于宿主机来说,这些被隔离的进程和其他进程没有太大区别。
Docker Engine或者任何容器管理工具,并不对应用进程的隔离环境负责,也不会创建任何实体的“容器”,真正对隔离环境负责的是宿主机操作系统本身。
使用虚拟化技术作为应用沙盒,就必须要由Hypervisor来负责创建虚拟机,并且它里面必须运行一个完整的Guest OS才能执行用户的应用进程。这不可避免地带来了额外的资源消耗和占用。
根据实验,一个运行着Centos的KVM虚拟机启动后,在不作优化的情况下,虚拟机自己需要占用200M左右内存。此外,用户应用运行在虚拟机里面,它对宿主机操作系统的调用就不可避免地要经过虚拟化软件的拦截和处理,这本身又是一层性能损耗,尤其对计算资源、网络和磁盘I/O的损耗非常大。
相比之下,容器化后的用户应用,却依然还是一个宿主机上的普通进程,这就意味着这些因为虚拟化而带来的性能损耗都是不存在的;另一方面,使用Namespace作为隔离手段的容器并不需要单独的Guest OS,这就使得容器额外的资源占用可以忽略不计。
0.2.1. 优势
敏捷和高性能是容器相较于虚拟机最大的优势,也是它能够在PaaS这种更细粒度的资源管理平台上大行其道的重要原因。
0.2.2. 缺点
基于Linux Namespace的隔离机制,隔离的不彻底。
- 容器只是运行在宿主机上的特殊进程,多个容器之间使用的还是同一个宿主机的操作系统和内核。
虽然在容器内通过Mount Namespace单独挂载不同版本的操作系统文件,但是不能改变共享宿主机内核的事实。如果要在Windows宿主机上运行Linux容器,如果要在低版本的Linux宿主机上运行高版本的Linux容器,都是行不通的。
- Linux内核中,有很多资源和对象是不能被Namespace化的,最典型的例子就是时间。
相比于在虚拟机内可以随便折腾的自由度,在容器里部署应用的时候,“什么能做,什么不能做”,就是用户必须考虑的问题。如果容器中的程序使用
settimeofday(2)系统调用修改了时间,整个宿主机的时间都会被随之修改。这显然不符合预期。
- 共享内核的事实,容器给应用暴露出来的攻击面是相当大的,应用“越狱”的难度自然也比虚拟机低得多。
- 尽管在实践中可以使用Seccomp等技术,对容器内部发起的所有系统调用进行过滤和甄别来进行安全加固,但是这种方法因为多了一层对系统调用的过滤,一定会拖累容器的性能。默认情况下,不知道该开启哪些系统调用,禁止哪些系统调用。
基于虚拟化或者独立内核技术的容器实现,可以比较好地在隔离与性能之间作出平衡。
0.3. Cgroups(容器的限制)
虽然容器内的进程被隔离在容器内部,但是在宿主机上依然和其他的进程之间是平等的竞争关系。
虽然表面上被隔离,但是所能够使用的资源(cpu、内存),却是可以随时被宿主机上的其他进程(其他容器)占用的。也可能一个容器把所有资源吃光,这些情况显然都不是一个沙盒应该表现出的合理情况。
Linux Cgroups 主要作用:
- 限制一个进程能够使用的资源上限,包括CPU、内存、磁盘、网络带宽等。
- 对进程设置优先级、审计、将进程挂起和恢复等。
在Linux中,Cgroups给用户暴露出来的操作接口是文件系统,即它以文件系统和目录的方式组织在操作系统的/sys/fs/cgroup路径下。
使用mount命令展示出来如下:
[root@tdc-01 cgroup]# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/net_cls type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls)它输出的是一系列文件系统目录。
在/sys/fs/cgroup下面有很多诸如cpuset、cpu、memory这样的子目录,也叫子系统。
这些都是这台机器当前可以被Cgroups进行限制的资源种类。在子系统对应的资源种类下,就可以看到该类资具体可以被限制的方法。
如对CPU子系统来说,可以看到如下几个配置文件:
[root@tdc-01 cgroup]# ls /sys/fs/cgroup/cpu
cgroup.clone_children cgroup.procs cpuacct.stat cpuacct.usage_percpu cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat machine.slice release_agent tasks
cgroup.event_control cgroup.sane_behavior cpuacct.usage cpu.cfs_period_us cpu.rt_period_us cpu.shares docker notify_on_release system.slice user.slice在这些输出中,如cpu.cfs_period_us,cpu.cfs_quota_us这样的关键词,这两个参数需要组合使用,可以用来限制进程在长度为cpu.cfs_period_us的一段时间内,只能被分配到总量为cpu.cfs_quota_us的CPU时间。
具体要如何使用这样的配置文件呢?
在对应的子系统下创建一个目录,这个目录成为一个“控制组”,系统会在新创建的目录下,自动生成该子系统对应的资源限制文件。
root@ubuntu:/sys/fs/cgroup/cpu$ mkdir container
root@ubuntu:/sys/fs/cgroup/cpu$ ls container/
cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks0.3.1. 例子
执行如下进程,是一个死循环,将CPU占用到100%。
while : ; do : ; done &用top指令查看CPU使用。
top - 14:33:24 up 28 days, 4:10, 1 user, load average: 4.50, 3.57, 3.00
Tasks: 1248 total, 2 running, 1246 sleeping, 0 stopped, 0 zombie
%Cpu(s): 14.4 us, 2.5 sy, 0.0 ni, 82.3 id, 0.5 wa, 0.0 hi, 0.3 si, 0.0 st
KiB Mem : 13174787+total, 43071160 free, 30426240 used, 58250476 buff/cache
KiB Swap: 33554428 total, 33554428 free, 0 used. 99608064 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4517 root 20 0 116372 1556 332 R 100.0 0.0 7:54.13 bash在输出里可以看到目标进程4517,CPU 的使用率已经 100% 了(%Cpu:100.0us)。
查看新创建的控制组中的配置文件,cpu quota没有任何限制(即-1),cpu period默认为100ms(100000us)。
[root@tdc-01 test]# cat /sys/fs/cgroup/cpu/test/cpu.cfs_period_us
100000
[root@tdc-01 test]# cat /sys/fs/cgroup/cpu/test/cpu.cfs_quota_us
-1通过修改这些文件的内容来设置限制。
向cfs_quota文件中写入20ms(20000us)。
echo 20000 > /sys/fs/cgroup/cpu/test/cpu.cfs_quota_us表示在每个100ms的时间里,被改控制组限制的进程只能使用20ms的cpu时间,也就是说这个进程只能使用20%的cpu带宽。
把需要被限制的进程PID写入tasks文件中。
echo 226 > /sys/fs/cgroup/cpu/container/tasks通过top命令再次查看。
Tasks: 1245 total, 2 running, 1243 sleeping, 0 stopped, 0 zombie
%Cpu(s): 7.0 us, 1.4 sy, 0.0 ni, 91.2 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
KiB Mem : 13174787+total, 43206112 free, 30265896 used, 58275868 buff/cache
KiB Swap: 33554428 total, 33554428 free, 0 used. 99768544 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4517 root 20 0 116372 1556 332 R 19.7 0.0 9:05.19 bash从输出可以看到目标进程4517的cpu使用降到了20%。
除了CPU子系统外,Cgroups的每一项子系统都有多个资源限制能力,比如:
- blkio:块设备I/O限制,一般用于磁盘等设备
- cpuset:为进程分配单独的CPU核和对应的内存节点
- memory:为进程设定内存使用的限制
Linux Cgroups是一个子系统目录加上一组资源限制文件的组合,对于Docker等Linux容器项目来说,需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的PID填写到对应控制组的tasks文件中。
在控制组中的资源文件里面填写的值,就是执行docker run时设定的参数,比如:
docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash在这个容器启动后,查看Cgroups文件系统下,CPU子系统中,docker这个控制组的资源限定文件的内容来确认:
cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_quota_us
20000每个容器在docker这个控制组下有对应的容器ID的子目录。
一个正在运行的Docker容器,其实就是一个启用了多个Linux Namespace的应用进程,这个进程能够使用的资源量,受Cgroups配置的限制。
这也是容器技术中一个非常重要的概念:容器是一个“单进程”模型。
由于一个容器的本质就是一个进程,用户的应用进程实际上就是容器里PID=1的进程,也是其他后续创建的所有进程的父进程。这意味着,在一个容器中,没办法同时运行两个不同的应用,除非能事先找到一个公共的PID=1的程序充当两个不同应用的父进程,这也是为什么很多人会用systemd或者supervisord这样的软件来代替应用本身作为容器的启动进程。
0.3.2. 不足
Cgroups对资源的限制能力也有很多不完善的地方,被提及最多的自然是/proc文件系统的问题。
Linux下的
/proc目录存储的是记录当前内核运行状态的一系列特殊文件,用户可以通过访问这些文件,查看系统以及当前正在运行的进程的信息,比如CPU的使用情况和内存占用率等,这些文件也是top指令查看系统信息的主要数据来源。
如果在容器中执行top命令,查看到的是宿主机的cpu和内存数据,而不是当前容器的数据。
造成这个问题的原因就是/proc文件系统并不知道用户通过Cgroups给这个容器做了什么样的资源限制,即/proc文件系统不了解Cgroups限制的存在。
在生产环境中,这个问题必须进行修正,否则应用程序在容器里读取的CPU核数、可用内存等信息都是宿主机上的数据,这会给应用的运行带来非常大的困惑和风险,可以利用lxcfs,提升容器资源可见性。